") 簡(jiǎn)述OpenVINO? + ResNet實(shí)現(xiàn)圖像分類
簡(jiǎn)述OpenVINO? + ResNet實(shí)現(xiàn)圖像分類
推理引擎(IE)應(yīng)用開發(fā)流程
與相關(guān)函數(shù)介紹
通過OpenVINO的推理引擎跟相關(guān)應(yīng)用集成相關(guān)深度學(xué)習(xí)模型的應(yīng)用基本流程如下:
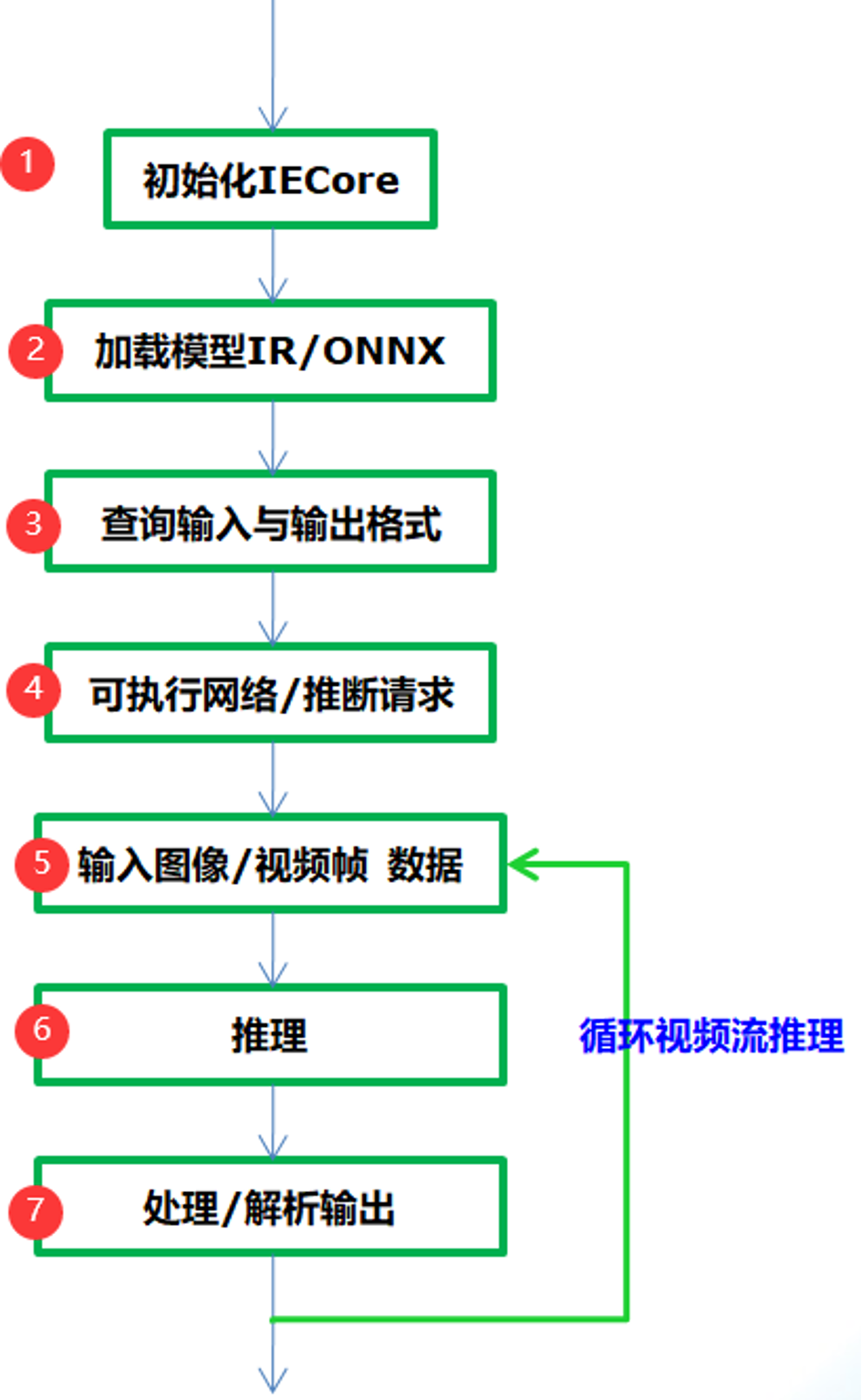
圖-1
從圖-1可以看到只需要七步就可以完成應(yīng)用集成,實(shí)現(xiàn)深度學(xué)習(xí)模型的推理預(yù)測(cè),各步驟中相關(guān)的API函數(shù)支持與作用解釋如下:
Step 1:
InferenceEngine::Core // IE對(duì)象
Step 2:
Core.ReadNetwork(xml/onnx)輸入的IR或者onnx格式文件,返回CNNNetwork對(duì)象
Step 3:
InferenceEngine::InputsDataMap, InferenceEngine::InputInfo, // 模型輸入信息
InferenceEngine::OutputsDataMap // 模型輸出信息
使用上述兩個(gè)相關(guān)輸入與輸出對(duì)象就可以設(shè)置輸入的數(shù)據(jù)類型與精度,獲取輸入與輸出層的名稱。
Step 4:
ExecutableNetwork LoadNetwork (
const CNNNetwork &network,
const std::string &deviceName,
const std::map< std::string, std::string > &config={}
)
通過Core的LoadNetwork方法生成可執(zhí)行的網(wǎng)絡(luò),如果你有多個(gè)設(shè)備,就可以創(chuàng)建多個(gè)可執(zhí)行的網(wǎng)絡(luò)。其參數(shù)解釋如下:
network 參數(shù)表示step2加載得到CNNNetwork對(duì)象實(shí)例
deviceName表示模型計(jì)算所依賴的硬件資源,可以為CPU、GPU、 FPGA、 FPGA、MYRIAD
config默認(rèn)為空
InferRequest InferenceEngine::CreateInferRequest()
表示從可執(zhí)行網(wǎng)絡(luò)創(chuàng)建推理請(qǐng)求。
Step 5:
根據(jù)輸入層的名稱獲取輸入buffer數(shù)據(jù)緩沖區(qū),然后把輸入圖像數(shù)據(jù)填到緩沖區(qū),實(shí)現(xiàn)輸入設(shè)置。其中根據(jù)輸入層名稱獲取輸入緩沖區(qū)的函數(shù)為如下:
