 一篇包羅萬象的場景文本檢測算法綜述
一篇包羅萬象的場景文本檢測算法綜述
相關背景介紹
文本在人機交互中扮演著重要的角色, 圖片中的文本所包含的豐富而精確的信息在基于視覺的設備中應用非常廣泛,能夠輔助設備獲得更精確的物體和周邊環境信息。隨著智能機器人、無人駕駛、醫療診斷的飛速發展,文本的檢測與識別已經成為定位和理解物體信息的重要途徑[28]。現實當中,許多跟文本識別相關的應用極大地方便了我們的生活,如車牌識別、發票識別、拍圖識字等。
文本識別demoOCR相關概念:提到文本檢測識別,我們會聯想到的一個詞就是 OCR,OCR 是光學字符識別 Optical Character Recognition的簡稱,是指對文本資料的圖像文件進行分析識別處理,獲取文字的過程 [19]。現在所說的OCR 通常也指場景文字識別,根據識別場景,可大致將 OCR 分為識別特定場景的專用 OCR 和識別多種場景的通用 OCR。比如車牌識別就是對特定場景的 OCR,而對自然場景中的文字識別則是通用場景 OCR,一般來說,自然場景的文字識別由于環境更加復雜多樣,其識別難度相對困難。文字識別通常包含文本檢測和文字識別兩個階段。文本檢測特點:1、相比于常規物體檢測,文字行長度、長寬比例變化范圍很大。 2、文本行有方向性,anchor-based的檢測通常是水平和垂直方向的矩形。 3、有些藝術字體形狀變化非常大,很多是彎曲的,并且字體類型豐富,語言種類豐富。 4、由于豐富的背景圖像干擾,手工設計特征在自然場景文本識別任務中不夠魯棒。
文本檢測比普通物體檢測存在更多特點
本文將介紹以下幾部分
一、配置Docker環境為什么要特意提一下Docker,當然是因為這東西挺有意思,可以幫助我們高效的做項目! 接下來就來看看,什么是Docker吧。 做深度學習項目時,配環境是一件很讓人頭疼的事情,尤其是當你要跑別人代碼時,自己的環境跟別人的環境不一致,就會出現各種bug,這就是所謂的生產環境(別人的環境)跟測試環境不一致(你的環境),那么,我們可以想象,如果現在有一種工具,可以把別人的環境克隆一份,放到自己電腦上,然后自己用這個環境,豈不就不會出現環境不一致的問題啦,美滋滋。 那么,有沒有這種工具呢?答案是有的,這個工具就是Docker。第一步,想要用docker,首先就要安裝docker在我們的計算機上,安裝docker教程如下:跟著教程復制粘貼命令就行了~ https://docs.docker.com/install/linux/docker-ce/ubuntu/第二步,安裝好了docker,得學學怎么用docker,類似于git,在Linux上可用命令可以操作:先學習一下docker里邊的基本概念,再學習一下基本命令(如果pull下一個鏡像,如果run等等),參考資料如下: https://blog.csdn.net/fgf00/article/details/51893771 蟈蟈:Docker,救你于「深度學習環境配置」的苦海,https://zhuanlan.zhihu.com/p/64493662二、介紹多種文本檢測算法1、CTPN(Detecting Text in Natural Image with Connectionist Text Proposal Network)ECCV 16這篇論文的亮點是結合了CNN與雙向LSTM,能有效的檢測出復雜場景的橫向分布的文字, 在當時也算是開坑之作。 總的來說,該算法的重點部分有三個: 1、在網絡上改進,似的提取的特征能夠在雙向LSTM中使用。 2、使用了雙向LSTM。 3、采用了一組(10個)等寬度,不同高度的的Anchors,用于定位文字位置。 4、采用文本線構造算法,把這些text proposal連接成一個文本檢測框。 這篇論文的細節內容知乎上已經有大佬寫的很好了,我就不重復搬磚了,可參考: 白裳:場景文字檢測—CTPN原理與實現(https://zhuanlan.zhihu.com/p/34757009) 但是我還是要把這篇文章的實驗結果搬出來,這樣后續的文章可以跟他比較~實驗結果:
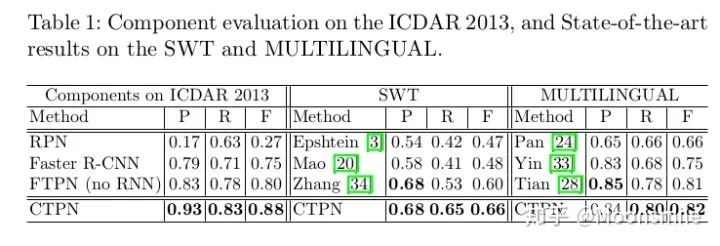
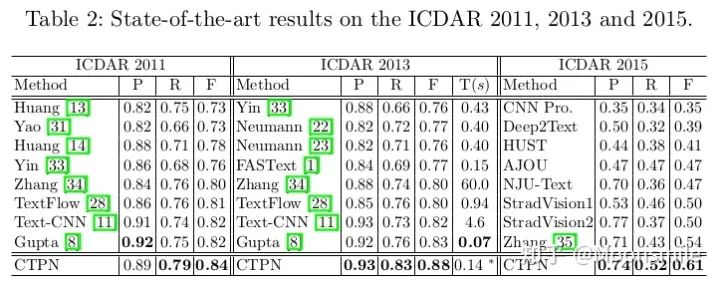
總結分析:現在來看這算法已經挺老了,缺點很明顯,只能檢測橫向或者縱向(改anchor比例后可檢測縱向)的文本, 但是不能檢測其他方向, 并且在精度上也落后了.Github 開源代碼:https://github.com/eragonruan/text-detection-ctpn2、EAST(EAST: An Efficient and Accurate Scene Text Detector)CVPR 17這篇論文提出了一種端到端的快速有效的文本檢測方法,消除了中間多個stage(如候選區域聚合,文本分詞,后處理等),直接預測文本行,從下圖中可看出,EAST的 pipeline(e)最為簡潔。
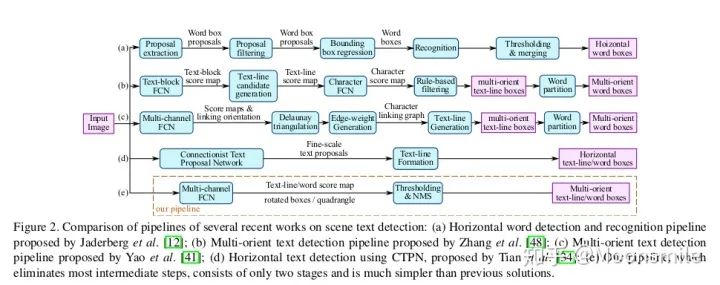
EAST pipeline與其他框架pipline對比論文亮點:提出了一種基于兩階段的端到端的快速有效的文本檢測方法(借鑒了DenseBox和FCN),不熟悉DenseB。 ox的可以看看這篇文章中對其的介紹 。 陀飛輪:目標檢測:Anchor-Free時代 即可以檢測單詞級別,又可以檢測文本行級別.檢測的形狀可以為任意形狀的四邊形(QUAD)或傾斜矩形 (RBOX)。 采用了Locality-Aware NMS來對生成的框進行過濾。網絡部分:這個網絡的基本結構是以2015年發表的DenseBox中的網絡為基礎構建的。基于上述主干特征提取網絡,抽取不同level的feature map,然后上借鑒U-net的合并規則進行合并。 輸出是稠密的每個像素對于文本的預測信息。我們以RBOX為例,網絡輸出的通道數應為6(1個為score map,4個為文本框的坐標信息,1個為角度)。我們預測的幾何形狀分為RBOX和QUAD(輸出為9維,包括8個坐標,一個score map)兩種,在后面為每一種也相應設計了不同的loss值。其中score所代表的含義是在該像素位置預測的目標的可信度,其值為[0, 1]。在最后我們會將score值大于我們所設計的閾值的預 測框留下來,并進行NMS獲取最終結果[10,21,22]。
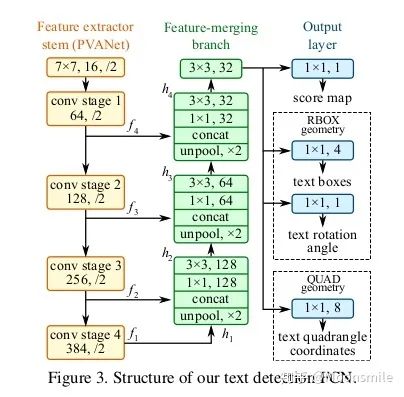
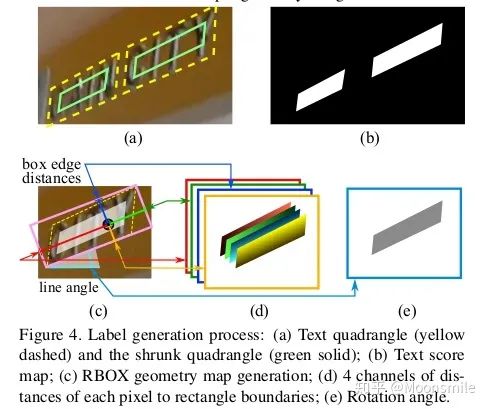
網絡標簽的生成:要對網絡進行訓練,就要有標簽,讓我們預測的結果和標簽進行對比,然后通過不斷優化參數,最終得到我們想要的網絡。 Score map 標簽的產生:根據論文的描述,我們Score map的正樣本的范圍,其實就是在圖片中我們標注框的一個縮進框,如下圖的(a)到(b)所 示,具體的公式請看原論文 [10]。 Geometry Map 標簽產生:不詳細說明,請參照原論文 [10]。
損失函數:由Score map 和 Geometry Map 兩部分產生的損失加權組成。
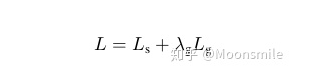
loss 對Score map 采用了class-balanced cross-entropy,如下:
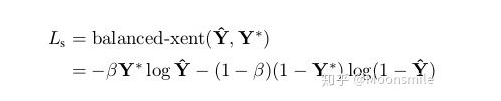
class-balanced cross-entropy 是平衡因子,計算公式如下 (是標簽,? 是預測的Score map) : 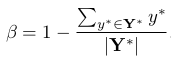 平衡因子 對Geometry Map計算損失:“we adopt the IoU loss in the AABB part of RBOX regression, and a scale-normalized smoothed-L1 loss for QUAD regression”[10]這里只以RBOX為例說明:IoU loss 部分:
平衡因子 對Geometry Map計算損失:“we adopt the IoU loss in the AABB part of RBOX regression, and a scale-normalized smoothed-L1 loss for QUAD regression”[10]這里只以RBOX為例說明:IoU loss 部分:
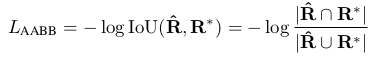
IoU loss loss of rotation angle:
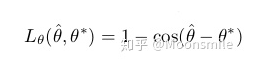
loss of rotation angle Geometry Map loss 總和: 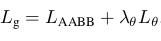 Geometry Map loss 總和 Locality-aware NMS: 與標準的NMS相比,主要在于多了一個合并階段。迭代兩兩候選框,如果兩個候選框高于某個權值,進行一個加權的合并操作,合并完再做一個標準的NMS [21,22]。實驗結果:從實驗結果中可以看出,這篇文章比14和15年的一些算法在精度上要高出很多。
Geometry Map loss 總和 Locality-aware NMS: 與標準的NMS相比,主要在于多了一個合并階段。迭代兩兩候選框,如果兩個候選框高于某個權值,進行一個加權的合并操作,合并完再做一個標準的NMS [21,22]。實驗結果:從實驗結果中可以看出,這篇文章比14和15年的一些算法在精度上要高出很多。
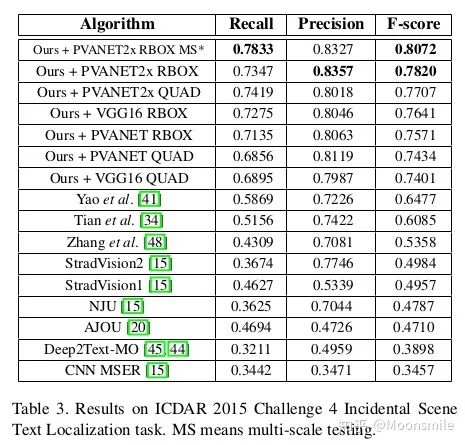
總結分析:優點:用了特征圖多尺度融合,所以可檢測不同尺度的文本區域, 預測的文本框是帶角度的,所以可以對任意方向的文本進行檢測. 缺點:由于感受野和anchor大小的限制, 對長文本和曲線文本檢測困難.Github 開源代碼:https://github.com/argman/EAST https://github.com/huoyijie/AdvancedEAST https://github.com/songdejia/EAST3、SegLink (Detecting Oriented Text in Natural Images by Linking Segments) CVPR 17從EAST算法中可以知道, 檢測長文本是比較困難的, 或者說,想要一次性檢測整個文本行是比較困難, 針對這個問題, 本文提出了一種新的思想Seglink (segment + link),它是在SSD目標檢測方法的基礎上進行改進的,但是不通過矩形框來回歸文本區域的位置.Seglink模型的做法是:先將每個單詞切割成更易檢測的有方向的小文字塊(segment),然后用鄰近連接將各個小文字塊link成單詞。也就是說,網絡會輸出兩類信息:1、一個是segment,它可能是一個字符或者幾個字符等, 它不是整個文本行的框,而是文本行的一部分, 這個信息是帶有角度的,如下圖的黃框表示。 2、另一個是不同segment之間的link信息,而這個link也是在網絡中自動學習的,由網絡判定哪些segment屬于一個文本行,由下圖的綠線表示。

