 探究Overlay網絡模型和Underlay網絡模型。
探究Overlay網絡模型和Underlay網絡模型。
本文分別介紹Overlay網絡模型和Underlay網絡模型。
(一) Overlay網絡模型
物理網絡模型中,連通多個物理網橋上的主機的一個簡單辦法是通過媒介直接連接這些網橋設備,各個主機處于同一個局域網(LAN)之中,管理員只需要確保各個網橋上每個主機的IP地址不相互沖突即可。
類似地,若能夠直接連接宿主機上的虛擬網橋形成一個大的局域網,就能在數據鏈路層打通各宿主機上的內部網絡,讓容器可通過自有IP地址直接通信。為避免各容器間的IP地址沖突,一個常見的解決方案是將每個宿主機分配到同一網絡中的不同子網,各主機基于自有子網向其容器分配IP地址。
顯然,主機間的網絡通信只能經由主機上可對外通信的網絡接口進行,跨主機在數據鏈路層直接連接虛擬網橋的需求必然難以實現,除非借助宿主機間的通信網絡構建的通信“隧道”進行數據幀轉發。這種于某個通信網絡之上構建出的另一個邏輯通信網絡通常即10.1.2節提及的Overlay網絡或Underlay網絡。圖10-7為Overlay網絡功能示意圖。
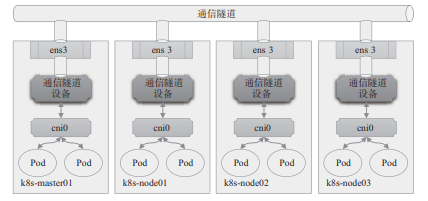
圖10-7 Overlay網絡功能示意圖
隧道轉發的本質是將容器雙方的通信報文分別封裝成各自宿主機之間的報文,借助宿主機的網絡“隧道”完成數據交換。這種虛擬網絡的基本要求是各宿主機只需支持隧道協議即可,對于底層網絡沒有特殊要求。
VXLAN協議是目前最流行的Overlay網絡隧道協議之一,它也是由IETF定義的NVO3(Network Virtualization over Layer 3)標準技術之一,采用L2 over L4(MAC-in-UDP)的報文封裝模式,將二層報文用三層協議進行封裝,可實現二層網絡在三層范圍內進行擴展,將“二層域”突破規模限制形成“大二層域”。
那么,同一大二層域就類似于傳統網絡中VLAN(虛擬局域網)的概念,只不過在VXLAN網絡中,它被稱作Bridge-Domain,以下簡稱為BD。類似于不同的VLAN需要通過VLAN ID進行區分,各BD要通過VNI加以標識。
但是,為了確保VXLAN機制通信過程的正確性,涉及VXLAN通信的IP報文一律不能分片,這就要求物理網絡的鏈路層實現中必須提供足夠大的MTU值,或修改其MTU值以保證VXLAN報文的順利傳輸。不過,降低默認MTU值,以及額外的頭部開銷,必然會影響到報文傳輸性能。
VXLAN的顯著的優勢之一是對底層網絡沒有侵入性,管理員只需要在原有網絡之上添加一些額外設備即可構建出虛擬的邏輯網絡來。這個額外添加的設備稱為VTEP(VXLAN Tunnel Endpoints),它工作于VXLAN網絡的邊緣,負責相關協議報文的封包和解包等操作,從作用來說相當于VXLAN隧道的出入口設備。
VTEP代表著一類支持VXLAN協議的交換機,而支持VXLAN協議的操作系統也可將一臺主機模擬為VTEP,Linux內核自3.7版本開始通過vxlan內核模塊原生支持此協議。
于是,各主機上由虛擬網橋構建的LAN便可借助vxlan內核模塊模擬的VTEP設備與其他主機上的VTEP設備進行對接,形成隧道網絡。同一個二層域內的各VTEP之間都需要建立VXLAN隧道,因此跨主機的容器間直接進行二層通信的VXLAN隧道是各VTEP之間的點對點隧道,如圖10-8所示。
對于Flannel來說,這個VTEP設備就是各節點上生成flannel.1網絡接口,其中的“1”是VXLAN中的BD標識VNI,因而同一Kubernetes集群上所有節點的VTEP設備屬于VNI為1的同一個BD。
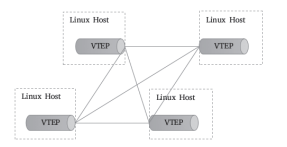
圖10-8 Linux VTEP
類似VLAN的工作機制,相同VXLAN VNI在不同VTEP之間的通信要借助二層網關來完成,而不同VXLAN之間,或者VXLAN同非VXLAN之間的通信則需經由三層網關實現。VXLAN支持使用集中式和分布式兩種形式的網關:前者支持流量的集中管理,配置和維護較為簡單,但轉發效率不高,且容易出現瓶頸和網關可用性問題;后者以各節點為二層或三層網關,消除了瓶頸。
然而,VXLAN網絡中的容器在首次通信之前,源VTEP又如何得知目標服務器在哪一個VTEP,并選擇正確的路徑傳輸通信報文呢?
