") 用幾個(gè)深度學(xué)習(xí)框架串起來(lái)這些年歷史上的一些有趣的插曲
用幾個(gè)深度學(xué)習(xí)框架串起來(lái)這些年歷史上的一些有趣的插曲
和深度學(xué)習(xí)框架打交道已有多年時(shí)間。從Google的TensorFlow, 到百度的PaddlePaddle,再到現(xiàn)在騰訊的無(wú)量。很慶幸在AI技術(shù)爆發(fā)的這些年橫跨中美幾家公司,站在一個(gè)比較好的視角看著世界發(fā)生巨大的變化。在這些經(jīng)歷中,視角在不斷切換,從最早的算法研究,到后來(lái)的框架開發(fā),到機(jī)器學(xué)習(xí)平臺(tái)和更多基礎(chǔ)架構(gòu),每一段都有不同的感受和更深的領(lǐng)悟。
清明節(jié)這幾天有些時(shí)間寫了這篇文章,從我的視角,用幾個(gè)深度學(xué)習(xí)框架串起來(lái)這些年歷史上的一些有趣的插曲,和技術(shù)背后的一些故事,免得寶貴的記憶隨著時(shí)間在腦中淡去。
入門
故事開始在2015年底,我結(jié)束了在Google Core Storage和Knowledge Engine的工作,加入了Google Brain,在Samy Bengio下?lián)我幻鸕esearch Software Engineer,簡(jiǎn)稱RSWE。RSWE角色的產(chǎn)生主要是因?yàn)镚oogle Brain和DeepMind發(fā)現(xiàn)Research Scientist很難在研究中解決復(fù)雜的工程問(wèn)題,并最終技術(shù)落地。因此需要卷入一些工程能力比較強(qiáng)的Engineer和Scientist一起工作。而我比較“幸運(yùn)”的成為Google Brain第一個(gè)RSWE。
加入新組的前一個(gè)周末,非常興奮的提前探訪了Google Brain的辦公地點(diǎn)。想到能近距離在Jeff Dean旁邊工作還是有些小激動(dòng),畢竟是讀著MapReduce, BigTable, Spanner那些論文一路成長(zhǎng)起來(lái)的。辦公場(chǎng)所沒(méi)有特別,Jeff和大家一樣坐在一起,比較意外的是發(fā)現(xiàn)我工位旁幾米的辦公室門牌上寫著谷歌創(chuàng)始人Larry Page&Sergey Brin,辦公室被許多獎(jiǎng)杯,證書,太空服之類的雜物包圍著。看來(lái)公司對(duì)于AI技術(shù)的重視程度真實(shí)非常的高。
言歸正傳,早期的TensorFlow比較缺模型示例,相關(guān)API文檔還不太規(guī)范,于是先開始給TensorFlow搭建模型庫(kù)。我花了一年時(shí)間把Speech Recognition, Language Model, Text Summarization, Image Classification, Object Detection, Segmentation, Differential Privacy, Frame Prediction等模型寫了一遍,后來(lái)成為TensorFlow github上model zoo的雛形。那年還是個(gè)到處都是低垂果實(shí)的時(shí)候,沒(méi)有GPT3這種極其燒錢的大模型,只要對(duì)模型做一些小的調(diào)整,擴(kuò)大模型的規(guī)模,就能刷新State-Of-The-Art。Bengio大佬經(jīng)常在世界各地云游,偶爾回來(lái)后的1v1還是能給我不少的指引。印象深刻的第一次面聊,這位寫過(guò)幾百篇論文的一字眉大神給剛剛?cè)腴T的我在白板上手推了gradient descent的一些公式。另外一次1v1,他發(fā)給我一本Ian Goodfellow寫的書(當(dāng)時(shí)還是草稿pdf),然后我每天晚上就躺在茶水間的沙發(fā)上一邊做實(shí)驗(yàn)一邊讀書。
那年還發(fā)生了件有意思的插曲,AlphaGo大戰(zhàn)人類棋手。DeepMind和Brain有非常緊密的合作關(guān)系,組里組織了一輪paper reading,仔細(xì)研讀了相關(guān)的paper,然后大家?guī)掀【坪土闶辰M織了觀戰(zhàn)活動(dòng),感覺(jué)就有點(diǎn)像是在看球賽。那次學(xué)會(huì)了兩件事,強(qiáng)化學(xué)習(xí)算法,還有圍棋的英文是Go。
16年是TensorFlow高速發(fā)展的一年。Jeff的演講里經(jīng)常有TensorFlow代碼被引用次數(shù)指數(shù)級(jí)暴漲的圖。但是16年也是TensorFlow被噴的比較慘的一年。TF的Operator粒度是非常細(xì)的,據(jù)說(shuō)這是從內(nèi)部上一代框架DistBelif上吸取的教訓(xùn)。細(xì)粒度的Operator可以通過(guò)組合形成各種高層的Layer,具有更好的靈活性和擴(kuò)展性。然而,對(duì)于性能和易用性來(lái)說(shuō)卻是比較嚴(yán)重的問(wèn)題,一個(gè)模型隨便就有幾千個(gè)甚至跟多的Operator。舉幾個(gè)例子:
當(dāng)時(shí)我要實(shí)現(xiàn)第一個(gè)基于TensorFlow的ResNet,光為了寫一個(gè)BatchNormalization(查了好幾個(gè)內(nèi)部版本竟然都有些問(wèn)題),需要通過(guò)5~10個(gè)細(xì)粒度的算子通過(guò)加減乘除的方式組裝起,1001層的ResNet有非常多的BatchNorm,整個(gè)ResNet有成千上萬(wàn)個(gè)Operator,可想而知,性能也不怎么樣。不久后我朋友Yao搞了個(gè)Fused BatchNormalization,據(jù)說(shuō)能讓整個(gè)ResNet提速好幾成。