Blob::Ptr GetBlob (
const std::string &name // 輸入層名稱
)
注意:返回包含輸入層維度信息,支持多個(gè)輸入層數(shù)據(jù)設(shè)置!
Step 6:
推理預(yù)測(cè),直接調(diào)用推理請(qǐng)求的InferRequest.infer()方法即可,該方法無(wú)參數(shù)。
Step 7:
調(diào)用InferRequest的GetBlob()方法,使用參數(shù)為輸出層名稱,就會(huì)得到網(wǎng)絡(luò)的輸出預(yù)測(cè)結(jié)果,根據(jù)輸出層維度信息進(jìn)行解析即可獲取輸出預(yù)測(cè)信息與顯示。
圖像分類與ResNet網(wǎng)絡(luò)
圖像分類是計(jì)算機(jī)視覺的關(guān)鍵任務(wù)之一,關(guān)于圖像分類最知名的數(shù)據(jù)集是ImageNet,包含了自然場(chǎng)景下大量各種的圖像數(shù)據(jù),支持1000個(gè)類別的圖像分類。OpenVINO在模型庫(kù)的public中有ResNet模型1000個(gè)分類的預(yù)訓(xùn)練模型支持,它們主要是:
- resnest-18-pytorch
- resnest-34-pytorch
- resnest-50-pytorch
- resnet-50-tf
其中18、34、50表示權(quán)重層,pytorch表示模型來(lái)自pytorch框架訓(xùn)練生成、tf表示tensorflow訓(xùn)練生成。ResNet系列網(wǎng)絡(luò)的詳細(xì)說明如下:
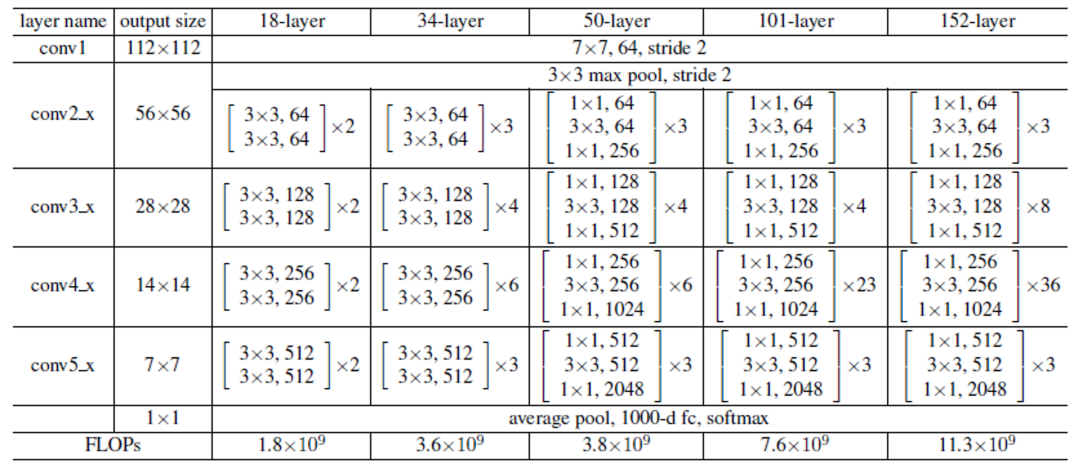
圖-2(來(lái)自《Deep Residual Learning for Image Recognition》論文)
我們以ResNet18-pytorch的模型為例,基于Pytorch框架我們可以很輕松的把它轉(zhuǎn)換為ONNX格式文件。然后使用Netron工具打開,可以看到網(wǎng)絡(luò)的輸入圖示如下:

圖-3
查看網(wǎng)絡(luò)的輸出:
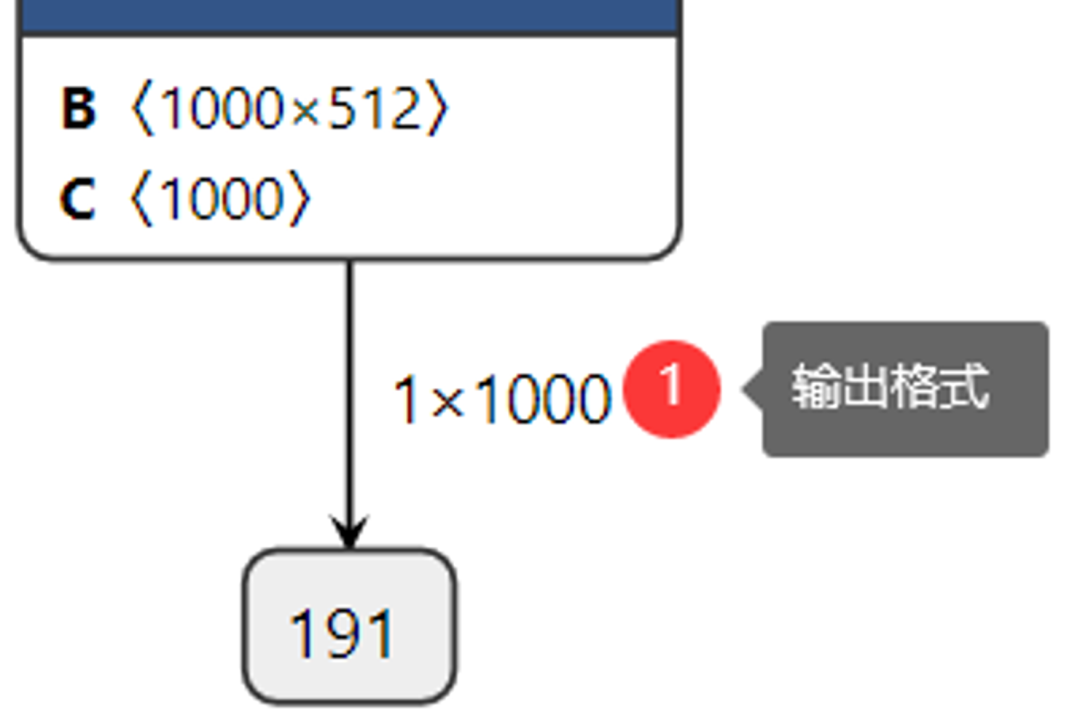
圖-4
這樣我們很清楚的知道網(wǎng)絡(luò)的輸入與輸出層名稱,輸入數(shù)據(jù)格式與輸出數(shù)據(jù)格式,其中輸入數(shù)據(jù)格式NCHW中的N表示圖像數(shù)目,這里是1、C表示圖像通道數(shù),這里輸入的是彩色圖像,通道數(shù)為3、H與W分別表示圖像的高與寬,均為224。在輸出格式中1x1000中1表示圖像數(shù)目、1000表示預(yù)測(cè)的1000個(gè)分類的置信度數(shù)據(jù)。
程序?qū)崿F(xiàn)的基本流程與步驟
