") PCIe 6.0的新變化與新挑戰(zhàn)
PCIe 6.0的新變化與新挑戰(zhàn)
2022年1月11日,PCI-SIG正式發(fā)布了PCI Express(PCIe) 6.0最終版本1.0,標志著各大IP、芯片廠商可以開始著手設計、開發(fā)自己技術和產品了。從技術上來說,PCIe 6.0是PCIe問世近20年來,變化最大的一次。
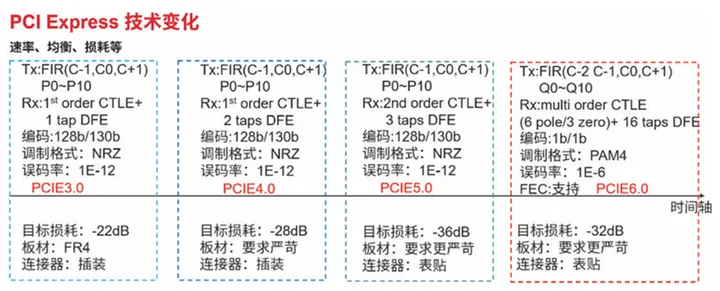
根據PCI-SIG的介紹,PCIe 6.0主要有三大變化:數據傳輸速率從32GT/s翻倍至64GT/s;編碼方式從NRZ 信令模式轉向PAM4信令模式;從傳輸可變大小TLP到固定大小FLIT。
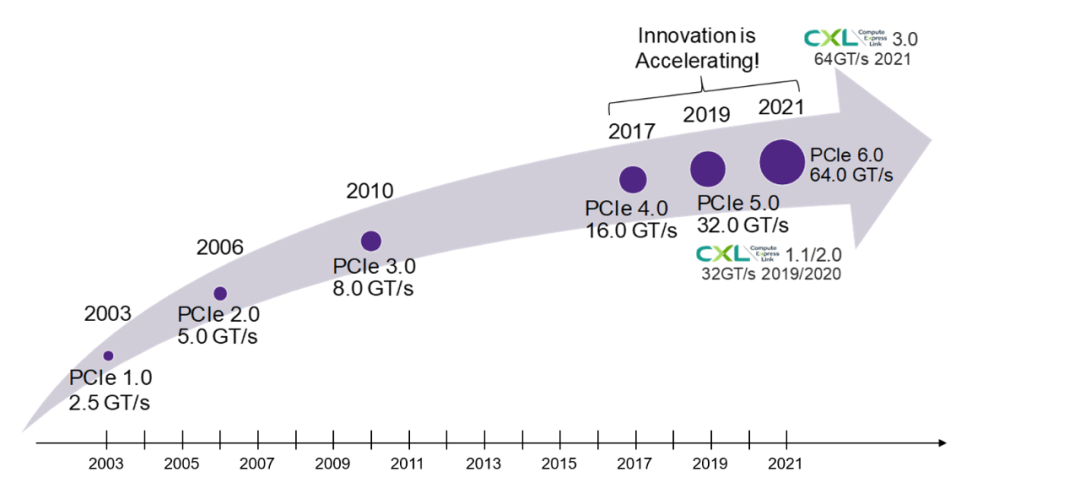
圖:PCIe發(fā)展歷史(來源:新思科技)
PCIe 6.0的新變化
從PCIe的發(fā)展歷史可以看到,在2017年以前,發(fā)展速度相對較慢,三、四年更新一次標準,PCIe 3.0發(fā)布后甚至等了七年才推出PCIe 4.0。但是2017年之后,PCIe標準幾乎每兩年就更新一次,更新速度明顯加快。
這是因為近年來,高性能計算和AI快速發(fā)展,高清視頻和網絡數據迅速膨脹,還有自動駕駛等技術的蓬勃發(fā)展。這些技術的推動,讓數據中心和高性能計算機對高速率和高帶寬的需求越來越大,PCI-SIG也加快了新標準的推出。
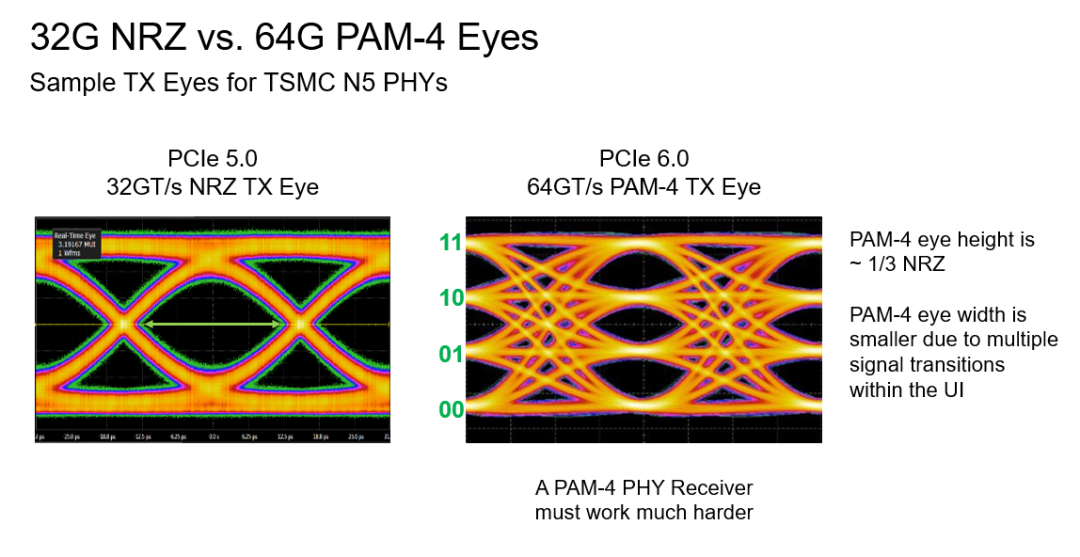
其實前面提到的三大變化當中,前兩個變化是密切相關的,正是因為引入了PAM4編碼方式,才讓PCIe 6.0的數據傳輸速率再次翻倍的。采用PAM4信令后,由于使用4個信號電平,而不是傳統的0/1兩個電平,單個信號就能有四種編碼(00/01/10/11)狀態(tài)。這使得PAM4可以攜帶兩倍于NRZ信令的數據。