BatchNormalization只是初級(jí)難度,做Speech Recognition時(shí)為了在Python層用TensorFlow完成BeamSearch也花了不少功夫。當(dāng)時(shí)寫了個(gè)End-to-End的模型,用的是Seq2Seq with Attention,能夠一個(gè)模型直接把聲音轉(zhuǎn)成文字。為了把搜索生產(chǎn)線上語(yǔ)音識(shí)別的數(shù)據(jù)訓(xùn)到最后收斂,用128個(gè)GPU整整花了2個(gè)月的時(shí)間。每天早上上班第一件事就是打開TensorBoard,放大后才能看到Loss又下降了那么一點(diǎn)點(diǎn)。
16年時(shí)TensorFlow訓(xùn)練模式主要是基于Jeff等幾位的Paper,基于參數(shù)服務(wù)器的異步訓(xùn)練是主流。訓(xùn)練速度線性擴(kuò)展性不錯(cuò),但是今天基于ring的同步訓(xùn)練在NLP,CV這些領(lǐng)域的聲音更響一些。記得第一次和Jeff單獨(dú)交流是關(guān)于Speech Recognition分布式訓(xùn)練的實(shí)驗(yàn)情況,加到128個(gè)GPU做異步訓(xùn)練基本能保證線性擴(kuò)展,但是基于SyncOptimizer的同步訓(xùn)練速度會(huì)慢很多。當(dāng)時(shí)Jeff問(wèn)了下收斂效果有沒(méi)有收到影響,我懵了一下,說(shuō)沒(méi)有仔細(xì)分析過(guò),趕緊回去查一下。順便八卦一下,Jeff真是非常瘦,握手的時(shí)候感覺(jué)幾乎就剩皮包骨了。
開發(fā)過(guò)一些模型后發(fā)現(xiàn)算法研究員其實(shí)還有不少痛點(diǎn)。1. 不知道怎么Profile模型。2. 不知道怎么優(yōu)化性能。為了解決這兩個(gè)問(wèn)題,我抽空寫了個(gè)tf.profiler。tf.profiler的原理比較簡(jiǎn)單,就是把Graph, RunMeta和一些其他的產(chǎn)物做一些分析,然后用戶可以通過(guò)CLI,UI或者python API快速的去分析模型的結(jié)構(gòu),Parameter, FLOPs, Device Placement, Runtime等屬性。另外還做了個(gè)內(nèi)部數(shù)據(jù)的抓取任務(wù),去抓算法研究員的訓(xùn)練任務(wù)的metrics,如果發(fā)現(xiàn)GPU利用率異常,網(wǎng)絡(luò)通行量過(guò)大,數(shù)據(jù)IO慢時(shí)會(huì)自動(dòng)發(fā)郵件提醒,并給出一些修改的建議。
讓一個(gè)專心搞算法研究的人寫一個(gè)白板的數(shù)學(xué)公式不難,但是讓他去搞明白復(fù)雜的任務(wù)配置,分布式系統(tǒng)里的性能、資源、帶寬問(wèn)題確是件很困難的事。無(wú)論多么牛的研究員都會(huì)問(wèn)為什么任務(wù)沒(méi)能跑起來(lái),是資源不夠還是配置不對(duì)。記得有天傍晚,人不多,Geoffrey Hinton大神突然走過(guò)來(lái)問(wèn)到Can you do me a favor?My job cannot start...(正當(dāng)我準(zhǔn)備答應(yīng)時(shí),Quoc Lee已經(jīng)搶先接單了,真是個(gè)精神的越南小哥。。。)
Moonshots
Google Brain每年會(huì)組織一次Moonshots提案,許多后來(lái)比較成功的項(xiàng)目都是這樣孵化出來(lái)的,比如AutoML,Neural Machine Translation等等。團(tuán)隊(duì)成員會(huì)提出一些當(dāng)時(shí)技術(shù)比較難達(dá)到的項(xiàng)目,大家組成類似興趣小組的形式投入到這些項(xiàng)目中。
現(xiàn)在火的一塌糊涂的AutoML有點(diǎn)因?yàn)樯虡I(yè)化或者其他原因,感覺(jué)已經(jīng)對(duì)原始的定義做了極大的拓展。當(dāng)時(shí)Brain孵化這個(gè)項(xiàng)目的時(shí)候有兩隊(duì)人在做LearningToLearn的項(xiàng)目,一個(gè)小隊(duì)希望通過(guò)遺傳算法來(lái)搜索更優(yōu)的模型結(jié)構(gòu),另一個(gè)小隊(duì)則決定使用強(qiáng)化學(xué)習(xí)算法搜索。遺傳算法小隊(duì)在使用資源時(shí)比較謹(jǐn)慎,通常只使用幾百個(gè)GPU。而另一個(gè)小隊(duì)則使用了幾千個(gè)GPU。最后強(qiáng)化學(xué)習(xí)小隊(duì)更早的做出了成果,也就是Neural Architecuture Search。而另一個(gè)小隊(duì)雖然后來(lái)使用更多的GPU也達(dá)到了類似的效果,但是要晚了不少。
一個(gè)比較有趣的插曲是Brain雖然很早就有幾萬(wàn)張GPU,但是每當(dāng)論文截稿的前一段時(shí)間總是不夠用,其中搞NAS的同學(xué)常常在郵件中被暗示。為了解決資源的分配問(wèn)題,領(lǐng)導(dǎo)們被卷入了一個(gè)非常長(zhǎng)的email,后來(lái)大概解決方案是每個(gè)人會(huì)被分配少量的高優(yōu)先級(jí)GPU和適量的競(jìng)爭(zhēng)級(jí)GPU資源。而NAS的同學(xué)因?yàn)橐呀?jīng)完成了資本的原始積累成為了一個(gè)很火的項(xiàng)目,得到了特批的獨(dú)立資源池。為了支持這個(gè)策略,我又開發(fā)了個(gè)小工具,現(xiàn)在回頭想想還挺吃力不討好的。
Pytorch
動(dòng)態(tài)圖