前面已經(jīng)介紹了IE SDK相關(guān)函數(shù),圖像分類模型ResNet18的輸入與輸出格式信息。現(xiàn)在我們就可以借助IE SDK來(lái)完成一個(gè)完整的圖像分類模型的應(yīng)用部署了,根據(jù)前面提到的步驟各步的代碼實(shí)現(xiàn)與解釋如下:
1. 初始化IE
InferenceEngine::Core ie;
2. 加載ResNet18網(wǎng)絡(luò)
InferenceEngine::CNNNetwork network = ie.ReadNetwork(onnx);
InferenceEngine::InputsDataMap inputs = network.getInputsInfo();
InferenceEngine::OutputsDataMap outputs = network.getOutputsInfo();
3. 獲取輸入與輸出名稱、設(shè)置輸入與輸出數(shù)據(jù)格式
std::string input_name = "";
for (auto item : inputs) {
input_name = item.first;
auto input_data = item.second;
input_data->setPrecision(Precision::FP32);
input_data->setLayout(Layout::NCHW);
input_data->getPreProcess().setColorFormat(ColorFormat::RGB);
std::cout << "input name: " << input_name << std::endl;
}
std::string output_name = "";
for (auto item : outputs) {
output_name = item.first;
auto output_data = item.second;
output_data->setPrecision(Precision::FP32);
std::cout << "output name: " << output_name << std::endl;
}
4. 獲取推理請(qǐng)求對(duì)象實(shí)例
auto executable_network = ie.LoadNetwork(network, "CPU");
auto infer_request = executable_network.CreateInferRequest();
5. 輸入圖像數(shù)據(jù)設(shè)置
auto input = infer_request.GetBlob(input_name);
size_t num_channels = input->getTensorDesc().getDims()[1];
size_t h = input->getTensorDesc().getDims()[2];