segment 與 link網絡結構:對segments的預測:2個segment score和5個geometric offsets為**default box:本文每個feature map的每個位置只采用了一個aspect ratio=1的default box,而SSD中是一系列(1, 2, 3, 1/2, 1/3).default box scale size:本文的是根據當前層的感受野來進行設置scale size,而SSD是通過人工設定的. 對于link的預測包括同層(within-layer link)的和跨層(cross-layer link)的兩種: 對于conv4_3層,對于feature map的每個位置需要預測其link輸出的維度為2*8(文中對feature map中每個位置只預測一個segment,所以8就是當前層8鄰域)=16;對于conv7, conv8_2, conv9_2, conv10_2, conv11其輸出的link維度為2*8(8是當前層8鄰域)+2*4(4是上一層4鄰域)=24
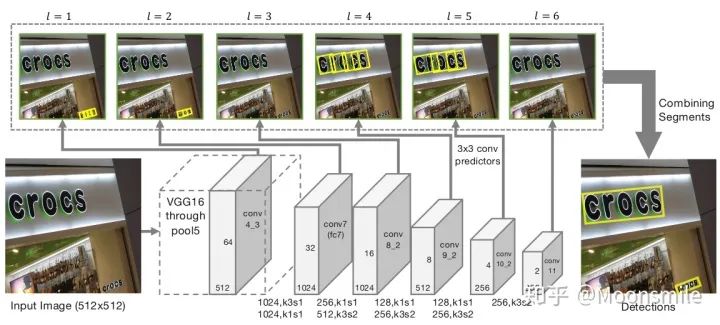
主框架
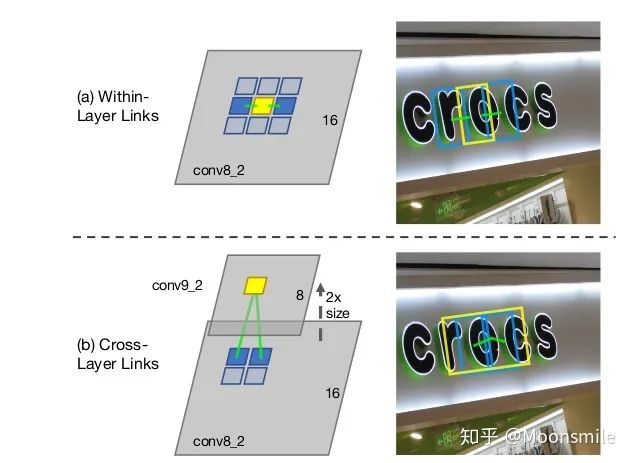
within-layer link 和cross-layer link 可視化圖網絡最后總共輸出通道數為31,如下圖:
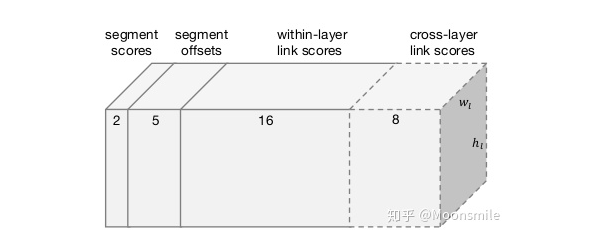
網絡最后總共輸出通道數Combining Segments with Links算法預測出Segment 和 Link 之后,需要用一種算法將預測出的Segments組合起來或者叫連接起來. 作者的算法是:首先通過人工設定的 α 和β(這兩個值是采用網格搜索找到最優),對網絡預測的segments和links進行濾除. 然后將每個segment看成node,link看成edge,建立圖模型,再用DFS(depth first search)找到連通分量,每個連通分量包含一系列segments(用B表示). 最后,輸出連接segments后的文本框的算法如下:

連接segments成一個框損失函數:包含三部分,segment classification loss (softmax),offsets regression loss (L1 regression),link classification loss (softmax).
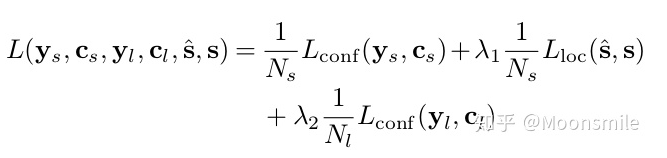
實驗結果:
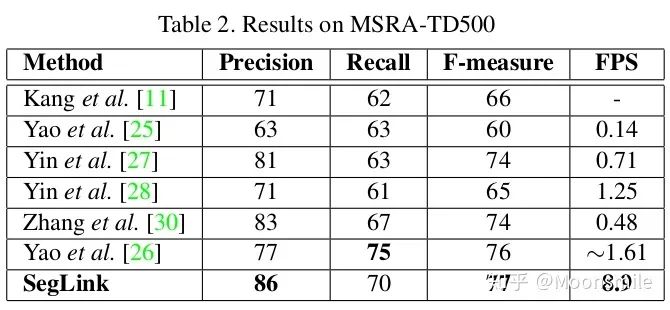
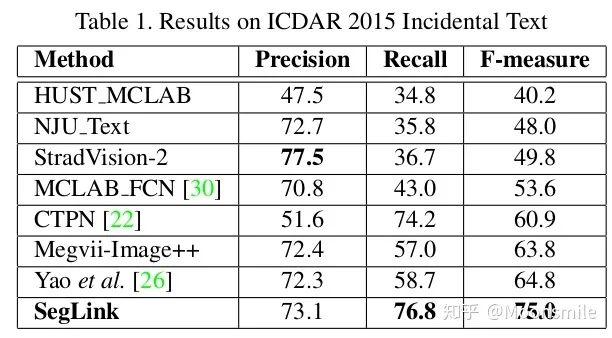

總結分析:缺點: 間隔較大的文字塊不能檢測出來,比較link只是針對鄰域的.Github 開源代碼:https://github.com/dengdan/seglink https://github.com/bgshih/seglink4、TextBoxes(TextBoxes: A Fast Text Detector with a Single Deep Neural Network)AAAI 17這篇文章的主要貢獻提出了一個快速而精確的文本檢測器,叫做TextBoxes,也是在SSD的基礎上進行改進的。相對SSD的改變如下四點:1、修改了default box的apect ratio,分別為[1 2 3 5 7 10],變成長條狀。 2、修改classifier卷積核的大小為1*5,而SSD中卷積核的大小為3*3,這樣更適合文本檢測。 3、提出了一個端到端的訓練框架.在測試的時候,輸入圖像由單尺度變成了多尺度 。 4、利用識別來調整檢測的結果。
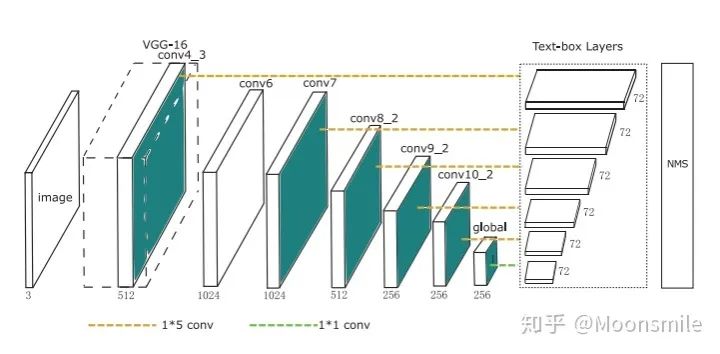
主框架 TextBoxes是一個28層的全連接卷積網絡,從主框架中可以看出,使用了1*5的卷積核,在每一個特征位置,預測一個72維的向量,因為每一個特征位置會有12個默認框(12個框怎么來的呢,首先有6種比例就有六個框,但是論文中指出了,為了防止水平方向的框太過密集,而垂直方向稀疏,所以每個默認框都設有一個垂直方向的偏移,相當于框的數量翻了一倍,如下下圖默認框圖所示)。72維(12*2+12×4)包括文本出現的得分(2維)和12個默認盒子的偏移(offsets)(4層)。
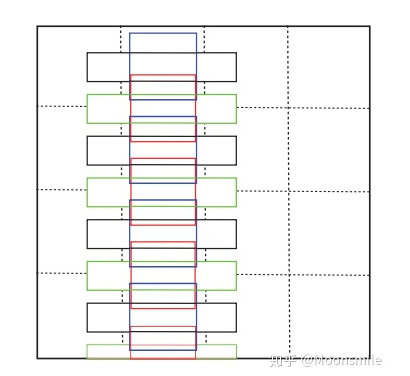
默認框圖,這里只展示了兩種比例(1和5的)損失函數:見下文TextBoxes++,與其相同。
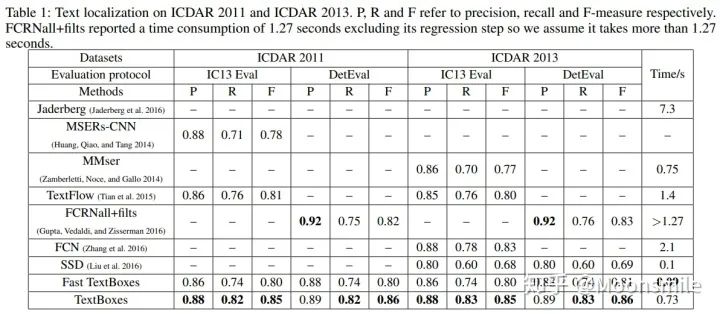
實驗數值結果