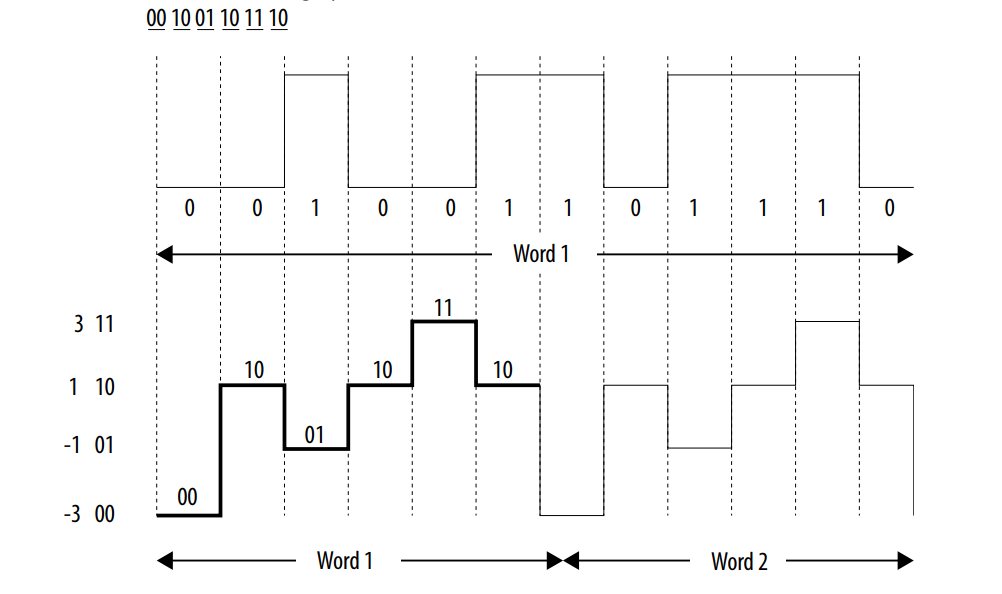
不過,由于PAM4的電平更多,更容易受到噪聲的影響,出現誤碼,因此,如果想讓信號更加可靠的話,就需要輔以輕量級前向糾錯(FEC)和循環(huán)冗余校驗(CRC)方案,以減少誤碼率的增長。
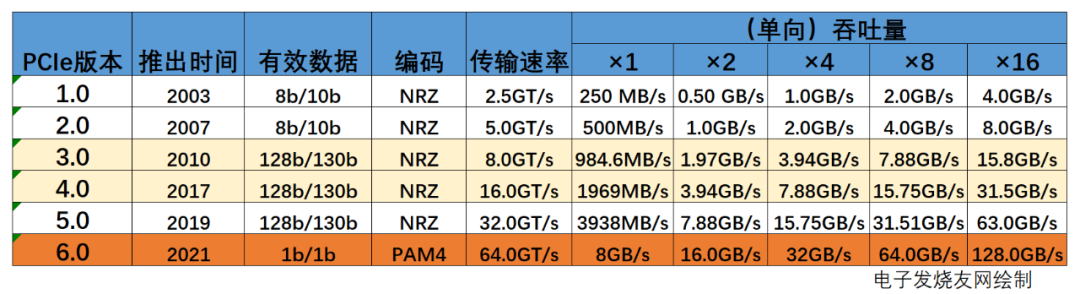
表:歷代PCIe參數對比(數據來源:PCI-SIG)
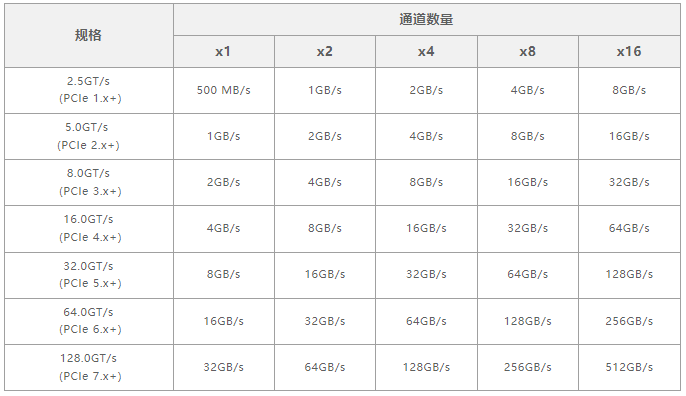
標準每更新一次,傳輸速率就翻倍一次,PCIe6.0原始的傳輸速率為64GT/s,轉換成吞吐量的話,單向吞吐量單條通道(Lane)為:64/8=8GB/s,這里除以8是為了將bit轉換為Byte,也就是說PCIe 6.0 x16的單向吞吐量為128GB/s,雙向為256GB/s。
當然,對于吞吐量其實是有一個計算公式的,以PCIe 3.0協議支持8.0GT/s為例,即每一條通道上支持每秒鐘內傳輸8G個bit,PCIe 3.0的物理層協議中使用的是128b/130b的編碼方案,即每傳輸128個bit,需要發(fā)送130個bit。因此,PCIe 3.0協議的每一條Lane支持的吞吐量就是8×128/130=7,877Gbps=984.6MB/s
流量控制單元(FLIT)編碼方式,也是PCIe 6.0標準最大的變化之一,與物理層的PAM4不同,FLIT編碼用于邏輯層,將數據分解為固定大小的數據包。
PCI-SIG認為 FLIT 編碼在某種意義上也被向后移植以降低鏈路速率非常重要/有用。一旦在鏈路上啟用 FLIT,鏈路將始終保持FLIT 模式,即使鏈路速率協商下降。因此,例如,如果PCIe 6.0 顯卡要從64 GT/s (PCIe 6.0) 速率下降到2.5GT/s (PCIe 1.x) 速率以節(jié)省空閑時的電量,則鏈路本身仍將是在FLIT 模式下運行,而不是回到完整的PCIe 1.x 樣式鏈接。這既簡化了規(guī)范的設計(不必重新協商超出鏈路速率的連接),又允許所有鏈路速率受益于FLIT 的低延遲和低開銷。
