 簡述ElasticSearch的實現
簡述ElasticSearch的實現
1.近實時搜索
1.1 實時與近實時
實時搜索(Real-time Search)很好理解,對于一個數據庫系統,執行插入以后立刻就能搜索到剛剛插入到數據。而近實時(Near Real-time),所謂“近”也就是說比實時要慢一點點。
1.2 近實時的挑戰
對于一個單機系統來說,這也并不容易實現,因為還要保證數據的持久化,還要利用緩存等技術加快數據的訪問(注:這里不討論內存計算系統)。對于ElasticSearch這樣一個分布式系統,保證持久化的同時,還要初始化好用于全文檢索的內部數據結構,做到近實時的難度可想而知。而這就是ElasticSearch大獲成功的地方,也正是本文所要學習的主題:ElasticSearch是如何解決這些實現近實時搜索的難題的。
2.ElasticSearch的實現
2.1 不可變的數據結構
有經驗的程序員一定知道,在做并發編程時,控制可變數據的并發訪問是個難題。古往今來,各種粗細粒度的鎖,信號量,Actor模型等概念層出不窮。而另一流派函數式編程更為徹底,尤其是純函數式比如Haskell,用不可變數據來徹底解決這個問題。
在ElasticSearch這樣主要服務全文檢索的系統中,Inverted Index是核心數據結構。這里簡單說一句,Inverted Index本質上一組document中term的各種統計信息,比如最重要的詞頻,以及其他許多統計信息,比如文檔長度,詞序等等。要做到近實時搜索,就要保證新數據能快速構建,已有數據能被高速訪問。解決問題的關鍵就在于Inverted Index的不可變性,這也是ElasticSearch底層依賴的高性能Lucene的根本奧秘。
2.2 從不可變到可變
所以當用戶向ElasticSearch中的數據庫插入一組document后,底層Lucene構建出一個不可變的Inverted Index。可我們知道,一個數據庫不可能是靜態的,當用戶再次插入新數據時,Lucene該怎樣處理呢?答案就是增量保存和邏輯標記。
所謂增量保存就是為新數據構建一個新的不可變的Inverted Index,當執行搜索時,要合并每個Inverted Index中的統計信息得到最終結果。保存新數據的問題解決了,而邏輯標記就是解決更新和刪除的。Lucene為每個Inverted Index都額外維護一個del數據結構,當執行刪除時,只需在del中標記,這樣最終結果就會排出掉刪除掉document。同理,更新時也是給老數據做標記,新document會保存在新的Inverted Index中,最終結果會使用最新版本數據的統計信息。在Lucene中,每個Inverted Index叫做Segment,而管理這些Segment的叫做Index。
ElasticSearch中一個數據庫被稱為Index,每個Index可以在創建時指定要劃分為幾份,每一份叫做Shard。Shard會被ElasticSearch分配到不同結點,運行中還會根據壓力做Rebalance。這個Shard其實就是Lucene中的Index。由于不同層級上名字的重復,初學時很容易混淆。
這種思想其實并非獨創,在其他一些高級數據結構中也能找到它的影子。如果沒記錯的話,一個經典的例子就是LSM樹:https://en.m.wikipedia.org/wiki/Log-structured_merge-tree。
2.3 分布式數據存儲
對于分布式的數據存儲,ElasticSearch采取了經典的做法,對數據進行分片和路由,這里每個分片Shard就是一個Lucene數據庫Index。對于有副本replica的Shard,ElasticSearch操作完primary后,再去同步到replica。
2.4 挑戰磁盤I/O
現在我們已經可以高效地維護全文檢索的數據結構,也遵循經典做法解決了分布式數據存儲。可就像前面提到的,還有個挑戰就是磁盤讀寫的巨大開銷。Lucene的做法是,每個Segment在文件系統Cache中構建起來就可以被訪問,同步到磁盤的fsync之后才會執行。Lucene的Index內部的Commit Point會記住哪些Segment還未同步。ElasticSearch默認每隔1秒會用Buffer中的document新建一個Segment,這個操作叫做refresh。正因為這1秒鐘的間隔,ElasticSearch支持的是近實時而非實時。