常見的解決思路一般有兩種:多播和控制中心。
多播是指同一個BD內的各VTEP加入同一個多播域中,通過多播報文查詢目標容器所在的目標VTEP。
而控制中心則在某個共享的存儲服務上保存所有容器子網及相關VTEP的映射信息,各主機上運行著相關的守護進程,并通過與控制中心的通信獲取相關的映射信息。Flannel默認的VXLAN后端采用的是后一種方式,它把網絡配置信息存儲在etcd系統上。
Linux內核自3.7版本開始支持vxlan模塊,此前的內核版本可以使用UDP、IPIP或GRE隧道技術。事實上,考慮到當今公有云底層網絡的功能限制,Overlay網絡反倒是一種最為可行的容器網絡解決方案,僅那些更注重網絡性能的場景才會選擇Underlay網絡。
(二)Underlay網絡模型
Underlay網絡就是傳統IT基礎設施網絡,由交換機和路由器等設備組成,借助以太網協議、路由協議和VLAN協議等驅動,它還是Overlay網絡的底層網絡,為Overlay網絡提供數據通信服務。容器網絡中的Underlay網絡是指借助驅動程序將宿主機的底層網絡接口直接暴露給容器使用的一種網絡構建技術,較為常見的解決方案有MAC VLAN、IP VLAN和直接路由等。
1. MAC VLAN
MAC VLAN支持在同一個以太網接口上虛擬出多個網絡接口,每個虛擬接口都擁有唯一的MAC地址,并可按需配置IP地址。通常這類虛擬接口被網絡工程師稱作子接口,但在MAC VLAN中更常用上層或下層接口來表述。與Bridge模式相比,MAC VLAN不再依賴虛擬網橋、NAT和端口映射,它允許容器以虛擬接口方式直接連接物理接口。圖10-9給出了Bridge與MAC VLAN網絡對比示意圖。
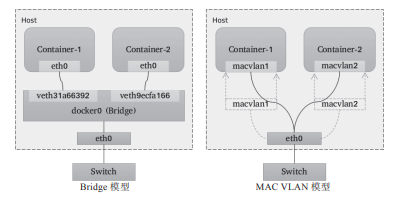
圖10-9 Bridge與MAC VLAN網絡對比
MAC VLAN有Private、VEPA、Bridge和Passthru幾種工作模式,它們各自的工作特性如下。
Private:禁止構建在同一物理接口上的多個MAC VLAN實例(容器接口)彼此間的通信,即便外部的物理交換機支持“發夾模式”也不行。
VPEA:允許構建在同一物理接口上的多個MAC VLAN實例(容器接口)彼此間的通信,但需要外部交換機啟用發夾模式,或者存在報文轉發功能的路由器設備。
Bridge:將物理接口配置為網橋,從而允許同一物理接口上的多個MAC VLAN實例基于此網橋直接通信,而無須依賴外部的物理交換機來交換報文;此為最常用的模式,甚至還是Docker容器唯一支持的模式。
Passthru:允許其中一個MAC VLAN實例直接連接物理接口。
由上述工作模式可知,除了Passthru模式外的容器流量將被MAC VLAN過濾而無法與底層主機通信,從而將主機與其運行的容器完全隔離,其隔離級別甚至高于網橋式網絡模型,這對于有多租戶需求的場景尤為有用。
由于各實例都有專用的MAC地址,因此MAC VLAN允許傳輸廣播和多播流量,但它要求物理接口工作于混雜模式,考慮到很多公有云環境中并不允許使用混雜模式,這意味著MAC VLAN更適用于本地網絡環境。
需要注意的是,MAC VLAN為每個容器使用一個唯一的MAC地址,這可能會導致具有安全策略以防止MAC欺騙的交換機出現問題,因為這類交換機的每個接口只允許連接一個MAC地址。另外,有些物理網卡存在可支撐的MAC地址數量上限。
2. IP VLAN
IP VLAN類似于MAC VLAN,它同樣創建新的虛擬網絡接口并為每個接口分配唯一的IP地址,不同之處在于,每個虛擬接口將共享使用物理接口的MAC地址,從而不再違反防止MAC欺騙的交換機的安全策略,且不要求在物理接口上啟用混雜模式,如圖10-10所示。
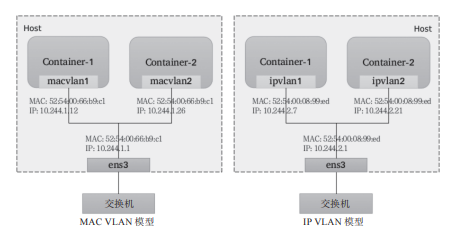
圖10-10 MAC VLAN對比IP VLAN