快速成長(zhǎng)的時(shí)間總是過(guò)得很快,Megan加入Brain后,我被安排向她匯報(bào),當(dāng)時(shí)的RSWE團(tuán)隊(duì)已經(jīng)有十幾人,而Google Brain也從幾十人變成了幾百人。
2017年初,經(jīng)Megan介紹,TensorFlow團(tuán)隊(duì)一位資深專家Yuan Yu找到我,問(wèn)有沒(méi)有關(guān)注Pytorch,約我調(diào)研后一塊聊聊。于是我就去網(wǎng)上搜集了一下Pytorch的資料,又試用了一下。作為一個(gè)TensorFlow的深度用戶,我的第一反應(yīng)就是Pytorch解決了TensorFlow很大的痛點(diǎn),用起來(lái)非常的“自然”。
和Yuan聊完后,我們快速的決定在TensorFlow上也嘗試支持類似Pytorch的imperative programming用法。Demo的開發(fā)過(guò)程還算比較順利,我大概花了一個(gè)多月的時(shí)間。記得當(dāng)時(shí)我把項(xiàng)目命名為iTensorFlow, short for imperative TensorFlow。(后來(lái)被改名成eager,感覺(jué)好奇怪)。
Demo的設(shè)計(jì)思路其實(shí)也不復(fù)雜:1. TensorFlow graph可以被切分成任意粒度的Subgraph,可以通過(guò)函數(shù)調(diào)用的語(yǔ)法直接執(zhí)行,2. TensorFlow對(duì)用戶透明的記錄執(zhí)行過(guò)程以用于反向梯度計(jì)算。給用戶的感覺(jué)就就類似Python native的運(yùn)行。
進(jìn)而產(chǎn)生幾個(gè)推導(dǎo):1. 當(dāng)Subgraph的粒度是operator時(shí),基本等價(jià)于Pytorch。2. 當(dāng)Subgraph粒度由多個(gè)operator組成時(shí),保留了graph-level optimization的能力,可以編譯優(yōu)化。
最后再埋個(gè)伏筆:1. tf.Estimator可以自動(dòng)的去融合Subgraph,形成更大的Subgraph。用戶在開發(fā)階段基于imperative operator-level Subgraph可以簡(jiǎn)單的調(diào)試。用戶在部署階段,可以自動(dòng)融合大的Subgraph,形成更大的optimization space。
做完之后,我非常興奮的和Yuan演示成果。Yuan也說(shuō)要幫我在TensorFlow里面推這個(gè)方案。當(dāng)時(shí)Pytorch的成長(zhǎng)速度非常的快,TensorFlow的Director也召集了多名專家級(jí)的工程師同時(shí)進(jìn)行方案的探索。當(dāng)時(shí)我還沒(méi)能進(jìn)入TensorFlow的決策層,最終得到的結(jié)論是1. 讓我們成立一個(gè)虛擬組專門做這個(gè)項(xiàng)目。2. 之前的Demo全部推倒重新做,TensorFlow 2.0作為最重要Feature 發(fā)布,默認(rèn)使用Imperative Mode (后改名叫Eager Mode,中文常常叫動(dòng)態(tài)圖)。我則作為團(tuán)隊(duì)的一員在項(xiàng)目中貢獻(xiàn)來(lái)一些代碼。
后來(lái)Brain來(lái)了位新的大神,Chris Lattner,在編程語(yǔ)言和編譯領(lǐng)域研究的同學(xué)估計(jì)很多認(rèn)識(shí)他。他提出來(lái)希望用Swift來(lái)實(shí)現(xiàn)Deep Learning Model的Progamming,也就是后來(lái)的Swift for TensorFlow。理由大概是Python是個(gè)動(dòng)態(tài)的語(yǔ)言,很難靜態(tài)編譯優(yōu)化。后來(lái)我和他深入討論來(lái)幾次,從技術(shù)上非常贊同他的觀點(diǎn),但是也明確的表示Swift for TensorFlow是一條很難走的路。用Python并不是因?yàn)镻ython語(yǔ)言多么好,而是因?yàn)楹芏嗳擞肞ython。和Chris的一些交流中我對(duì)編譯過(guò)程中的IR和Pass有了更深的了解,對(duì)后來(lái)在PaddlePaddle中的一些工作產(chǎn)生了不少的影響。
一個(gè)插曲是某位TensorFlow團(tuán)隊(duì)的資深專家有次悄悄和我說(shuō):Python is such a bad language。這句話我品味了好久,不過(guò)和他一樣沒(méi)有勇氣大聲說(shuō)出來(lái)。。。
當(dāng)時(shí)動(dòng)態(tài)圖的項(xiàng)目還延展出兩個(gè)比較有趣的項(xiàng)目。有兩個(gè)其他團(tuán)隊(duì)的哥們想對(duì)Python做語(yǔ)法分析,進(jìn)而編譯control flow。我很委婉的表示這個(gè)方案做成通用解決方案的可能性不太大,但是這個(gè)項(xiàng)目依然被很執(zhí)著的做了很長(zhǎng)一段時(shí)間,并且進(jìn)行了開源,但是這個(gè)項(xiàng)目也就慢慢壽終正寢了。另一個(gè)很酷的項(xiàng)目是完全用numpy來(lái)構(gòu)造一個(gè)deep learning model。通過(guò)隱式的tape來(lái)完成自動(dòng)的求導(dǎo),后來(lái)項(xiàng)目好像逐漸演化成來(lái)JAX項(xiàng)目。
API
