 超實用的任務優化與斷點執行方案
超實用的任務優化與斷點執行方案
前言
隨著大數據時代的快速發展,企業每天需要存儲、計算、分析數以萬億的數據,同時還要確保分析的數據具備及時性、準確性和完整性。面對如此龐大的數據體系,ETL工程師(數據分析師)如何能高效、準確地進行計算并供業務方使用,就成了一個難題。
作為一家數據智能公司,個推在大數據計算領域沉淀了豐富的經驗。本篇文章將對大數據離線計算過程中出現的任務緩慢和任務中斷這兩大痛點問題提出解決思路,期望讀者能夠有所收獲。
一、任務緩慢
“任務執行緩慢”通常是指任務的執行時間超過10個小時,且不能滿足數據使用方對數據及時性的要求。比如業務方需早上就能夠查看T-1的數據,但是因為任務延時,業務方只能等到下午或者傍晚才能查詢、瀏覽T-1的數據,從而無法及時發現經營問題、進行高效決策。因此,對緩慢任務進行優化成了ETL工程師必不可少的一項工作。
在長期的大數據實踐中,我們發現,緩慢任務往往具有一定的共性。只要我們能找到問題所在,并對癥下藥,就能將任務執行時間大大縮短。個推將任務執行緩慢的常見問題歸納為以下四點:邏輯冗余,數據傾斜、大表復用,慢執行器。接下來會對每個痛點進行詳細闡述。
1、邏輯冗余
“邏輯冗余”往往是因為ETL工程師進行數據處理和計算時更關注處理結果是否滿足預期,而未深入考慮是否存在更高效的處理方式,導致原本可通過簡單邏輯進行處理的任務,在實際中卻使用了復雜邏輯來執行。
減少“邏輯冗余”更多地依賴開發者經驗的積累和邏輯思維以及代碼能力的提升。這里分享一些高級函數,希望能夠幫助開發者進一步提升數據處理效率。
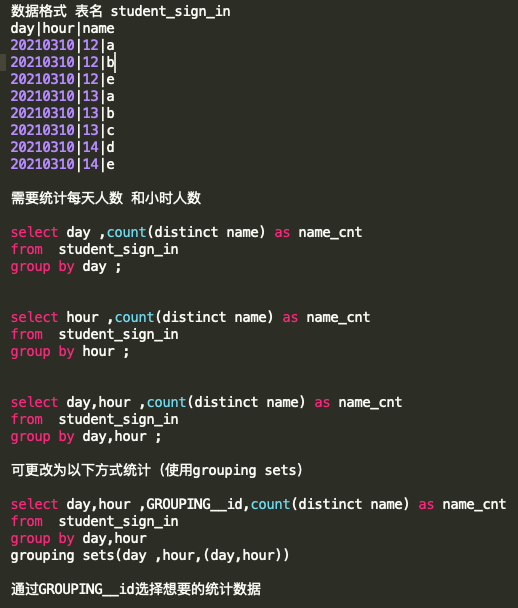
Grouping sets
分組統計函數。這個函數可以實現在一段SQL中輸出不同維度的統計數據,避免出現執行多段SQL的情況,具體寫法如下:
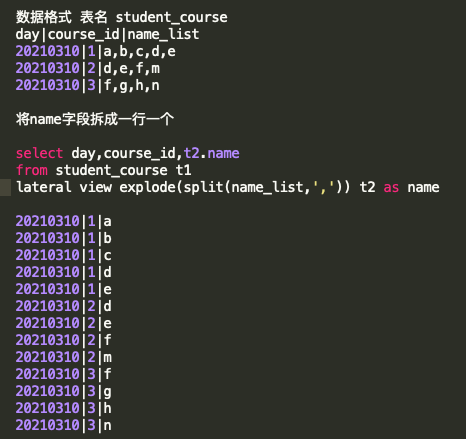
Lateral view explode()
一行轉多行函數。這個函數只能處理array格式數據,需要配合split()函數使用,具體寫法如下:
還有其他一些函數、函數名及功能如下,具體用法需要讀者自行查詢(可登錄hive官網查詢函數大全):