隨著在PCIe 6.0中引入新的FLIT模式,TLP和數據層數據包(DLP)包頭格式發(fā)生了變化,應用程序需要理解并正確處理這些變化。例如,對于PCIe 6.0,FLIT包含自己的CRC,因此數據鏈路層數據包(DLLP)和TLP不再需要像在PCIe 5.0和前幾代中那樣的單獨CRC字節(jié)。此外,由于FLIT的大小固定,因此無需使用前幾代(非FLIT模式)中的PHY層成幀令牌。與PCIe 5.0相比,這提高了帶寬效率。
新特性帶來的新挑戰(zhàn)
根據PCI-SIG公布的信息,PCIe 6.0規(guī)范的主要有五大特性:
首先是傳輸速率,從PCIe 5.0的32GT/s擴展至64GT/s;
二是PCIe 6.0采用全新的PAM4,取代PCIe 5.0 NRZ,可以在單個通道、同樣時間內封包更多數據,編碼是一種1b/1b的編碼方案。
三是引入了低延遲前向糾錯(FEC)和相關機制,以改進帶寬效率和可靠性。
四是支持FLIT模式。
五是PCIe 6.0可以兼容前面所有舊版本PCIe架構。
數據傳輸速率的翻倍,從32GT/s NRZ到64GT/s的PAM4信令,信噪比目標將更難達到,因為反射要差3倍。如何讓設計的PCIe 6.0產品更加穩(wěn)健,通道損耗更少,功耗更低,但性能卻不降低,甚至更高呢?
新思科技給出了他們的解決方案,其面向PCIe 6.0的完整IP核解決方案包括了控制器、PHY核驗證IP,可實現PCIe 6.0片上系統(SoC)設計的早期開發(fā)。面向PCIe 6.0的全新DesignWare IP核支持標準規(guī)范的最新功能,其中包括64GT/s PAM-4信號傳輸、FLIT模式和L0p功耗狀態(tài)。該完整IP解決方案可滿足高性能計算、AI和存儲SoC在延遲、帶寬和功耗效率方面不斷提高的要求。