后面我逐漸轉(zhuǎn)到了TensorFlow做開發(fā)。記得2017年還發(fā)生了一件印象深刻的事情,當(dāng)TensorFlow收獲海量用戶時(shí),網(wǎng)上一篇“TensorFlow Sucks"火了。雖然那篇文章很多觀點(diǎn)我不能茍同,許多想法比較膚淺。但是,有一點(diǎn)不能否認(rèn),TensorFlow API是比較讓人蛋疼的。1. 同一個(gè)功能往往幾套重復(fù)的API支持。2. API經(jīng)常變動(dòng),而且經(jīng)常發(fā)生不向后兼容的問(wèn)題。3. API的易用性不高。
為什么會(huì)發(fā)生這個(gè)問(wèn)題呢?可能要從Google這個(gè)公司的工程師文化說(shuō)起。Google是非常鼓勵(lì)自由創(chuàng)新和跨團(tuán)隊(duì)貢獻(xiàn)的。經(jīng)常會(huì)有人給另一個(gè)團(tuán)隊(duì)貢獻(xiàn)代碼,并以此作為有影響力的論據(jù)參與晉升。所以在早期TensorFlow還不是特別完善的時(shí)候,經(jīng)常有外部的團(tuán)隊(duì)給TensorFlow貢獻(xiàn)代碼,其中就包含了API。另外,在Google內(nèi)部的統(tǒng)一代碼倉(cāng)庫(kù)下,放出去的API是可以很容易的升級(jí)修改的,很多時(shí)候只需要grep和replace一下就行。但是github上放出去的API完全不一樣,Google的員工不能去修改百度,阿里,騰訊內(nèi)部的TensorFlow使用代碼。對(duì)此TensorFlow團(tuán)隊(duì)早期的確沒(méi)有非常有效的方案,后來(lái)才出現(xiàn)了API Committee對(duì)public API做統(tǒng)一的把關(guān)和規(guī)劃。
在我做視覺(jué)的時(shí)候,和Google內(nèi)部一個(gè)視覺(jué)團(tuán)隊(duì)有過(guò)很多合作,其中一個(gè)是slim API。這個(gè)視覺(jué)團(tuán)隊(duì)非常的強(qiáng),當(dāng)年還拿了CoCo的冠軍。隨著他們模型的推廣流行,他們的tf.slim API也被廣為流傳。slim API的arg_scope使用了python context manager的特性。熟悉早期TensorFlow的人知道還有tf.variable_scope, tf.name_scope, tf.op_name_scope等等。with xxx_scope一層套一層,復(fù)雜的時(shí)候代碼幾乎沒(méi)有什么可讀性。另外就是各種global collection,什么global variable, trainable variable, local variable。這在傳統(tǒng)的編程語(yǔ)言課里,全局變量這種東西可能是拿來(lái)當(dāng)反面教材的。然而,算法人員的視角是不一樣的,with xxx_scope和global collection能減少他們的代碼量。雖然我們知道合理的程序設(shè)計(jì)方法也可以做到,但是算法專家估計(jì)需要把時(shí)間用來(lái)讀paper,不太愿意研究這些程序設(shè)計(jì)的問(wèn)題。
記得在早期內(nèi)部還有兩個(gè)流派的爭(zhēng)論:面向?qū)ο蠛兔嫦蜻^(guò)程的API設(shè)計(jì)。
基于我教育歷史的洗腦,感覺(jué)這個(gè)是不需要爭(zhēng)論的問(wèn)題。Keras的Layer class和Pytorch的Module class這些面向?qū)ο蟮?a target="_blank">接口設(shè)計(jì)無(wú)疑是非常優(yōu)雅的。然而,其實(shí)當(dāng)時(shí)的確發(fā)生了非常激烈的爭(zhēng)論。一些functional API的作者認(rèn)為functional的調(diào)用非常節(jié)省代碼量:一個(gè)函數(shù)就可以解決的問(wèn)題,為什么需要先構(gòu)造一個(gè)對(duì)象,然后再call一下?
在TensorFlow動(dòng)態(tài)圖能力開發(fā)的早期,我們也反復(fù)討論了2.0里面接口的設(shè)計(jì)方案。作為炮灰的我又接下了寫Demo的工作。
閉關(guān)兩周后,我給出了一個(gè)方案:1. 復(fù)用Keras的Layer接口。2. 但是不復(fù)用Keras的Network,Topology等其他更高層的復(fù)雜接口。
原因主要又兩點(diǎn):1. Layer是非常簡(jiǎn)潔優(yōu)雅的,Layer可以套Layer,整個(gè)網(wǎng)絡(luò)就是一個(gè)大Layer。Layer抽象成construction和execution兩階段也非常自然。2. Keras有很多歷史上為了極簡(jiǎn)設(shè)計(jì)的高層接口。我個(gè)人經(jīng)驗(yàn)覺(jué)得很難滿足用戶靈活的需求,并不需要官方提供。而且這樣可能會(huì)導(dǎo)致TensorFlow API層過(guò)度復(fù)雜。
后來(lái)方案被采納了一半,大佬們希望能夠更多的復(fù)用Keras接口。其實(shí)沒(méi)有完美的API,只有最適合某類人群的API。有個(gè)小插曲,當(dāng)時(shí)Keras的作者Fran?ois也在Google Brain。為了在TensorFlow 2.0的動(dòng)態(tài)圖和靜態(tài)圖同時(shí)使用Keras的接口,不得不在Keras API內(nèi)做很多改造。通常Fran?ois在Review代碼時(shí)都非常的不情愿,但是最后又往往妥協(xié)。很多時(shí)候,特別是技術(shù)方面,真相可能在少數(shù)不被大多數(shù)人理解的人手上,需要時(shí)間來(lái)發(fā)現(xiàn)。
TPU