實驗效果圖,包含成功案例和失敗案例分析總結:不能檢測任意方向文本塊.Github 開源代碼:https://github.com/gxd1994/TextBoxes-TensorFlow https://github.com/shinjayne/shinTB5、R2CNN(R2CNN: Rotational Region CNN for Orientation Robust Scene Text Detection)CoRR 17這篇文章提出了一種旋轉區域CNN (Rotational Region CNN,R2CNN),用于檢測自然場景圖片中任意方向的文本框,當然這種方法并不局限于斜框文字檢測,也可以用在其他領域。 傾斜四邊形如何表示,下邊這邊文章中寫的比較清楚了,這篇文章用矩形的兩個坐標點和矩形的高(x1,y1,x2,y2,h)來表示: stone:基于Faster RCNN的斜框檢測:R2CNN https://zhuanlan.zhihu.com/p/41662351

網絡架構:
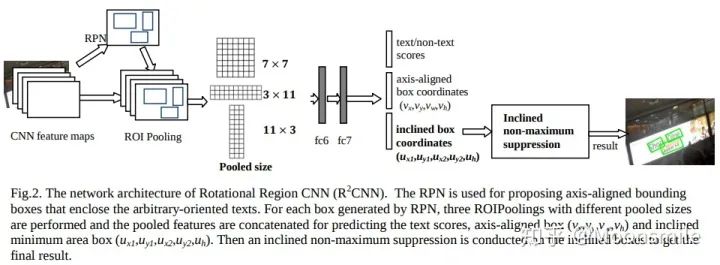
主框架第一步:通過RPN網絡,得到正框的Proposal,并且把anchor的大小從(8,16,32)改為(4,8,16,32) 或 (4,8,16),論文里說了,將anchor調小對檢測是有幫助的。第二步:ROIPooling,使用了不同pooled size (7 × 7, 11 × 3, 3 × 11) 的 ROIPooling,將三種結果concate在一起,再經過fc6,fc7進行正框預測,斜框預測以及分類預測,之后,再通過斜框的NMS進行后處理。 作者在論文里指出,每一個傾斜框都跟一個正框相關聯,如下圖中的(a)與(c),之所以既要對正框預測,又要對斜框預測,作者認為這能提升實驗的效果。

斜NMS 斜NMS算法參考Arbitrary-Oriented Scene Text Detection via Rotation Proposals損失函數:包含分類損失和回歸損失,回歸損失又包含正框和斜框兩部分。
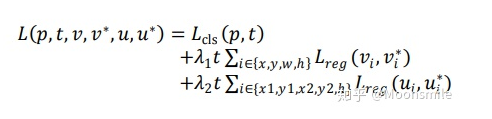
loss實驗結果:在精度上超過EAST和Seglink.
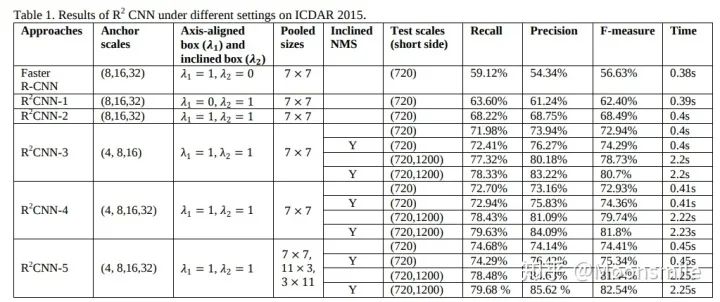
在不同參數設定下,R2CNN的結果比較
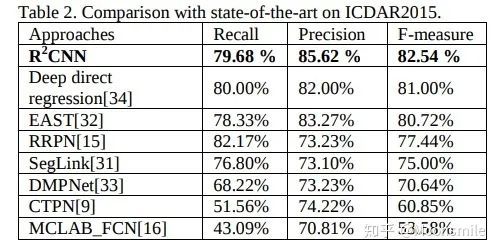
在ICDAR 2015數據集上的實驗結果
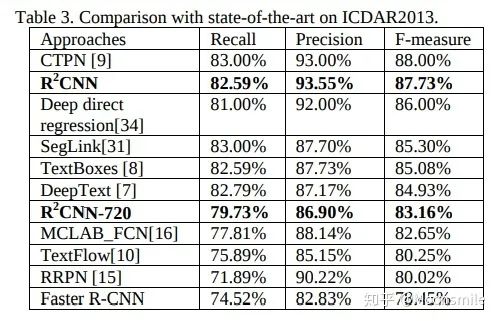
在ICDAR 2013數據集上的實驗結果 在ICDAR 2013數據集上的實驗結果,作者認為效果沒有超過sota的原因是由于他們使用的訓練數據不包含單個字符,如果包含,將可能會超過sota。總結分析:對斜的小的目標可能效果好一點Github 開源代碼:https://github.com/yangxue0827/R2CNN_FPN_Tensorflow https://github.com/DetectionTeamUCAS/R2CNN_Faster-RCNN_Tensorflow6、TextBoxes++(TextBoxes++: A Single-Shot Oriented Scene Text Detector)TIP 18從論文名字就可以看出,TextBoxes++是對TextBoxes的改進。
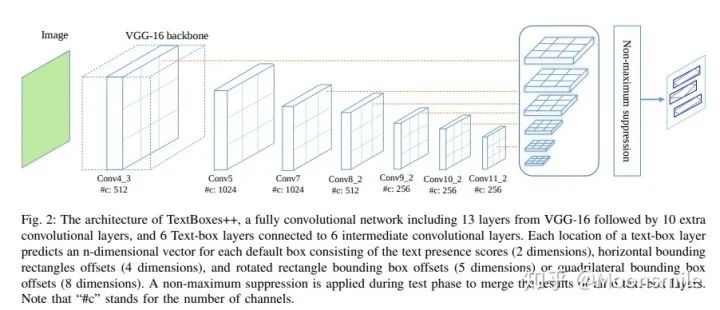
主框架相對TextBoxes的改變如下:1、對文本框的表示方式進行了改進。 在TextBoxes中,default box 是水平的框,不能檢測傾斜的文字。論文中討論了兩種表示方式:分別是4個點坐標(x1,y1,x2,y2,x3,y3,x4,y4)(四邊形)和兩個點的坐標外加四邊形的高(x1,y1,x2,y2,h)(傾斜矩形)。但論文推薦使用四個坐標的表示方式。四邊形和矩形表示的計算方法如下:

四邊形和矩形表示的計算方法 其中(x0,y0)是default box的中心點,(w0,h0)是default box的寬度和高度。 在每個feature map后的text-box layer將預測每個box上的文本存在概率以及位置偏置,以傾斜矩形為例,其預測輸出為: 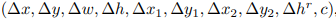 預測輸出 根據預測輸出,計算檢測框的坐標和高度,公式如下(傾斜矩形形式):
預測輸出 根據預測輸出,計算檢測框的坐標和高度,公式如下(傾斜矩形形式):
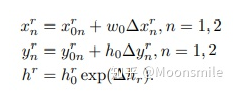
計算坐標和高度

從默認框回歸的過程 在TextBoxes++中,也為文本設置了垂直偏移,使得默認框在垂直方向密集,如下圖所示,沒有垂直偏移的只有黑色虛線框,就會漏掉很多連續的垂直方向文本。黃色虛線框是加入了垂直偏移后的,文本信息都被包圍了進去(本人覺得這里的作圖太過于刻意了,說服力并不是很強)。

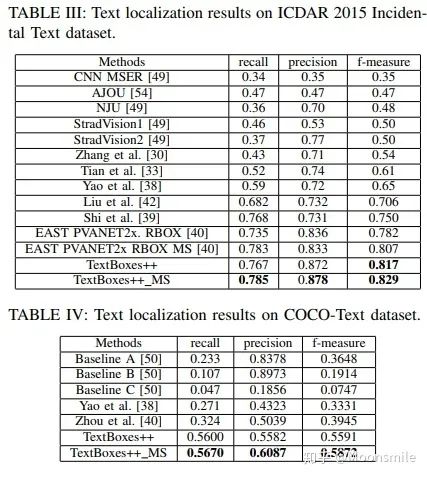
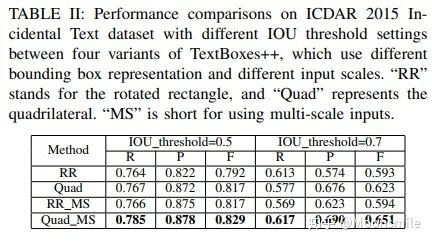
垂直偏移 損失函數包含預測得分和預測定位兩部分損失(與TextBoxes相同): 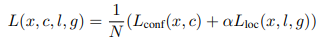 loss 其中,N是與GT匹配的default boxes數量,_α_設為0.2,對于分類用兩分類sotmax,對于定位用smooth L1。 此外,文章還用了On-line hard negative mining、數據增強、多尺度訓練、有效級聯NMS等技巧。實驗結果:從ICDAR和COCO-text的實驗數值上對比可以看出,這篇18年的文章已經完全干掉了17年的 EAST。
loss 其中,N是與GT匹配的default boxes數量,_α_設為0.2,對于分類用兩分類sotmax,對于定位用smooth L1。 此外,文章還用了On-line hard negative mining、數據增強、多尺度訓練、有效級聯NMS等技巧。實驗結果:從ICDAR和COCO-text的實驗數值上對比可以看出,這篇18年的文章已經完全干掉了17年的 EAST。
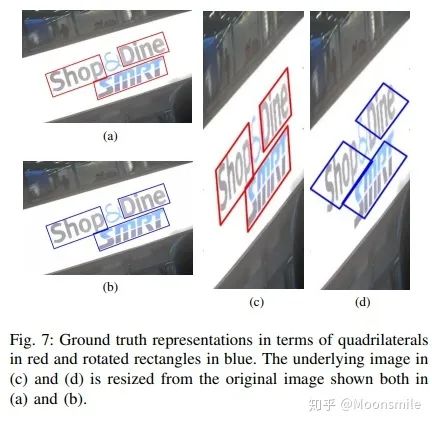
四邊形與傾斜矩形對比

可視化結果分析總結:對TextBoxes 不能檢測任意方向文本塊的缺點進行了改進,其精度已經完全干掉了頭一年的EAST.Github 開源代碼:https://github.com/Shun14/TextBoxes_plusplus_Tensorflow https://github.com/MhLiao/TextBoxes_plusplus7、FOTS(FOTS: Fast Oriented Text Spotting with a Unified Network)CVPR 18與前面幾篇只是檢測部分的不一樣,這篇論文是一個集合了文本檢測跟文字識別兩部分的一個統一的端到端的框架,可同時對圖像中的文字進行檢測跟識別。之前的大部分方法都是將檢測跟識別當做兩個獨立的任務去做,先檢測,再識別。這篇論文提出的框架處處是可微的,所以可以對其進行端到端的訓練,結果表明,該網絡無需復雜的后處理和高參數整定,易于訓練,并且在保證精度的前提下大大提高速度,如下圖所示:

可以看出,本文提出的統一的框架要比兩階段的方法快論文的主框架如下:
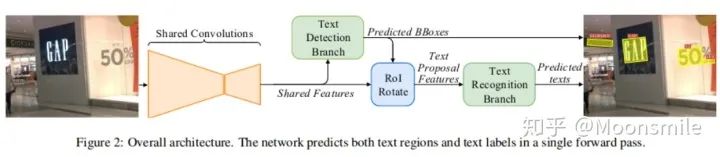
主框架 FOTS的整體結構由 shared convolutions,the text detection branch,RoIRotate operation,the text recognition branch 4部分組成。Shared Convolutions:FOTS的基礎網絡結構為Resnet50,共享卷積層采用了類似U-net的卷積的共享方法,將底層和高層的特征進行了融合。這部分和EAST中的特征共享方式一樣。最終輸出的特征圖大小為原圖的1/4,如下圖所示:
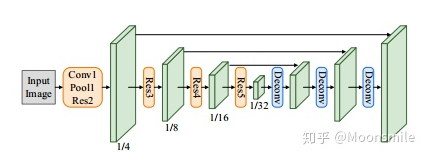
shared convolutionsText Detection Branch:該模塊和EAST一樣,采用了FCN作為文本檢測器,損失包含分類的loss(cross entrop)和坐標的回歸的loss(IOU loss+角度loss),公式如下:

RoIRotate:RoiRotate將變換應用于定向特征區域(有角度的),以獲得軸對齊的特征映射,如下圖所示:

特征區域角度變換 RoiRotate計算公式如下:

M是放射矩陣,包含旋轉,縮放,平移 使用變換參數,可以使用仿射變換輕松生成最終的roi特征:
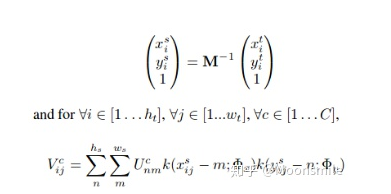
這里的幾個公式涉及到很多參數的概念,涉及到雙線性插值,更具體的含義請看論文 :仿射變換矩陣,包含旋轉,縮放,平移 :仿射變換后的特征圖的高度,實驗中為8 :仿射變換后的特征圖的寬度 :特征圖中的點的坐標 :特征圖中的點距離旋轉的框的上下左右的距離 :檢測框的角度 :在位置(i,j),通道c處的輸出值。 :在位置(n,m),通道c處的輸入值。 :輸入的高度 :輸入的寬度 總之,經過變換之后,我們可以獲得變換后的特征圖,然后將該特征圖輸入到 Text Recognition Branch進行識別。Text Recognition Branch:這個分支使用共享卷基層的特征和變換后的特征來識別文字,其結構類似CRNN結構,使用了類似VGG的順序卷積,一個雙向LSTM,最后再接CTC解碼器,對CRNN和CTC不熟悉的可先看: 白裳:一文讀懂CRNN+CTC文字識別 https://zhuanlan.zhihu.com/p/43534801
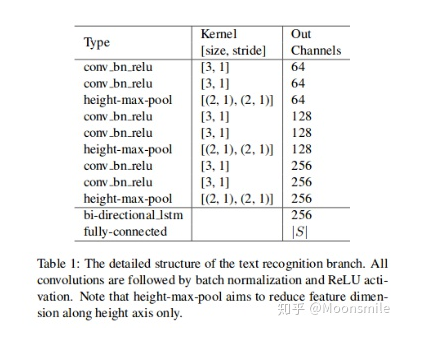
Text Recognition Branch Structure實驗結果:精度上可以說是很不錯了
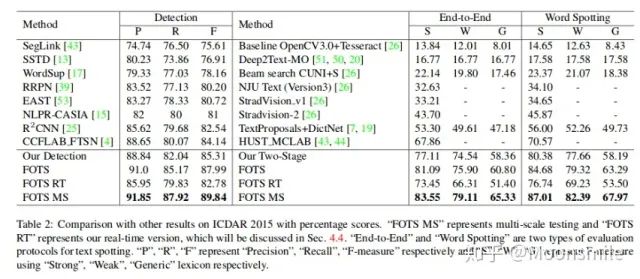
On ICDAR 2015
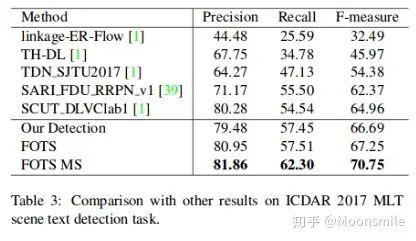
On ICDAR 2017
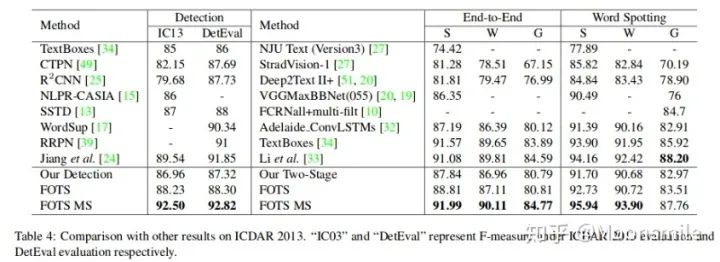
On ICDAR 2013
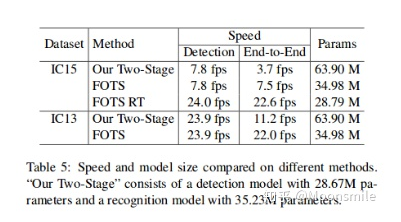
速度和模型大小比較總結分析:精度高,速度相對也比較快Github 開源代碼:https://github.com/jiangxiluning/FOTS.PyTorch https://github.com/xieyufei1993/FOTS https://github.com/Pay20Y/FOTS_TF8、PixelLink(PixelLink: Detecting Scene Text via Instance Segmentation)AAAA 18通過前邊的文章我們可以發現,對文本的檢測大都采用邊框回歸的思想來做,而這篇文章提出了不一樣的方法,文章提出采用實例分割的方法分割出文本行區域,然后直接找對應文本行的外接矩形框,這樣就實現了對文本的檢測。 但是,通常文本之間挨得很近,很難將他們分割開來,如圖所示:

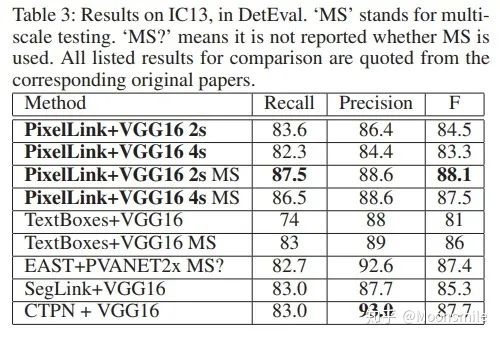
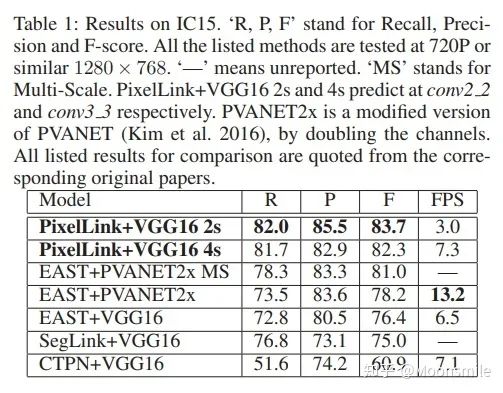
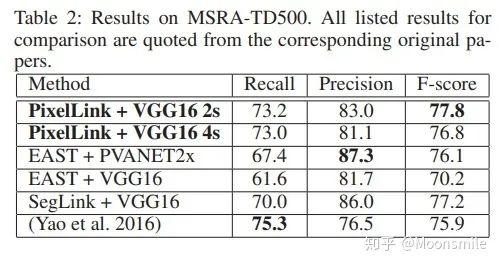
接下來我們就看看這篇文章是如何做的......框架結構:主干網絡是沿用了SSD網絡結構,用VGG16作為base net,并將VGG16的最后兩個全連接層改成卷積層; 論文中給出了兩種網絡結構:PixelLink+VGG16 2s (特征圖大學下降為原圖的1/2)和PixelLink+VGG16 4s (特征圖大小下降為原圖的1/4)。
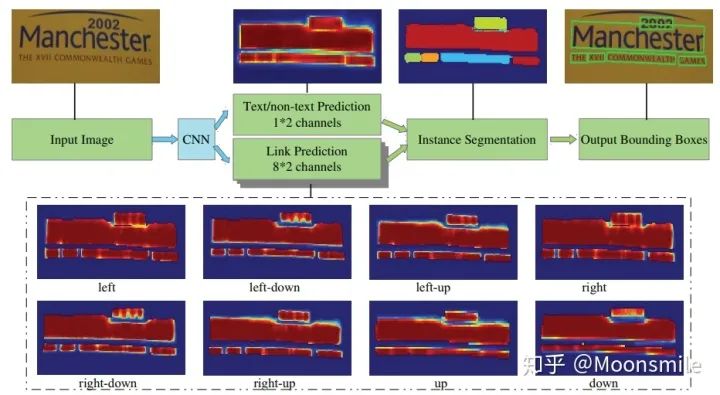
主框架 1、提取不同層的feature map,對于PixelLink+VGG16 2s網絡結構:提取了conv2_2, conv3_3, conv4_3, conv5_3, fc_7. 2、對已提取的特征層,采用自頂向下的方法進行融合,融合操作包括先向上采樣,然后再進行add操作.注意:這里包含了兩種操作:pixel cls和pixel link(文本/非文本預測和Link預測),所以對應的卷積核個數分別為2和16 。注意,fc6和fc7,被轉換為卷積層。
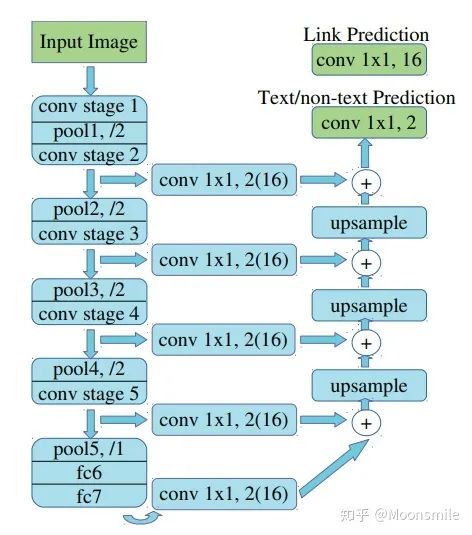
網絡結構連接像素:到這一步,我們已經得到了文本/非文本預測和Link預測,設定兩個閾值(一個用于像素分類,一個用于像素鏈接),可以得到pixel positive集合和link positive集合。然后根據link positive將pixel positive進行連接,得到CCs(conected compoents)集合(數字圖像處理中連通分量的概念),集合中的每個元素代表的就是文本實例。注意:給定兩個相鄰的pixel positive,它們之間的link預測是由當前兩個pixel共同決定的,兩個link中至少有一個是link positive。連接的規則采用的是Disjoint set data structure(并查集)的方法。外接矩形:直接使用Opencv里邊的minAreaRext提取文本的帶方向信息的外接矩形框。后期處理:在鏈接的過程可能引入噪聲,加入后期處理階段,可以通過矩形的長、寬、面積、長寬比信息等將一些明顯的錯的區域過濾掉,以提高檢測精度。損失函數:網絡的損失函數包含兩個部分:pixels loss和links loss: 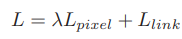 loss 損失函數的具體內容在此不展開討論,除了在損失函數上進行的設計,作者還借鑒了SSD里邊的數據增強的方法,具體的pixel loss 跟link loss如何設計以及如何生成訓練數據的ground truth可參考大佬寫的(我只是個搬運工): 燕小花:文本檢測之PixelLink https://zhuanlan.zhihu.com/p/38171172實驗結果:從數值結果從可以看出,確實比EAST強,但是好像沒有比Seglink強太多。
loss 損失函數的具體內容在此不展開討論,除了在損失函數上進行的設計,作者還借鑒了SSD里邊的數據增強的方法,具體的pixel loss 跟link loss如何設計以及如何生成訓練數據的ground truth可參考大佬寫的(我只是個搬運工): 燕小花:文本檢測之PixelLink https://zhuanlan.zhihu.com/p/38171172實驗結果:從數值結果從可以看出,確實比EAST強,但是好像沒有比Seglink強太多。
總結分析:優點:無需在imagenet上預訓練. 缺點:跟Seglink一樣,間隔較大的文字塊不能檢測出來.Github 開源代碼:https://github.com/ZJULearning/pixel_link https://github.com/cheerss/PixelLink-with-pytorch9、PSENet(Shape Robust Text Detection with Progressive Scale Expansion Network)CVPR 19文章的目的是要解決彎曲文字檢測的問題,如下圖所示,對于彎曲文字,現有方法存在較大的問題.