find_in_set() :查找特定字符串在指定字符串中的位置
get_json_object():從json串中抽取指定數據
regexp_extract():抽取符合正則表達的指定字符
regexp_replace() :替換符合正則替換指定字符
reverse():字符串反轉
2、數據傾斜
“數據傾斜”是指在MR計算的過程中某些Map job需要處理的數據量太大、耗時太長,從而導致整個進程長時間無法結束,任務處理進度長時間卡在99%的現象。
針對數據傾斜的情況,開發者們可通過代碼層面進行修改,具體操作如下:
使用group by方式替換count(distinct id ) 方式進行去重統計
進行大小表關聯時使用mapjoin操作或子查詢操作,來替換 join操作
group by出現傾斜需要將分組字段值隨機切分成隨機值+原始值
join操作避免出現笛卡爾積,即關聯字段不要出現大量重復
3、大表復用
“大表復用”,是指對上億甚至幾十億的大表數據進行重復遍歷之后得到類似的結果。避免大表復用就要求ETL工程師進行系統化的思考,能夠通過低頻的遍歷將幾十億的大表數據瘦身到可重復使用的中間小表,且同時支持后續的計算。
因此,工程師需要在工程開發之初就將整體的工程結構考慮進去,并且堅持“大表僅使用一次”的原則,以提升整個工程的執行效率。
這里介紹一個實戰中的例子,供讀者參考:
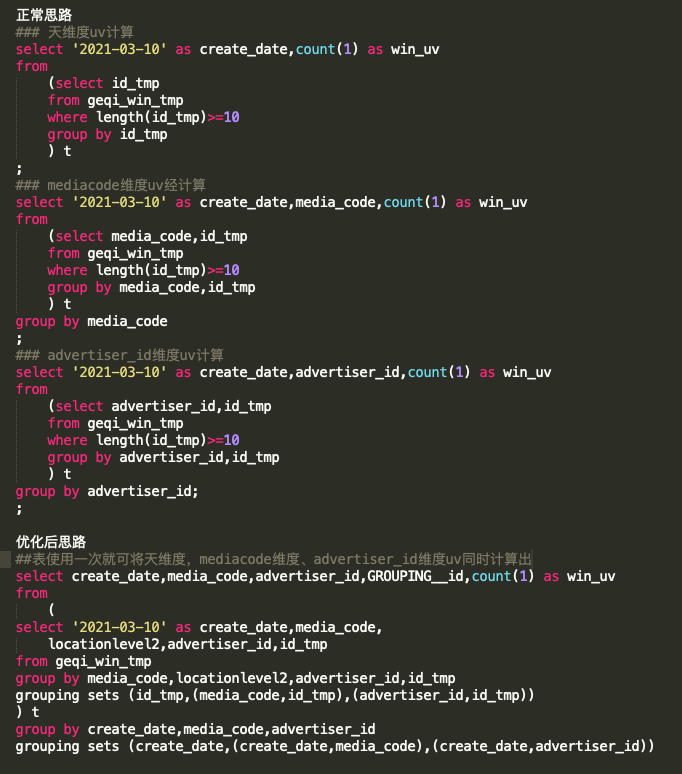
geqi_win_tmp表中數據:5000萬
4、慢執行器
“慢執行器”是指數據體量過于龐大時,Hive的底層計算邏輯已經無法快速遍歷單一分區中的所有數據。
由于在同等資源的情況下,Spark進行數據遍歷的效率遠高于MapReduce;且Spark任務對資源的搶占程度遠大于MapReduce任務,可在短時間內占用大量資源高效完成任務,之后快速釋放資源,以提高整個集群任務的執行效率。
因此,針對該情況,開發者可考慮使用pyspark等更為高效的計算引擎進行數據的快速遍歷。同時,開發者也需要有意識地加強思維訓練,養成良好的開發習慣,在面對海量數據時探索更快、更準、更體系化的計算和處理方式。