感覺(jué)互聯(lián)網(wǎng)公司那幾年,真正把AI芯片做得成熟且廣泛可用的,只有Google一家。TPU一直都是Google Brain和TensorFlow團(tuán)隊(duì)關(guān)注的重點(diǎn)。原因可能是Jeff老是提起這件事,甚至一度在TensorFlow搞GPU優(yōu)化是件很沒(méi)前途的事情。
TPU有個(gè)比較特別的地方,在于bfloat16的類型。如今bfloat16,還有英偉達(dá)最新GPU上的TF32都已經(jīng)被廣為了解了。在當(dāng)時(shí)還是個(gè)不小的創(chuàng)新。
bfloat16的原理非常簡(jiǎn)單,就是把float32的后16bit全部截掉。和IEEE的float16相比,bfloat16的mantissa bits會(huì)少一些,但是exponential bits會(huì)多一些。保留更多的exponential bits有利于gradients很接近0時(shí)不會(huì)消失,保證bfloat16訓(xùn)練時(shí)能夠更好的保留模型的效果。而傳統(tǒng)基于float16訓(xùn)練時(shí),往往需要做loss scaling等調(diào)試才能達(dá)到類似的效果。因此bfloat16能讓AI芯片更快的運(yùn)算,同時(shí)又確保收斂效果通常不會(huì)有損失。
為了在TensorFlow上全面的支持bfloat16,我當(dāng)時(shí)花了不少的功夫。雖然之前有基于bfloat16通信的方案,但是要在所有地方都無(wú)縫打通bfloat16,還有非常多的工作要做。比如eigen和numpy都不支持bfloat16這種特殊的東西。幸好他們都可以擴(kuò)展數(shù)據(jù)類型(就是文檔太少了)。然后還要修復(fù)成百上千個(gè)fail掉的unit tests來(lái)證明bfloat16可以在python層完備的使用。
TPU是一個(gè)非常高難度,跨團(tuán)隊(duì),跨技術(shù)棧的復(fù)雜工程。據(jù)說(shuō)Google有位非常優(yōu)秀的工程師,為了在TPU上支持depthwise convolution一個(gè)TPU kernel,花掉了半年的時(shí)間。
其實(shí)這一點(diǎn)也不夸張,除了底層的硬件設(shè)計(jì),單是將tensorflow graph編譯成硬件binary的XLA項(xiàng)目早期就至少卷入幾十人。從HLO到底層的target-specific code generation,幾乎又重寫了一遍TensorFlow C++層,遠(yuǎn)比之前的解釋型執(zhí)行器復(fù)雜。
TPU的訓(xùn)練在底層跑通后,我基于底層接口的基礎(chǔ)上完成Python層的支撐API,然后去實(shí)現(xiàn)幾個(gè)模型。當(dāng)時(shí)碰到了好幾個(gè)難題,有些在幾周時(shí)間內(nèi)解決了,有些持續(xù)到我不再團(tuán)隊(duì)后好些年。這里舉幾個(gè)例子。
當(dāng)時(shí)一個(gè)TPU Pod(好像是512個(gè)chips)算得太快了,即使是很復(fù)雜模型的計(jì)算也會(huì)卡在數(shù)據(jù)的IO和預(yù)處理上。后來(lái)搞了個(gè)分布式的data processing,通過(guò)多個(gè)CPU機(jī)器來(lái)同時(shí)去處理數(shù)據(jù),才能喂飽TPU。
早器的TPU API易用性比較弱。通常一個(gè)model需要在TPU上train幾百步然后再返回python層,否則TPU的性能會(huì)飛快的退化。這對(duì)于算法人員是很不友好的,這意味著debug能力的缺失,以及大量復(fù)雜模型無(wú)法實(shí)現(xiàn)。記得當(dāng)年OKR被迫降低為支持常見(jiàn)的CV模型。
TPU如何支持動(dòng)態(tài)圖。記得我當(dāng)時(shí)迫于TPU的約束,做了個(gè)所謂的JIT的能力。就是Estimator先在CPU或者GPU上迭代N步,完成模型的初步調(diào)試,然后再自動(dòng)的deploy到TPU上。從算法人員角度,既滿足單步調(diào)試的能力,又能在主要training過(guò)程用上TPU。
團(tuán)隊(duì)
Google Brain是個(gè)很神奇的團(tuán)隊(duì),比較不客氣的說(shuō),在2015年后的幾年間包攬了全世界在深度學(xué)習(xí)領(lǐng)域一半以上的關(guān)鍵技術(shù)突破,比如TPU,TensorFlow, Transformer, BERT, Neural Machine Translation, Inception, Neural Architecture Search, GAN,Adverserial Training, Bidrectional RNN等等。這里不只有深度學(xué)習(xí)領(lǐng)域的圖靈獎(jiǎng)獲得者,還有編程語(yǔ)言、編譯器、計(jì)算機(jī)體系結(jié)構(gòu)、分布式系統(tǒng)的頂級(jí)專家,甚至還有生物,物理學(xué)專家。Jeff將這些人放在一起后,發(fā)生了神奇的化學(xué)反應(yīng),加快了技術(shù)改變世界的步伐。
PaddlePaddle 飛槳
Paddle其實(shí)誕生時(shí)間比較早,據(jù)說(shuō)是大約13~14年的時(shí)候徐偉老師的作品。后來(lái)?yè)?jù)說(shuō)Andrew Ng覺(jué)得Paddle叫一次不過(guò)癮,就改名成了PaddlePaddle。Paddle和那個(gè)年代的框架Caffe有類似的問(wèn)題,靈活性不夠。很多地方用C++寫成比較粗粒度的Layer,無(wú)法通過(guò)Python等簡(jiǎn)單的編程語(yǔ)言完成模型的快速構(gòu)造。