b中容易重疊,c中誤把多個實例識別成一個實例 作者認為現在的文本檢測主流方法可以分成regression-based和segmentation-based兩類,本文提出來的方法屬于segmentation-based.論文的三大特點:1、Segmentation-based方法能很好地解決任意形狀文本區域檢測這個問題,因為語義分割可以從像素級別上分割文字區域和背景區域. 2、對于如何分離靠的很近的文字塊,如上圖 (c) 所示,不能將他們分割開. 一個直觀的想法是增大文字塊之間的距離,使它們離得遠一點。基于這個思路,論文引入了新的概念 kernel. 3、有了kernel的概念, 作者通過一種基于廣度優先搜索的漸進擴展算法來構建完整的文字塊。這個方法的核心思想是:從每個kernel出發,利用廣度優先搜索來不斷地合并周圍的像素,使得kernel不斷地擴展,最后得到完整的文字塊。 下面就來看看這些特點具體是如何做的......Pipeline :框架的主干網絡是FPN,一張圖片通過FPN可以得到四個Feature Map (),然后通過函數合并這四個特征圖()得到.
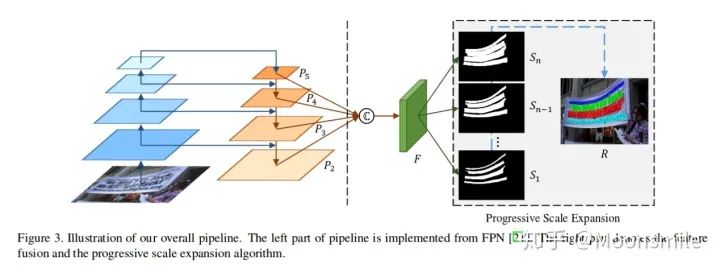
pipeline的具體公式如下:
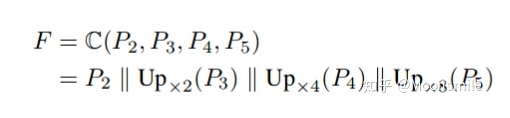
其中, || 代表 concatenation, U代表上采樣。 接著,通過來預測不同kernel scale的分割圖。其中是最小kernel scale的分割圖,里面不同的連通區域都可以看作不同文字塊的“kernel”。是最大kernel scale的分割圖,是個完整的文字快。最后通過一個漸進擴展算法(Progressive Scale Expansion)去不斷地擴展中的每個“kernel”.[1]漸進擴展算法(Progressive Scale Expansion):
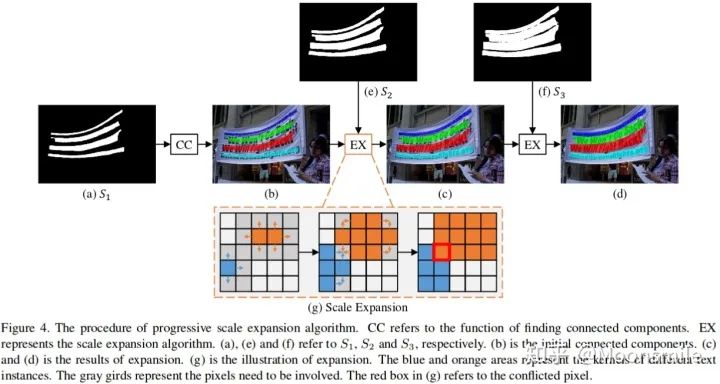
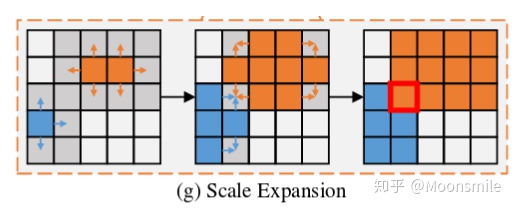
Progressive Scale Expansion 該算法的輸入是, 在上圖中以n=3為例, CC 代表尋找連通分量的操作, 對著上圖來分析: 1、首先,對求連通區域,得到不同文字塊的“kernel”。 2、然后,通過 (g)所示的擴展操作合并中的文字像素,得到擴展后的結果 (c)。最后,使用同樣的擴展操作合并中的文字像素,得到最后的文字塊(d)。 3、(g)所示的擴展操作是基于廣度優先搜索實現的。 我們可以把(g) 操作放大: 在邊界上有些像素點會混淆,不知道該屬于那個kernel, 在實踐中,處理沖突的原則是,混淆的像素可以在先到先得的基礎上由一個內核合并。
標簽生成 (Label Generation) :使用 Vatti clippingal gorithm 參考論文 generic solution to polygon clipping. 來生成不同核尺度的標簽.
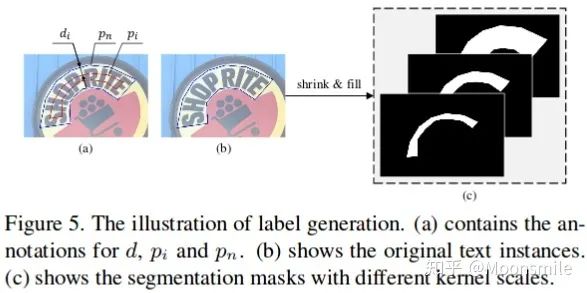
Label Generation損失函數和網絡結構細節:在此不細講,請參考原文:Shape Robust Text Detection with Progressive Scale Expansion Network實驗結果:
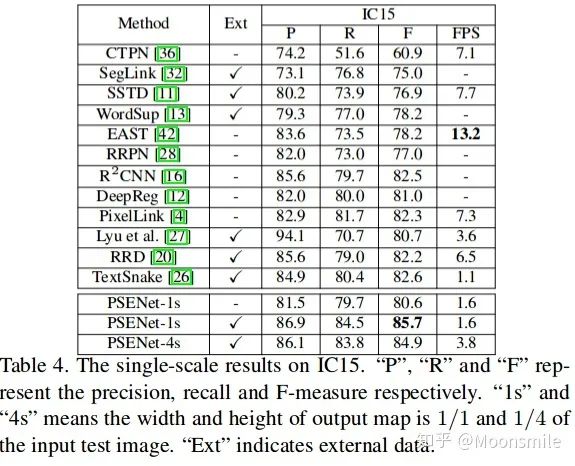
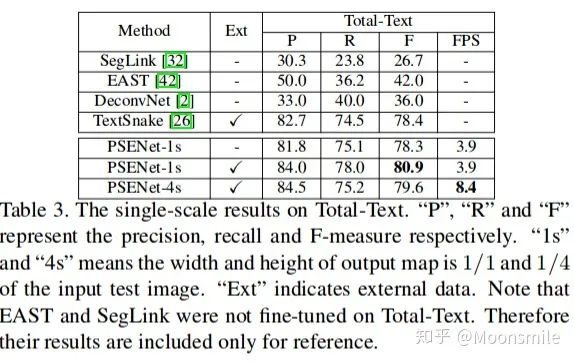
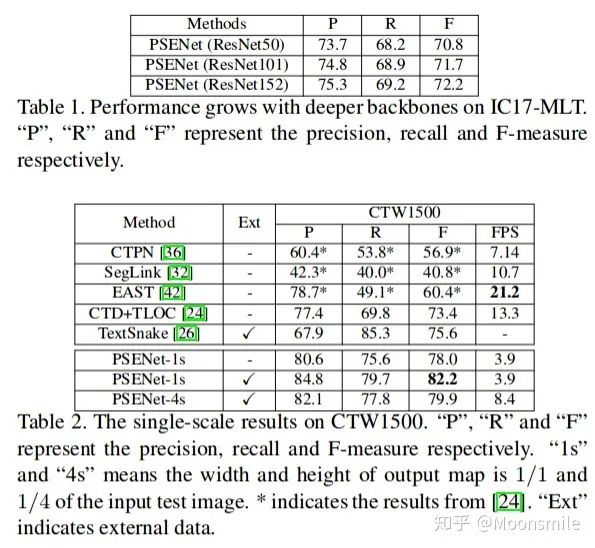
總結分析:總實驗數值結果可以看出,其檢測精度效果好,但是速度慢.Github 開源代碼:https://github.com/liuheng92/tensorflow_PSENet https://github.com/WenmuZhou/PSENet.pytorch https://github.com/liuheng92/tensorflow_PSENet 三、文本檢測算法demo運行展示 暫時略, 后續會補上。
責任編輯:lq
-
人機交互
+關注
關注
12文章
1213瀏覽量
55464 -
算法
+關注
關注
23文章
4626瀏覽量
93163 -
深度學習
+關注
關注
73文章
5511瀏覽量
121391
原文標題:一篇包羅萬象的場景文本檢測算法綜述
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
從萬象分區,一區頂多區,到靈控系統3.0,畫質&交互雙重絕殺!
TCL新技術引領視覺革命:萬象分區+絢彩XDR重塑Mini LED畫質標準!
TCL發布萬象分區技術,重塑Mini LED技術巔峰
解鎖高清時代:LP系列HDMI連接器帶你體驗4K/8K超清傳輸

錦浪高效逆變器解決方案賦能萬達廣場綠色升級
傳感萬象,智造未來!深視智能2024新品發布會完美收官!

萬象奧科參展“2024 STM32全國巡回研討會”—深圳站、廣州站

口罩佩戴檢測算法

人員跌倒識別檢測算法

安全帽佩戴檢測算法

2024百度移動生態萬象大會:百度新搜索11%內容已AI生成
5月30日百度移動生態萬象大會揭幕,大模型與智能體公眾開放
2024百度萬象大會:探討AI引領的商業未來
萬象奧科聯合RT-Thread舉辦RK3568+OpenAMP混合部署線下workshop!






 工商網監
工商網監
評論