size_t w = input->getTensorDesc().getDims()[3];
size_t image_size = h*w;
cv::Mat blob_image;
cv::resize(src, blob_image, cv::Size(w, h));
cv::cvtColor(blob_image, blob_image, cv::COLOR_BGR2RGB);
blob_image.convertTo(blob_image, CV_32F);
blob_image = blob_image / 255.0;
cv::subtract(blob_image, cv::Scalar(0.485, 0.456, 0.406), blob_image);
cv::divide(blob_image, cv::Scalar(0.229, 0.224, 0.225), blob_image);
// HWC =》NCHW
float* data = static_cast
}
}
}
在輸入數(shù)據(jù)部分OpenCV導(dǎo)入的圖像三通道順序是BGR,所以要轉(zhuǎn)換為RGB,resize到224x224大小、像素值歸一化為0~1之間、然后要減去均值(0.485, 0.456, 0.406),除以方差(0.229, 0.224, 0.225)完成預(yù)處理之后再填充到Blob緩沖區(qū)中區(qū)。
6. 推理
infer_request.Infer();
7. 解析輸出與顯示結(jié)果
auto output = infer_request.GetBlob(output_name);
const float* probs = static_cast
const SizeVector outputDims = output->getTensorDesc().getDims();
std::cout << outputDims[0] << "x" << outputDims[1] << std::endl;
float max = probs[0];
int max_index = 0;
for (int i = 1; i < outputDims[1]; i++) {
if (max < probs[i]) {
max = probs[i];
max_index = i;
}
}<:fp32>
cv::putText(src, labels[max_index], cv::Point(50, 50), cv::FONT_HERSHEY_SIMPLEX, 1.0, cv::Scalar(0, 0, 255), 2, 8);
cv::imshow("輸入圖像", src);
cv::waitKey(0);
解析部分代碼首先通過輸出層名稱獲取輸出數(shù)據(jù)對(duì)象BLOB,然后根據(jù)輸出格式1x1000,尋找最大值對(duì)應(yīng)的index,根據(jù)索引index得到對(duì)應(yīng)的分類標(biāo)簽,然后通過OpenCV圖像輸出分類結(jié)果。