為了實現最低延遲并最大限度地提高所有傳輸規(guī)模的吞吐量,面向PCIe 6.0的DesignWare控制器采用MultiStream架構,可提供相當于Single-Stream設計2倍的性能。該控制器采用1024位架構,可讓開發(fā)者在1GHz時序收斂的條件下實現64GT/s x 16的帶寬。此外,該控制器還可在處理多個數據源以及使用多個虛擬通道時提供最佳流量。為了通過內置驗證計劃、序列和功能覆蓋來加快測試平臺的開發(fā),面向PCIe的VC驗證IP采用了本地SystemsVerilog/UVM架構,只需小量的工作即可完成集成、配置和定制。
其面向PCIe 6.0的DesignWare PHY IP可提供獨特的自適應DSP算法,可優(yōu)化模擬和數字均衡,從而最大限度地提高功耗效率,而不受通道影響。借助正在申請專利的診斷功能,PHY可實現接近零的鏈路關閉時間。面向PCIe 6.0的DesignWare PHY IP感知布局架構可最大限度地減少封裝串擾,并支持針對x16鏈路的密集SoC集成。為基于ADC的架構采用優(yōu)化數據路徑可實現超低延遲。
此外,PCIe 6.0還引入了新電源狀態(tài),稱為L0p 或 LOp。這是一種新的電源狀態(tài),能夠以非破壞性方式為正常工作的鏈路節(jié)省電源。舉例來講,此電源狀態(tài)下的 x4 鏈路可以確保只有一個通道工作,而其他三個通道進入低功率流。與任何其他低功耗狀態(tài)一樣,退出這種低功耗狀態(tài)的延遲是一個值得關注的關鍵參數。
這種新的低功耗模式是對稱的,這意味著TX和RX一起縮放,并且支持FLIT模式的重定時器也支持這種模式。在處于L0p期間空閑通道的PHY功耗預計與關閉通道時的功耗相近。
結語