后來(lái)17年下半年,團(tuán)隊(duì)開始完全從新寫一個(gè)框架,但是繼承了Paddle的名字。2017年底的時(shí)候,Paddle國(guó)內(nèi)的團(tuán)隊(duì)找到了我,邀請(qǐng)我擔(dān)任Paddle國(guó)內(nèi)研發(fā)團(tuán)隊(duì)的負(fù)責(zé)人。抱著打造國(guó)產(chǎn)第一框架的理想,我接受了邀請(qǐng),一個(gè)月后就在北京入職了。
早期設(shè)計(jì)
加入團(tuán)隊(duì)的時(shí)候,新的Paddle還是一個(gè)比較早期的原型系統(tǒng),里面有一些設(shè)計(jì)已經(jīng)被開發(fā)了出來(lái)。我發(fā)現(xiàn)其中有些設(shè)計(jì)理念和TensorFlow有明顯的差異,但是實(shí)現(xiàn)的時(shí)候卻又模仿了TensorFlow。
仿編程語(yǔ)言
設(shè)計(jì)者希望設(shè)計(jì)一種編程語(yǔ)言來(lái)完成深度學(xué)習(xí)模型的構(gòu)建(有點(diǎn)類似Julia等把深度學(xué)習(xí)模型的特性嵌入到了編程語(yǔ)言中)。然而在實(shí)現(xiàn)上,我發(fā)現(xiàn)其實(shí)和TensorFlow比較類似。都是通過(guò)Python去聲明一個(gè)靜態(tài)模型結(jié)構(gòu),然后把模型結(jié)構(gòu)交給執(zhí)行器進(jìn)行解釋執(zhí)行。并沒(méi)有發(fā)明一種新的深度學(xué)習(xí)編程語(yǔ)言。
這塊我基本沒(méi)有對(duì)設(shè)計(jì)進(jìn)行調(diào)整。本質(zhì)上和TensorFlow早期靜態(tài)圖的沒(méi)有區(qū)別。但是在細(xì)節(jié)上,TF基于Graph的模型可以通過(guò)feed/fetch選擇性的執(zhí)行任意一部分子圖,更加靈活。Paddle中與Graph對(duì)應(yīng)的是Program。Program就像正常程序一樣,只能從頭到尾完整的執(zhí)行,無(wú)法選擇性的執(zhí)行。因此Paddle在這塊相對(duì)簡(jiǎn)化了一些,但是可以通過(guò)在Python層構(gòu)造多個(gè)Program的方式補(bǔ)全這部分靈活性的缺失,總體來(lái)說(shuō)表達(dá)能力是足夠的。
Transpiler
Transpiler是對(duì)Program進(jìn)行直接改寫,進(jìn)而可以讓模型能夠被分布式運(yùn)行,或者進(jìn)行優(yōu)化。初衷是比較好的,可以降低算法人員的使用難度。然而在實(shí)現(xiàn)上,最開始是在Python層直接對(duì)Program結(jié)構(gòu)進(jìn)行改寫。后來(lái)我從新設(shè)計(jì)了IR+Pass的Compiler體系,通過(guò)一種更系統(tǒng)性的方式做了實(shí)現(xiàn)。
LoDTensor
可能是因?yàn)閳F(tuán)隊(duì)的NLP和搜索背景比較強(qiáng),對(duì)于變長(zhǎng)序列的重視程度很高。Paddle的底層數(shù)據(jù)是LoDTensor,而不是類似其他框架Tensor。LoDTensor相當(dāng)于把變長(zhǎng)序列信息耦合進(jìn)了Tensor里面。這可能導(dǎo)致比較多的問(wèn)題,比如很多Operator是完全序列無(wú)關(guān)的,根本無(wú)法處理序列信息在輸入Tensor和輸出Tensor的關(guān)系,進(jìn)而比較隨機(jī)的處理,給框架的健壯性埋下隱患。雖然我一直想推動(dòng)序列信息和Tensor的解耦合,但是因?yàn)榉N種原因,沒(méi)有徹底的完成這個(gè)重構(gòu)的目標(biāo),希望后面能改掉。
性能
18年初的時(shí)候,Paddle還是個(gè)原型系統(tǒng)。由于OKR目標(biāo),團(tuán)隊(duì)已經(jīng)開始初步接入一些業(yè)務(wù)場(chǎng)景。其實(shí)一個(gè)比較大的痛點(diǎn)就是性能太差。單機(jī)單卡速度非常慢,單機(jī)4卡加速比只有1.x。但是性能問(wèn)題的定位卻非常困難。我花了些時(shí)間寫了些profile的工具,比如timeline。一些明顯的性能問(wèn)題可以被快速的定位出來(lái)并修復(fù)。
但是單機(jī)多卡的速度還是非常慢,timeline分析后發(fā)現(xiàn)其中有個(gè)ParallelOp,存在大量的Barrier。最后改寫成了ParallelExecutor,把Program復(fù)制了N份部署在多張卡上,在其中插入AllReduce通信算子,然后這N倍的算子基于圖依賴關(guān)系,不斷把ready的算子扔進(jìn)線程池執(zhí)行。即使這樣,我們也發(fā)現(xiàn)在多卡的性能上,不同模型需要使用不同的線程調(diào)度策略來(lái)達(dá)到最優(yōu)。很難有一種完美的one-fits-all的方案。后面我們?cè)倭娜绾瓮ㄟ^(guò)IR+Pass的方法插件化的支持不同的算子調(diào)度策略。
分布式的訓(xùn)練也碰到不少的問(wèn)題。一開始使用grpc,花了挺大的功夫做并行請(qǐng)求,然后又切成了brpc,在RDMA等方面做了不少的優(yōu)化。分布式訓(xùn)練的性能逐步得到了提升。另外為了做到自動(dòng)化分布式部署,前面提到的Transpiler隨著場(chǎng)景的增加,Python代碼也變得越來(lái)越復(fù)雜。