一個很自然的問題就是每秒鐘都會新建一個Segment,那Lucene Index中的Segment個數豈不是很容易就爆炸了。每個Segment都是一個物理文件,操作系統中打開文件的句柄個數是有限的,而且即便不考慮上限,過多Segment也會拖慢搜索,因為前面講過一次搜索的最終結果是要合并所有Segment中的統計信息的。
ElasticSearch的做法是維護一個后臺線程去做Merge,Merge的過程中不僅將多個小Segment合并成大的,同時還會排除掉刪除或修改的文件的老版本,最終修改Commit Point排除掉老的Segment,這樣那些“垃圾”document就徹底被刪除了。得益于Segment的不可變性,后臺進程Merge時并不會影響數據插入和搜索的性能。
2.5 保證數據不丟失
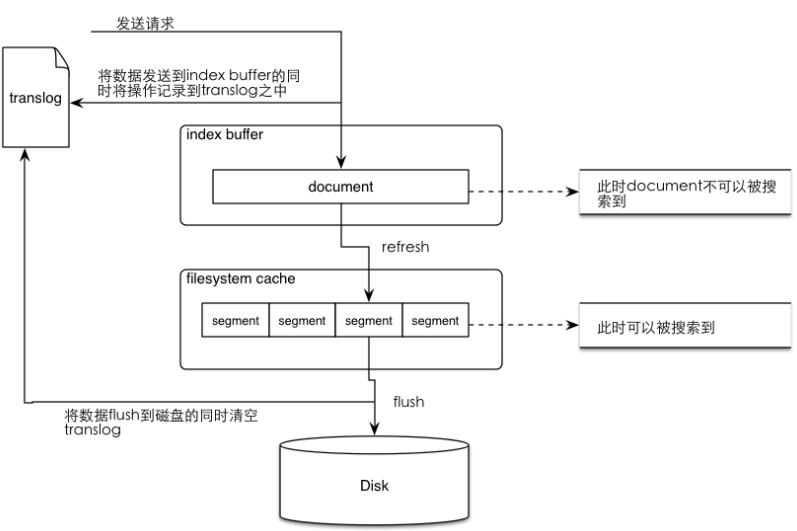
一個可以預料到的問題就是,如果當前結點上的ElasticSearch進程意外中止,那Buffer中等待處理的document和未同步到磁盤的Segment中的數據都會丟失。為了避免這一點,ElasticSearch引入了傳統數據庫中所謂的Write-Ahead Log(WAL)日志,ElasticSearch為其起名為translog。每次插入Buffer時,都會同時寫入translog。下面的圖示清晰地展示ElasticSearch是如何與Lucene配合的。
當創建新Segment時,Buffer清空,但translog會一直保留到Segment同步到磁盤才會清空。所以當ElasticSearch重啟時,先根據Commit Point將所有之前已經commit到磁盤的Segment恢復到Cache,然后再重放(replay)translog中的所有操作。默認每30分鐘或者translog很大時,ElasticSearch做一次full commit,即flush操作。
繼續刨根問底,translog保證了Buffer和Segment的安全,誰來保證它的安全呢?默認情況下,translog每5秒鐘會同步到磁盤,也就是說我們至多會丟失5秒到數據。因為translog只是原始的請求document,所以這里的寫磁盤開銷是遠小于Segment的一次commit的。
3.題外話:如何深入學習ElasticSearch
以本文為例,談一談如何學習ElasticSearch。在有了一些分布式系統和開發經驗后,像本文2.3和2.5節是完全可以跳過的。前者是分布式系統的通用做法,而后者則早已存在于傳統數據庫中。要掌握ElasticSearch,基本用法和系統命令是一方面,而設計中的精華往往在前文2.1和2.2中。光理解了設計還不行,就像前面說過的,思想可能流傳已久,但做出來東西的質量則可能千差萬別。“天下大事,必做于細”,實現中的精髓只能在源代碼中體會。
其實這種方法在另一篇文章里也提到過,就是學一門編程語言時也是要抓住它的精髓,而不是每門語言都花很多時間去學基本語法,而沒有精力去掌握精華,最終迷失了。在此再次強調一下,自己也引以為戒。
編輯:jq
-
數據
+關注
關注
8文章
7134瀏覽量
89546 -
編程
+關注
關注
88文章
3637瀏覽量
93965 -
函數
+關注
關注
3文章
4345瀏覽量
62953 -
單機
+關注
關注
0文章
16瀏覽量
6296
原文標題:ElasticSearch近實時搜索的實現
文章出處:【微信號:magedu-Linux,微信公眾號:馬哥Linux運維】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
如何在Linux環境下高效安裝部署和配置Elasticsearch
在華為云上通過 Docker 容器部署 Elasticsearch 并進行性能評測
構建高效搜索解決方案,Elasticsearch & Kibana 的完美結合
企業如何用ELK技術棧實現數據流量爆炸式增長
Elasticsearch 再次開源


氣壓制動系統工作原理簡述
軟件系統的數據檢索設計
統一日志數據流圖
簡述拉曼散射效應的實現過程
簡述開關電源兩類漏電流的區別
簡述四種基本觸發器及其功能

Rust編寫的首個Postgres基礎Elasticsearch開源替代品問世






 工商網監
工商網監
評論