雖然現在主流的應用還在PCIe3.0和PCIe 4.0,但我們看到在有些數據中心,以及新的GPU、CPU,或加速器開始采用PCIe 5.0了。PCIe 6.0帶來的新特性,包括64GT/s的數據速率,采用具有吞吐量和延遲優(yōu)勢的 FLIT,以及新的低功耗狀態(tài)L0p,實現了真正的帶寬擴展來降低功耗,必然會給業(yè)界帶來新的體驗。
原文標題:解密PCle IP方案,讓SoC集成更簡單
文章出處:【微信公眾號:電子發(fā)燒友網】歡迎添加關注!文章轉載請注明出處。
審核編輯:湯梓紅
-
芯片
+關注
關注
456文章
50950瀏覽量
424758 -
IP
+關注
關注
5文章
1712瀏覽量
149660 -
pcle
+關注
關注
0文章
29瀏覽量
5769
原文標題:解密PCle IP方案,讓SoC集成更簡單
文章出處:【微信號:elecfans,微信公眾號:電子發(fā)燒友網】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
相關推薦
PCIe 6.0 互操作性PHY驗證測試方案
GPT誕生兩周年,AIPC為連接器帶來什么新變化?
PCIe的最新發(fā)展趨勢
PCIe 4.0與PCIe 3.0的性能對比
CTA認證最新變化 :北三短報文設備進網許可、NSA可選入網

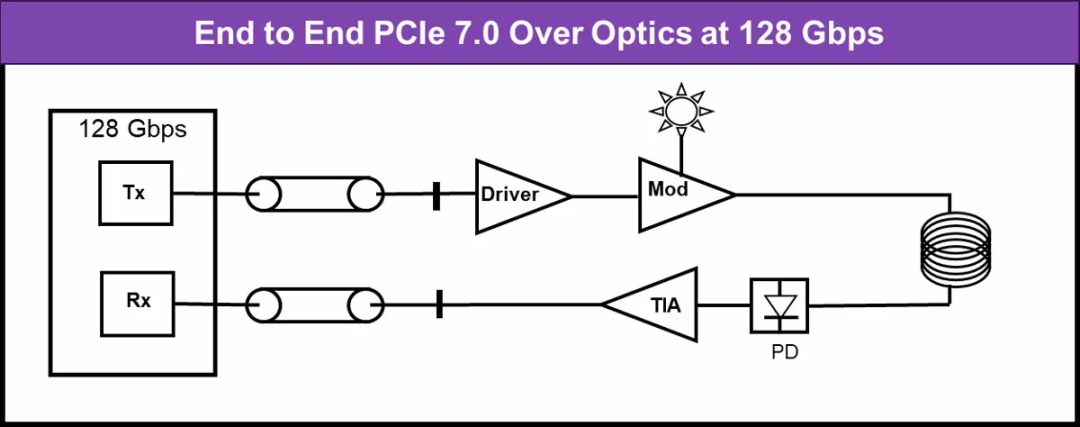
PCIe光傳輸的優(yōu)勢與挑戰(zhàn)

pcie4.0和pcie3.0接口兼容嗎
如何簡化PCIe 6.0交換機的設計
FPGA的PCIE接口應用需要注意哪些問題
PCIe 7.0規(guī)范何時最終確定?
FMS2023固態(tài)存儲技術前沿:PCIe 5.0、PCIe 6.0和大容量SSD的挑戰(zhàn)與發(fā)展
下一代PCIe5.0 /6.0技術熱潮趨勢與測試挑戰(zhàn)
PCIe 6.0元年,AI與HPC迎來新速度
核芯互聯推出支持PCIe Gen 6的時鐘發(fā)生器CLG440





 工商網監(jiān)
工商網監(jiān)
評論