二、任務中斷
因為各種各樣的原因,線上任務經常會出現被kill掉然后重新執行的情況。任務重新執行會嚴重浪費集群資源,同時使得數據計算結果延遲從而影響到業務方的數據應用。如何避免這種現象的發生呢?個推是這樣解決該問題的。
個推的定時任務是基于Azkaban調度系統開發的,個推的數據分析師主要使用shell、HSQL、MySQL、Pypark四種代碼進行數據處理,將原始日志清洗、計算,然后生成公共層、報表層數據,最終供業務方使用。
因此個推需要設定四種代碼執行器以支持腳本中對不同類型代碼的處理。這里主要對其中的三個核心內容進行介紹:代碼塊輸入、執行函數以及循環器。
1、代碼塊輸入
一般情況下,腳本中的shell、HSQL、MySQL、pypark代碼會按照順序直接執行,不能選擇性執行。在實踐中,我們將代碼塊以字符串的方式賦值給shell中的變量,并在字符串的開頭標記是何種類型的代碼,代碼執行到具體步驟時只有賦值操作,不會解析執行,具體如下:
? 執行HSQL代碼塊
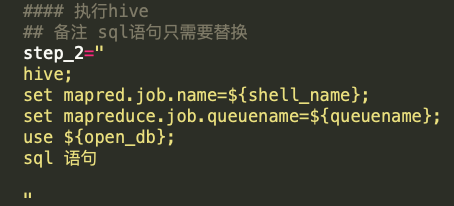
? 執行shell代碼塊
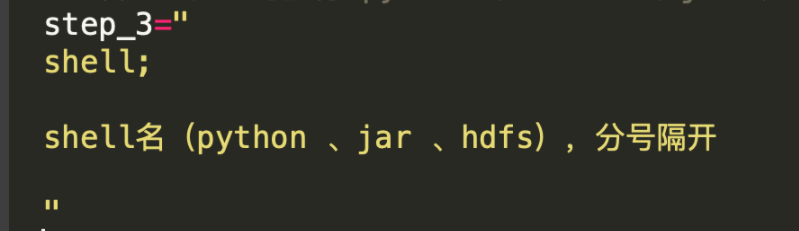
? 執行mysql代碼塊
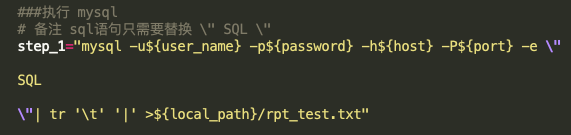
? 執行pyspark代碼塊
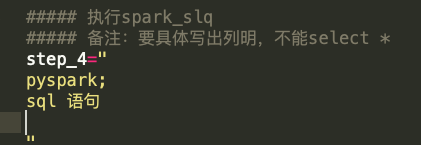
如此,就實現了將不同的代碼放入對應的step_n中。在后續的執行器中這些代碼能夠直接執行,開發者只需要關心邏輯處理即可。
2、執行函數
執行函數是對shell中變量step_n當中的字符串進行代碼解析并執行。不同類型的代碼塊解析方式不同,因此需要定義不同的執行函數。函數一般單獨放在整個工程的配置文件中,通過source的方式調用,具體函數定義如下:
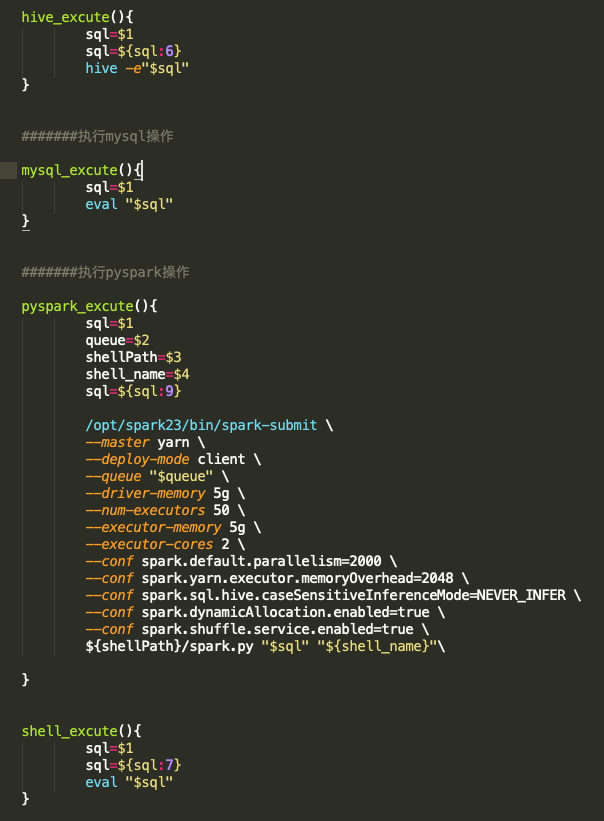
Hive、MySQL以及shell的執行函數比較簡單,通過hive-e 或者eval的方式就可以直接執行。pyspark需要配置相應的隊列、路徑、參數等,還需要在工程中增spark.py文件才能執行,此處不做贅述。