模型推理在公司內(nèi)碰到來(lái)非常強(qiáng)勁的對(duì)手。Anakin的GPU推理速度的確很快,讓我吃驚的是他們竟然是用SASS匯編完成大量基礎(chǔ)算子的開發(fā),針對(duì)Pascal架構(gòu)做了異常極致的優(yōu)化,甚至在某些場(chǎng)景遠(yuǎn)超TensorRT。我一直主張訓(xùn)練和推理要盡量用一樣的框架,并不需要一個(gè)單獨(dú)的推理框架來(lái)解決性能問(wèn)題。使用不同的框架做推理會(huì)造成很多意外的精度問(wèn)題和人工開銷。
因?yàn)橥评硇阅艿膯?wèn)題,我們和兄弟團(tuán)隊(duì)發(fā)生來(lái)曠日持久競(jìng)賽,作為狗頭軍事,我充分發(fā)揮來(lái)團(tuán)隊(duì)在CPU這塊的技術(shù)積累、以及和Intel外援的良好關(guān)系,在CPU推理場(chǎng)景常常略勝一籌。在GPU方面苦于對(duì)手無(wú)底線使用匯編,和我方戰(zhàn)線太多、人員不夠,只能戰(zhàn)略性放棄了部分頭部模型,通過(guò)支持子圖擴(kuò)展TensorRT引擎的方式,利用Nvidia的技術(shù)優(yōu)勢(shì)在許多個(gè)通用場(chǎng)景下展開進(jìn)攻。現(xiàn)在回想起來(lái)真實(shí)一段有趣的經(jīng)歷。
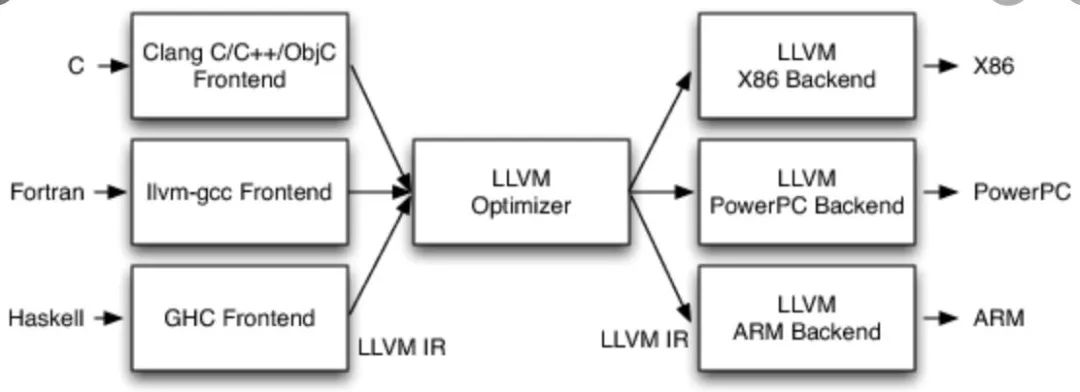
Imtermediate Representation&Pass
Imtermediate Representation+Pass的模式主要是從LLVM的架構(gòu)上借鑒來(lái)的。在編譯器上主要是用來(lái)解決把M個(gè)編程語(yǔ)言中任意一個(gè)編譯到N個(gè)硬件設(shè)備中任意一個(gè)執(zhí)行的問(wèn)題。簡(jiǎn)單的解決方案是為每個(gè)編程語(yǔ)言和硬件單獨(dú)寫一個(gè)編譯器。這需要M*N個(gè)編譯器。顯然這對(duì)于復(fù)雜的編譯器開發(fā)來(lái)說(shuō),是非常高成本的。
Intermediate Representation是架構(gòu)設(shè)計(jì)中抽象能力的典型體現(xiàn)。不同編程語(yǔ)言的層次不一樣,或者僅僅是單純的支持的功能有些差異。但是,這些編程語(yǔ)言終歸需要在某種硬件指令集上執(zhí)行。所以在編譯的過(guò)程中,他們會(huì)在某個(gè)抽象層次上形成共性的表達(dá)。而IR+Pass的方法很好的利用了這一點(diǎn)。其基本思想是通過(guò)多層Pass (編譯改寫過(guò)程),逐漸的把不同語(yǔ)言的表達(dá)方式在某個(gè)層次上改寫成統(tǒng)一的IR的表達(dá)方式。在這個(gè)過(guò)程中,表達(dá)方式逐漸接近底層的硬件。而IR和Pass可以很好的被復(fù)用,極大的降低了研發(fā)的成本。
深度學(xué)習(xí)框架也有著非常類似的需求。
用戶希望通過(guò)高層語(yǔ)言描述模型的執(zhí)行邏輯,甚至是僅僅聲明模型的結(jié)構(gòu),而不去關(guān)心模型如何在硬件上完成訓(xùn)練或者推理。
深度學(xué)習(xí)框架需要解決模型在多種硬件上高效執(zhí)行的問(wèn)題,其中包括協(xié)同多個(gè)CPU、GPU、甚至大規(guī)模分布式集群進(jìn)行工作的問(wèn)題。也包括優(yōu)化內(nèi)存、顯存開銷、提高執(zhí)行速度的問(wèn)題。
更具體的。前文說(shuō)到需要能夠自動(dòng)的將用戶聲明的模型Program自動(dòng)的在多張顯卡上并行計(jì)算、需要將Program拆分到多個(gè)機(jī)器上進(jìn)行分布式計(jì)算、還需要修改執(zhí)行圖來(lái)進(jìn)行算子融合和顯存優(yōu)化。
Paddle在一開始零散的開展了上面描述的工作,在分布式、多卡并行、推理加速、甚至是模型的壓縮量化上各自進(jìn)行模型的改寫。這個(gè)過(guò)程非常容易產(chǎn)生重復(fù)性的工作,也很難統(tǒng)一設(shè)計(jì)模式,讓團(tuán)隊(duì)不同的研發(fā)快速理解這些代碼。
意思到這些問(wèn)題后,我寫了一個(gè)Single Static Assignment(SSA)的Graph,然后把Program通過(guò)第一個(gè)基礎(chǔ)Pass改寫成了SSA Graph。然后又寫了第二個(gè)Pass把SSA Graph改寫成了可以多卡并行的SSA Graph。
后面的事情就應(yīng)該可以以此類推了。比如推理加速可以在這個(gè)基礎(chǔ)上實(shí)現(xiàn)OpFusionPass, InferenceMemoryOptimizationPass, PruningPass等等,進(jìn)而達(dá)到執(zhí)行時(shí)推理加速的目的。分布式訓(xùn)練時(shí)則可以有DistributedTransPass。量化壓縮則可以有ConvertToInt8Pass等等。這一套東西基本解決了上層Program聲明到底層執(zhí)行器的Compiler問(wèn)題。
這個(gè)過(guò)程中的確碰到了不少的阻力。比如分布式早期通過(guò)Python完成了這個(gè)邏輯,需要遷移到C++層。壓縮量化的研發(fā)更喜歡寫Python,而IR&Pass是基于C++的。不同Pass間順序依賴和Debug等。
全套深度學(xué)習(xí)框架工具
TensorFlow Everywhere原本是TensorFlow團(tuán)隊(duì)時(shí)的一個(gè)口號(hào),意思是TensorFlow需要支持深度學(xué)習(xí)模型在任意的場(chǎng)景下運(yùn)行,進(jìn)而達(dá)到AI Everywhere的目標(biāo)。可以說(shuō)深度學(xué)習(xí)框架希望成為AI的“操作系統(tǒng)”,就像魚離不開水、App離不開iOS/Android一樣。