IP VLAN有L2和L3兩種模型,其中IP VLAN L2的工作模式類似于MAC VLAN Bridge模式,上層接口(物理接口)被用作網橋或交換機,負責為下層接口交換報文;
而IP VLAN L3模式中,上層接口扮演路由器的角色,負責為各下層接口路由報文,如圖10-11所示。
IP VLAN L2模型與MAC VLAN Bridge模型都支持ARP協議和廣播流量,它們擁有直接接入網橋設備的網絡接口,能夠通過802.1d數據包進行泛洪和MAC地址學習。但IP VLAN L3模式下,網絡棧在容器內處理,不支持多播或廣播流量,從這個意義上講,它的運行模式與路由器的報文處理機制相同。
雖然支持多種網絡模型,但MAC VLAN和IP VLAN不能同時在同一物理接口上使用。Linux內核文檔中強調,MAC VLAN和IP VLAN具有較高的相似度,因此,通常僅在必須使用IP VLAN的場景中才不使用MAC VLAN。一般說來,強依賴于IP VLAN的場景有如下幾個:
Linux主機連接到的外部交換機或路由器啟用了防止MAC地址欺騙的安全策略;
虛擬接口的需求數量超出物理接口能夠支撐的容量上限,并且將接口置于混雜模式會給性能帶來較大的負面影響;
將虛擬接口放入不受信任的網絡名稱空間中可能會導致惡意的濫用。
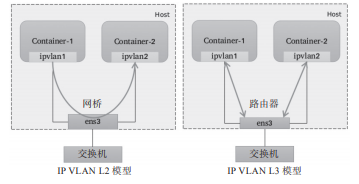
圖10-11 IP VLAN的L2和L3模型
需要注意的是,Linux內核自4.2版本后才支持IP VLAN網絡驅動,且在Linux主機上使用ip link命令創建的802.1q配置接口不具有持久性,因此需依賴管理員通過網絡啟動腳本保持配置。
3. 直接路由
“直接路由”模型放棄了跨主機容器在L2的連通性,而專注于通過路由協議提供容器在L3的通信方案。這種解決方案因為更易于集成到現在的數據中心的基礎設施之上,便捷地連接容器和主機,并在報文過濾和隔離方面有著更好的擴展能力及更精細的控制模型,因而成為容器化網絡較為流行的解決方案之一。
一個常用的直接路由解決方案如圖10-12所示,每個主機上的各容器在二層通過網橋連通,網關指向當前主機上的網橋接口地址。跨主機的容器間通信,需要依據主機上的路由表指示完成報文路由,因此每個主機的物理接口地址都有可能成為另一個主機路由報文中的“下一跳”,這就要求各主機的物理接口必須位于同一個L2網絡中。
于是,在較大規模的主機集群中,問題的關鍵便轉向如何更好地為每個主機維護路由表信息。常見的解決方案有:
①Flannel host-gw使用存儲總線etcd和工作在每個節點上的flanneld進程動態維護路由;
②Calico使用BGP(Border Gateway Protocol)協議在主機集群中自動分發和學習路由信息。與Flannel不同的是,Calico并不會為容器在主機上使用網橋,而是僅為每個容器生成一對veth設備,留在主機上的那一端會在主機上生成目標地址,作為當前容器的路由條目。
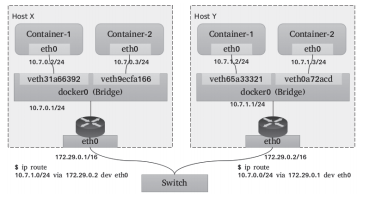
圖10-12直接路由虛擬網絡示意圖
顯然,較Overlay來說,無論是MAC VLAN、IP VLAN還是直接路由機制的Underlay網絡模型的實現,它們因無須額外的報文開銷而通常有著更好的性能表現,但對底層網絡有著更多的限制條件。
編輯:jq
-
數據
+關注
關注
8文章
7085瀏覽量
89216 -
主機
+關注
關注
0文章
998瀏覽量
35181 -
VLAN
+關注
關注
1文章
279瀏覽量
35700 -
網絡模型
+關注
關注
0文章
44瀏覽量
8446
原文標題:一文搞懂Kubernetes的網絡模型:Overlay和Underlay
文章出處:【微信號:magedu-Linux,微信公眾號:馬哥Linux運維】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論