3、循環器
循環器是斷點執行功能的核心內容,是步驟的控制器。循環器通過判斷shell變量名確定需要執行哪一步,通過判斷變量中字符串內容確定使用何種函數解析代碼并執行。
下圖是參考案例,代碼如下:
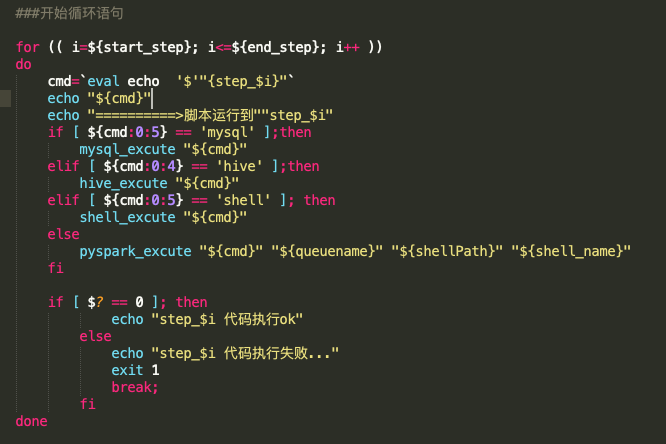
開發者需要在腳本的開始定義好整個代碼的結束步驟,以確保循環器正常運行;同時,可將開始步驟當作腳本參數傳入,這樣就很好地實現了任務的斷點執行功能。
總結
ETL工程中的任務緩慢和任務中斷問題是每個大數據工程師都需要面對和解決的。本文基于個推大數據實踐,針對任務緩慢和任務中斷問題提出了相應解決思路和方案,希望能夠幫助讀者在任務優化以及ETL工程開發方面擴寬思路,提高任務執行效率,同時降低任務維護的人力成本和機器成本。
編輯:jq
-
存儲
+關注
關注
13文章
4317瀏覽量
85872 -
SQL
+關注
關注
1文章
764瀏覽量
44153 -
ETL
+關注
關注
0文章
20瀏覽量
9412 -
函數
+關注
關注
3文章
4332瀏覽量
62654 -
大數據
+關注
關注
64文章
8893瀏覽量
137462
原文標題:ETL工程師必看!超實用的任務優化與斷點執行方案
文章出處:【微信號:AndroidPush,微信公眾號:Android編程精選】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
斷點續傳工業網關有什么應用場景
廣州盈致WMS系統:優化倉儲管理的智能化解決方案
網關斷點續傳可以實現什么功能
LED燈帶斷點續傳是什么意思
TC2XX/3XX多核斷點設置無效的原因?
任務編譯器:斷點后進入代碼不起作用,為什么?
ESP32C3任務執行一段時間,會出現任務不運行的問題,為什么?
用的cube生成的freertos工程,串口和任務通過郵箱通訊,結果任務反應很慢是怎么回事?
為什么CubeMX設計的FreeRTOS工程只能正常運行3個任務?
超融合架構解決方案
請問GTM MCS每個通道任務如何執行?
工業智能網關斷網后如何實現斷點續傳





 工商網監
工商網監
評論