運(yùn)行結(jié)果
圖-5(來(lái)自ImageNet測(cè)試集)
這樣我們就使用OpenVINO 的推理引擎相關(guān)的SDK函數(shù)支持成功部署ResNet18模型,并預(yù)測(cè)了一張輸入圖像。你可以能還想知道除了圖像分類模型,OpenVINO 推理引擎在對(duì)象檢測(cè)方面都有哪些應(yīng)用,我們下次繼續(xù)…….
編輯:jq
-
函數(shù)
+關(guān)注
關(guān)注
3文章
4338瀏覽量
62761 -
代碼
+關(guān)注
關(guān)注
30文章
4803瀏覽量
68752 -
OpenCV
+關(guān)注
關(guān)注
31文章
635瀏覽量
41388 -
SDK
+關(guān)注
關(guān)注
3文章
1039瀏覽量
46030
原文標(biāo)題:OpenVINO? + ResNet實(shí)現(xiàn)圖像分類
文章出處:【微信號(hào):英特爾物聯(lián)網(wǎng),微信公眾號(hào):英特爾物聯(lián)網(wǎng)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
基于FPGA實(shí)現(xiàn)圖像直方圖設(shè)計(jì)
高通AI Hub:輕松實(shí)現(xiàn)Android圖像分類

使用卷積神經(jīng)網(wǎng)絡(luò)進(jìn)行圖像分類的步驟
基于改進(jìn)ResNet50網(wǎng)絡(luò)的自動(dòng)駕駛場(chǎng)景天氣識(shí)別算法

手把手教你使用LabVIEW TensorRT實(shí)現(xiàn)圖像分類實(shí)戰(zhàn)(含源碼)
使用OpenVINO Model Server在哪吒開發(fā)板上部署模型
使用OpenVINO C# API部署YOLO-World實(shí)現(xiàn)實(shí)時(shí)開放詞匯對(duì)象檢測(cè)

簡(jiǎn)述計(jì)算機(jī)總線的分類
OpenVINO2024 C++推理使用技巧
計(jì)算機(jī)視覺怎么給圖像分類
一種利用光電容積描記(PPG)信號(hào)和深度學(xué)習(xí)模型對(duì)高血壓分類的新方法
OpenAI發(fā)布圖像檢測(cè)分類器,可區(qū)分AI生成圖像與實(shí)拍照片
為OpenVINO添加對(duì)Paddle 2.5的支持
基于OpenVINO?和AIxBoard的智能安檢盒子設(shè)計(jì)

如何在MacOS上編譯OpenVINO C++項(xiàng)目呢?






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論