") 通過利用機器學習模型破譯古籍
通過利用機器學習模型破譯古籍
為了揭示過去的秘密,世界各地的歷史學者花費畢生精力翻譯古代手稿。圣母大學的一個研究小組希望幫助這項任務,用一種新開發(fā)的機器學習模型來翻譯和記錄幾百年前的手寫文檔。
利用圣加爾修道院圖書館的數(shù)字化手稿和一個考慮到人類感知的機器學習模型 study 在深度學習轉錄能力方面有顯著提高。
“我們正在處理歷史文件,這些文件的書寫風格早已過時,可以追溯到幾個世紀以前,并且使用拉丁語等語言,而拉丁語已經(jīng)很少使用了。你可以得到這些材料的美麗照片,但我們已經(jīng)著手做的是以一種模仿專家讀者眼睛對頁面感知的方式自動轉錄,并提供快速、可搜索的文本閱讀,”圣母大學副教授、資深作者沃爾特·舍勒在新聞稿中說。
圣加爾修道院圖書館建于 719 年,是世界上最古老、最豐富的圖書館藏品之一。該圖書館藏有大約 160000 卷書和 2000 份手稿,可追溯到八世紀。在羊皮紙上用現(xiàn)在很少使用的語言手工書寫,這些材料中的許多尚未被閱讀——這是一筆潛在的歷史檔案財富,等待發(fā)掘。
機器學習方法能夠自動轉錄這些類型的歷史文件已經(jīng)在工作中,但挑戰(zhàn)仍然存在。
到目前為止,大型數(shù)據(jù)集對于提高這些語言模型的性能是必不可少的。由于可供查閱的書籍數(shù)量巨大,這項工作需要時間,并且需要相對較少的專家學者進行注釋。缺少知識,如從未編纂過的中世紀拉丁語詞典,構成了更大的障礙。
該團隊將傳統(tǒng)的機器學習方法與研究物理世界和人類行為之間關系的視覺心理物理學相結合,以創(chuàng)建更多信息豐富的注釋。在這種情況下,他們在處理古代文本時將人類視覺測量納入神經(jīng)網(wǎng)絡的訓練過程。
“這是機器學習中通常不使用的策略。我們通過這些心理物理測量來標記數(shù)據(jù),這些測量直接來自于通過行為測量對感知進行的心理學研究。然后,我們通知網(wǎng)絡在感知這些角色方面的常見困難,并可以根據(jù)這些測量結果進行糾正,” Scheirer 說。
為了訓練、驗證和測試這些模型,研究人員使用了一套來自圣加爾的可追溯到九世紀的數(shù)字化手寫拉丁手稿。他們要求專家閱讀并將文本行中的手動抄本輸入定制的軟件中。測量每次抄寫的時間,可以洞察單詞、字符或段落的難度。根據(jù)作者的說法,這些數(shù)據(jù)有助于減少算法中的錯誤,并提供更真實的讀數(shù)。
所有的實驗都是使用 cuDNN-accelerated PyTorch 深度學習框架和 GPU 。“如果沒有 NVIDIA 硬件和軟件,我們肯定不可能完成我們所做的事情。
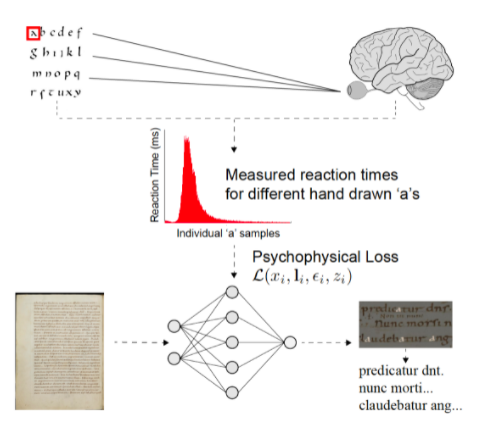
該研究引入了一種新的深度學習損失公式,該公式結合了人類視覺測量,可應用于手寫文檔轉錄的不同處理管道。信貸: Scheirer 等人/ IEEE
團隊仍在努力改進某些方面。損壞和不完整的文檔以及插圖和縮寫對模型提出了特殊的挑戰(zhàn)。
“由于互聯(lián)網(wǎng)規(guī)模的數(shù)據(jù)和 GPU 硬件,人工智能達到了拐點,這將使文化遺產(chǎn)和人文學科與其他領域一樣受益。我們只是初步了解我們可以對這個項目做些什么。
關于作者
Michelle Horton 是 NVIDIA 的高級開發(fā)人員通信經(jīng)理,擁有通信經(jīng)理和科學作家的背景。她在 NVIDIA 為開發(fā)者博客撰文,重點介紹了開發(fā)者使用 NVIDIA 技術的多種方式。
審核編輯:郭婷
-
gpu
+關注
關注
28文章
4753瀏覽量
129067 -
互聯(lián)網(wǎng)
+關注
關注
54文章
11168瀏覽量
103484 -
機器學習
+關注
關注
66文章
8425瀏覽量
132772
發(fā)布評論請先 登錄
相關推薦
【「具身智能機器人系統(tǒng)」閱讀體驗】2.具身智能機器人大模型
《具身智能機器人系統(tǒng)》第7-9章閱讀心得之具身智能機器人與大模型
什么是機器學習?通過機器學習方法能解決哪些問題?

AI大模型與深度學習的關系
AI大模型與傳統(tǒng)機器學習的區(qū)別
構建語音控制機器人 - 線性模型和機器學習
【《時間序列與機器學習》閱讀體驗】+ 時間序列的信息提取
【《大語言模型應用指南》閱讀體驗】+ 基礎知識學習
【《大語言模型應用指南》閱讀體驗】+ 基礎篇
Al大模型機器人
人工神經(jīng)網(wǎng)絡與傳統(tǒng)機器學習模型的區(qū)別
深度學習模型訓練過程詳解
【大語言模型:原理與工程實踐】揭開大語言模型的面紗
深入探討機器學習的可視化技術






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論