 Linux內核Page Cache和Buffer Cache兩類緩存的作用及關系如何
Linux內核Page Cache和Buffer Cache兩類緩存的作用及關系如何
[注: 轉載自今日頭條號“閃念基因”]
在我們進行數據持久化,對文件內容進行落盤處理時,我們時常會使用fsync操作,該操作會將文件關聯的臟頁(dirty page)數據(實際文件內容及元數據信息)一同寫回磁盤。這里提到的臟頁(dirty page)即為頁緩存(page cache)。塊緩存(buffer cache),則是內核為了加速對底層存儲介質的訪問速度,而構建的一層緩存。他緩存部分磁盤數據,當有磁盤讀取請求時,會首先查看塊緩存中是否有對應的數據,如果有的話,則直接將對應數據返回,從而減少對磁盤的訪問。兩層緩存各有自己的緩存目標,我好奇的是,這兩者到底是什么關系。本文主要參考若干kernel資料,對應的kernel源碼版本主要包括:linux-0.11, linux-2.2.16, linux-2.4.0, linux-2.4.19, linux-2.6.18。
兩類緩存各自的作用
Page Cache
Page Cache以Page為單位,緩存文件內容。緩存在Page Cache中的文件數據,能夠更快的被用戶讀取。同時對于帶buffer的寫入操作,數據在寫入到Page Cache中即可立即返回,而不需等待數據被實際持久化到磁盤,進而提高了上層應用讀寫文件的整體性能。
Buffer Cache
磁盤的最小數據單位為sector,每次讀寫磁盤都是以sector為單位對磁盤進行操作。
sector大小跟具體的磁盤類型有關,有的為512Byte, 有的為4K Bytes。無論用戶是希望讀取1個byte,還是10個byte,最終訪問磁盤時,都必須以sector為單位讀取,如果裸讀磁盤,那意味著數據讀取的效率會非常低。
同樣,如果用戶希望向磁盤某個位置寫入(更新)1個byte的數據,他也必須整個刷新一個sector,言下之意,則是在寫入這1個byte之前,我們需要先將該1byte所在的磁盤sector數據全部讀出來,在內存中,修改對應的這1個byte數據,然后再將整個修改后的sector數據,一口氣寫入磁盤。
為了降低這類低效訪問,盡可能的提升磁盤訪問性能,內核會在磁盤sector上構建一層緩存,他以sector的整數倍力度單位(block),緩存部分sector數據在內存中,當有數據讀取請求時,他能夠直接從內存中將對應數據讀出。當有數據寫入時,他可以直接再內存中直接更新指定部分的數據,然后再通過異步方式,把更新后的數據寫回到對應磁盤的sector中。這層緩存則是塊緩存Buffer Cache。
兩類緩存的邏輯關系
從linux-2.6.18的內核源碼來看, Page Cache和Buffer Cache是一個事物的兩種表現:對于一個Page而言,對上,他是某個File的一個Page Cache,而對下,他同樣是一個Device上的一組Buffer Cache 。

File在地址空間上,以4K(page size)為單位進行切分,每一個4k都可能對應到一個page上(這里 可能 的含義是指,只有被緩存的部分,才會對應到page上,沒有緩存的部分,則不會對應),而這個4k的page,就是這個文件的一個Page Cache。而對于落磁盤的一個文件而言,最終,這個4k的page cache,還需要映射到一組磁盤block對應的buffer cache上,假設block為1k,那么每個page cache將對應一組(4個)buffer cache,而每一個buffer cache,則有一個對應的buffer cache與device block映射關系的描述符:buffer_head,這個描述符記錄了這個buffer cache對應的block在磁盤上的具體位置。

上圖只展示了Page Cache與Buffer Cache(buffer_head),以及對應的block之間的關聯關系。而從File的角度來看,要想將數據寫入磁盤,第一步,則是需要找到file具體位置對應的page cache是哪個page?進而才能將數據寫入。而要找到對應的page,則依賴于inode結構中的 i_mapping 字段:

該字段為一address_space結構,而實際上address_space即為一棵radix tree。簡單來說,radix tree即為一個多級索引結構,如果將一個文件的大小,以page為單位來切分,假設一個文件有N個page,這個N是一個32bit的int,那么,這個32bit的N,可以被切分成若干層級:level-0: [0 - 7bit], level-1:[8 - 15bit], level-2: [16 - 23bit], level-3: [24 - 31bit]。在查找File某個位置對應的page是否存在時,則拿著這個page所在的位置N,到對應的radix-tree上查找。查找時,首先通過N中的level-0部分,到radix tree上的level-0層級索引上去查找,如果不存在,則直接告知不存在,如果存在,則進一步的,拿著N中的level-1部分,到這個level-0下面對應的level-1去查找,一級一級查找。這樣,我們可以看出,最多,在4層索引上查找,就能找到N對應的page信息。radix-tree及address_space的詳細描述,可參考[12]、[2]中的說明。這里借用[12]、[2]中的各自一張圖,可能會更好說明radix-tree(address_space)結構的樣子:基本的radix-tree映射結構:
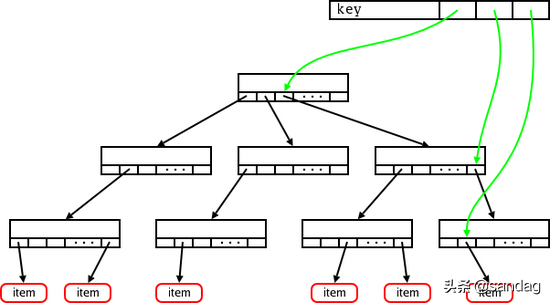
對應的inode上,i_mapping字段(address_space)對page的映射關系:

兩類緩存的演進歷史
雖然,目前Linux Kernel代碼中,Page Cache和Buffer Cache實際上是統一的,無論是文件的Page Cache還是Block的Buffer Cache最終都統一到Page上。但是,在閱讀較老代碼時,我們能夠看出,這兩塊緩存的實現,原本是完全分開的。
是什么原因使得最終這兩類緩存“走到了一起”?[10]中各位的回答,讓我豁然開來。我試著對這一演進的由來做個梳理。
第一階段:僅有Buffer Cache
在Linux-0.11版本的代碼中,我們會看到,buffer cache是完全獨立的實現,甚至都還沒有基于page作為內存單元,而是以原始指針的系形式出現。每一個block sector,在kernel內部對應一個獨立的buffer cache單元,這個buffer cache單元通過buffer head來描述:

其中,buffer_head在初始化時,其內部的 b_data 指向的是原始的內存地址:

其中,b_data指向具體的buffer cache內容,而b_dev和b_blocknr則代表了這塊緩存對應的device以及device上的block number信息。kernel通過getblk函數,會將一個指定dev, blocknr sector對應的buffer cache單元(buffer header)返回給調用方。上層讀取、寫入這個buffer_header,最終將會映射到對應(dev, blocknr) sector的讀取和寫入。

如果一個對應的buffer cache單元(dev, blocknr)已經在kernel中分配了,則會通過get_hash_table直接返回給用戶,如果沒有,則會首先創建出對應的buffer_header,并將其加入到hash_table中( inser_into_queues ),最終返回給用戶。上層對于文件的讀寫,會轉化到對于對應buffer_header的讀寫:

file_read時,會先通過f_pos計算出實際位于的dev, blocknr位置,并通過bread獲取到對應的buffer_head, 而在此之后,則會通過put_fs_byte完成buffer cache單元中的數據向目標buf的數據回填(數據讀取)。同理,在向文件中寫入數據時,也是通過f_pos首先計算出對應的dev, blocknr位置信息,進而通過bread拿到對應的buffer_head,并向buffer_header對應的buffer cache單元中寫入數據。

從上面file_read, file_write的實現來看,我們會看到bread返回目標buffer_head,讓上層只操作buffer cache單元,而不再關心block底層。

而 bread 內部則是通過上面提到的getblk函數,返回對應的buffer_head,接著執行數據讀取。
第二階段:Page Cache、Buffer Cache兩者并存
到Linux-2.2版本時,磁盤文件訪問的高速緩沖仍然是緩沖區高速緩沖(Buffer Cache)。其訪問模式與上面Linux-0.11版本的訪問邏輯基本類似。但此時,Buffer Cache已基于page來分配內存,buffer_head內部,已經有了關于所在page的一些信息:

同時,從buffer cache的初始化,以及buffer cache不足時新建buffer cache單元的動作,我們也可以看出,此時buffer cache已經完全是基于page來分配內存。
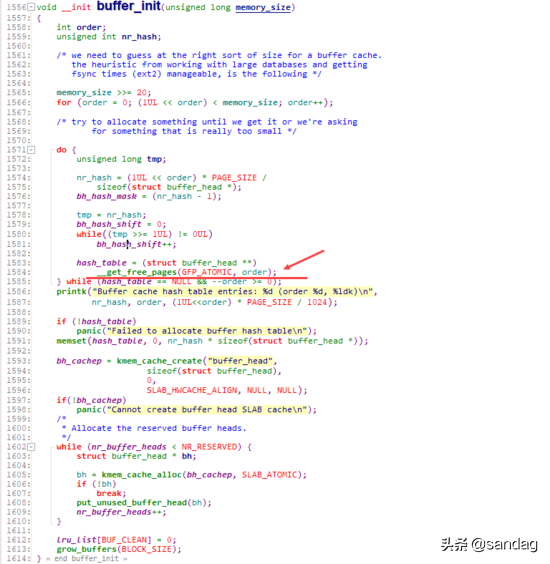
當buffer cache不足時,通過grow_buffers來新增buffer cache:

并通過create_buffers來完成對buffer_head的初始化構造:

以Linux-2.2.16版本的代碼為例,在執行磁盤文件寫入時,會通過xxx_getblk獲取對應位置的buffer_head信息,并將對應的數據寫入該buffer中。在此之后,會執行一步update_vm_cache,至于為什么會要執行這一步,我們后面再來看。

而對于對應的文件讀取,則是同樣,先通過xxx_getblk找到對應的buffer_head,在此之后,完成對應的數據讀取(通過while循環,一口氣將所有目標block的buffer_head拿出來,再一把讀取所有的數據)。

而xxx_getblk最終,還是使用的getblk 接口來定位到指定的buffer_head :

從上面的描述我們可以看出,此時的buffer cache基于page來分配內存,但是與Page Cache完全獨立,一點關系都沒有。在Linux-2.2版本中,Page Cache此時用來干什么的?(1)。 用于文件的mmap:來自[10]:
page cache was used to cache pages of files mapped with mmap MAP_FILE among other things. 來自[11]:read() and write() are implemented using the buffer cache. The read() system call reads file data into a buffer cache buffer and then copies it to the application.The mmap() system call, however, has to use the page cache to store its data since the buffer cache memory is not managed by the VM system and thus not cannot be mapped into an application address space. Therefore the file data in the buffer cache is copied into page cache pages, which are then used to satisfy page faults on the application mappings.用于network-based filesytems:來自[1]:
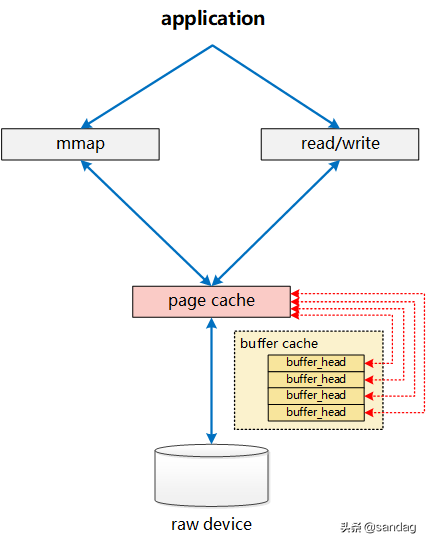
Disk-based filesystems do not directly use the page cache for writing to a regular file. This is a heritage from older versions of Linux, in which the only disk cache was the buffer cache. However, network-based filesystems always use the page cache for writing to a regular file. 此時,Page Cache和Buffer Cache的關系如下圖所示:

Page Cache僅負責其中mmap部分的處理,而Buffer Cache實際上負責所有對磁盤的IO訪問。從上面圖中,我們也可看出其中一個問題:write繞過了Page Cache,這里導致了一個同步問題。當write發生時,有效數據是在Buffer Cache中,而不是在Page Cache中。這就導致mmap訪問的文件數據可能存在不一致問題。為了解決這個問題,所有基于磁盤文件系統的write,都需要調用 update_vm_cache() 函數,該操作會修改write相關Buffer Cache對應的Page Cache。從代碼中我們可以看到,上述sysv_file_write中,在調用完copy_from_user之后,會調用update_vm_cache。同樣,正是這樣Page Cache、Buffer Cache分離的設計,導致基于磁盤的文件,同一份數據,可能在Page Cache中有一份,而同時,卻還在Buffer Cache中有一份。
第三階段:Page Cache、Buffer Cache兩者融合
介于上述Page Cache、Buffer Cache分離設計的弊端,Linux-2.4版本中對Page Cache、Buffer Cache的實現進行了融合,融合后的Buffer Cache不再以獨立的形式存在,Buffer Cache的內容,直接存在于Page Cache中,同時,保留了對Buffer Cache的描述符單元:buffer_head。
page結構中,通過buffers字段是否為空,來判定這個Page是否與一組Buffer Cache關聯(在后續的演進過程中,這個判斷,轉變為由 private 字段來判定)。

而對應的,buffer_head則增加了字段 b_page ,直接指向對應的page。

至此,兩者的關系已經相互融合如下圖所示:

一個文件的PageCache(page),通過 buffers 字段能夠非常快捷的確定該page對應的buffer_head信息,進而明確該page對應的device, block等信息。從邏輯上來看,當針對一個文件的write請求進入內核時,會執行 generic_file_write ,在這一層,通過inode的address_space結構 mapping 會分配一個新的page來作為對應寫入的page cache(這里我們假設是一個新的寫入,且數據量僅一個page):__grab_cache_page ,而在分配了內存空間page之后,則通過 prepare_write ,來完成對應的buffer_head的構建。

prepare_write實際執行的是:__block_prepare_write ,在其中,會針對該page分配對應的buffer_head( create_empty_buffers ),并計算實際寫入的在device上的具體位置:blocknr,進而初始化buffer_head( get_block )。

在create_empty_buffers內部,則通過create_buffers以及set_bh_page等一系列操作,將page與buffer_head組織成如前圖所示的通過 buffers 、b_page等相互關聯的關系。

通過create_buffers分配一組串聯好的buffer_head。

通過set_bh_page將各buffer_head關聯到對應的page,以及data的具體位置。

正是如上的一系列動作,使得Page Cache與Buffer Cache(buffer_head)相互綁定。對上,在文件讀寫時,以page為單位進行處理。而對下,在數據向device進行刷新時,則可以以buffer_head(block)為單位進行處理。在后續的linux-2.5版本中,引入了bio結構來替換基于buffer_head的塊設備IO操作。[注意] :這里的Page Cache與Buffer Cache的融合,是針對文件這一層面的Page Cache與Buffer Cache的融合。對于跨層的:File層面的Page Cache和裸設備Buffer Cache,雖然都統一到了基于Page的實現,但File的Page Cache和該文件對應的Block在裸設備層訪問的Buffer Cache,這兩個是完全獨立的Page。這種情況下,一個物理磁盤Block上的數據,仍然對應了Linux內核中的兩份Page:一個是通過文件層訪問的File的Page Cache(Page Cache);一個是通過裸設備層訪問的Page Cache(Buffer Cache)。

責任編輯:gt
-
Linux
+關注
關注
87文章
11319瀏覽量
209832 -
磁盤
+關注
關注
1文章
379瀏覽量
25224
原文標題:Linux內核Page Cache和Buffer Cache關系及演化歷史
文章出處:【微信號:LinuxDev,微信公眾號:Linux閱碼場】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
HTTP緩存頭的使用 本地緩存與遠程緩存的區別
什么是緩存(Cache)及其作用
Cache和內存有什么區別
電路的兩類約束指的是哪兩類
什么是CPU緩存?它有哪些作用?
Cortex R52內核Cache的具體操作(2)

Cortex R52內核Cache的相關概念(1)
CortexR52內核Cache的具體操作

鴻蒙原生應用元服務開發WEB-緩存與存儲管理
內核(linux-3.12)的文件系統預讀設計和實現
為什么HAL庫在操作Flash erase的時候,需要把I-Cache和D-Cache關閉呢?
STM32h7開啟Cache后,串口發送DMA會導致中斷觸發如何解決?
Linux內核內存管理之slab分配器
先楫 HPM片上 Cache使用指南

先楫HPM片上Cache使用指南經驗分享





 工商網監
工商網監
評論