Paddle作為全面對(duì)標(biāo)TensorFlow的國(guó)產(chǎn)深度學(xué)習(xí)框架,自然也希望提供全套的解決方案。在早期的時(shí)候,Paddle和公司其他團(tuán)隊(duì)合作了PaddleMobile,提供了移動(dòng)端的推理能力。后來(lái)又開展了Paddle.js,支持在H5、Web等場(chǎng)景的推理能力。為了在toB,在Linux的基礎(chǔ)上又新增了Windows的支持。為了支持無(wú)人車等設(shè)備、又支持了在更多不同設(shè)備上運(yùn)行。
舉個(gè)PaddleMobile的例子。深度學(xué)習(xí)框架想再移動(dòng)設(shè)備上部署面臨這比較多的挑戰(zhàn)。手機(jī)的空間和算力都比服務(wù)器小很多,而模型最開始在服務(wù)器訓(xùn)練好后體積相對(duì)較大,需要從很多角度下手。1. 使用較小的模型結(jié)構(gòu)。2. 通過(guò)量化,壓縮等手段削減模型體積。
另外移動(dòng)段深度學(xué)習(xí)框架是通常基于ARM CPU,GPU則有Mali GPU, adreno GPU等等。為了最求比較極致性能,常常需要使用匯編語(yǔ)言。有個(gè)同學(xué)寫到后面幾乎懷疑人生,感覺(jué)自己大學(xué)學(xué)的東西不太對(duì)。為了不顯著增加APP的體積,框架編譯后的體積需要在KB~幾MB的級(jí)別,因此需要基于部署的模型結(jié)構(gòu)本身用到的算子進(jìn)行選擇性編譯。極端的時(shí)候甚至需要是通過(guò)C++ Code Gen的方法直接生成前向計(jì)算必須的代碼,而不是通過(guò)一個(gè)通用的解釋器。
回顧
隨著項(xiàng)目的復(fù)雜化,很多棘手的問(wèn)題逐漸從深度學(xué)習(xí)的領(lǐng)域技術(shù)問(wèn)題轉(zhuǎn)變成了軟件工程開發(fā)和團(tuán)隊(duì)管理分工的問(wèn)題。隨著團(tuán)隊(duì)的不斷變化,自己有時(shí)候是作為一個(gè)leader的角色在處理問(wèn)題,有的時(shí)候又是以一個(gè)independent contributor的角色在參與討論。很慶幸自己經(jīng)歷過(guò)這么一段,有些問(wèn)題在親身經(jīng)歷后才能想得明白,想得開。時(shí)代有時(shí)候會(huì)把你推向風(fēng)口浪尖,讓你帶船隊(duì)揚(yáng)帆起航,在更多的時(shí)候是在不斷的妥協(xié)與摸索中尋找前進(jìn)的方向。
無(wú)量
無(wú)量是騰訊PCG建設(shè)的一個(gè)深度學(xué)習(xí)框架,主要希望解決大規(guī)模推薦場(chǎng)景下的訓(xùn)練和推理問(wèn)題。深度學(xué)習(xí)在推薦場(chǎng)景的應(yīng)用和CV、NLP、語(yǔ)音有些不一樣。
業(yè)務(wù)會(huì)持續(xù)的產(chǎn)生用戶的行為數(shù)據(jù)。當(dāng)用戶規(guī)模達(dá)到數(shù)千萬(wàn)或者上億時(shí)就會(huì)產(chǎn)生海量的訓(xùn)練數(shù)據(jù),比如用戶的畫像,用戶的點(diǎn)擊,點(diǎn)贊,轉(zhuǎn)發(fā)行為,還有Context等等。
這些數(shù)據(jù)是高度稀疏的,通常會(huì)編碼成ID類的特征進(jìn)而通過(guò)Embedding的方式進(jìn)入模型訓(xùn)練。隨著業(yè)務(wù)規(guī)模的提升和特征工程日漸復(fù)雜,比如累計(jì)用戶數(shù),商品,內(nèi)容增加,以及特征交叉的使用,Embedding參數(shù)的體積可以達(dá)到GB,甚至TB級(jí)。
推薦場(chǎng)景是實(shí)時(shí)動(dòng)態(tài)變化的,新用戶,內(nèi)容,熱點(diǎn)不斷產(chǎn)生。用戶的興趣,意圖逐漸變化,因此模型需要持續(xù)不斷的適應(yīng)這些變化,時(shí)刻保持最好的狀態(tài)。
調(diào)整
19年中這個(gè)項(xiàng)目時(shí)大概有2~3人。團(tuán)隊(duì)希望開發(fā)一個(gè)新的版本,基于TensorFlow進(jìn)行擴(kuò)展加強(qiáng),使得無(wú)量可以復(fù)用TensorFlow已有的能力,并且能夠支持推薦場(chǎng)景下的特殊需求。無(wú)量一開始采用的是基于參數(shù)服務(wù)器的架構(gòu)。TensorFlow被復(fù)用來(lái)提供Python API以及完成基礎(chǔ)算子的執(zhí)行。而參數(shù)服務(wù)器,分布式通信等方面則是自己開發(fā),沒(méi)有復(fù)用TensorFlow。
這個(gè)選擇在團(tuán)隊(duì)當(dāng)時(shí)的情況下是比較合理的。如果選擇另一種方向,基于TensorFlow底層進(jìn)行改造,研發(fā)難度會(huì)比較大,而且很可能與社區(qū)版TensorFlow走向不同的方向,進(jìn)而導(dǎo)致TensorFlow版本難以升級(jí)。而把TensorFlow作為一個(gè)本地執(zhí)行的lib則可以在外圍開發(fā),不需要了解TensorFlow內(nèi)部的復(fù)雜邏輯,也可以復(fù)用一些其他開源組件,比如pslib。
早期在軟件開發(fā)的流程上相對(duì)比較欠缺。為了保障工程的推進(jìn),我先幫忙做了些基礎(chǔ)工作,比如加上了第一個(gè)自動(dòng)化測(cè)試和持續(xù)集成,對(duì)一些過(guò)度封裝和奇怪的代碼做了重構(gòu)和簡(jiǎn)化。
另外,在接口層也做了一些調(diào)整。原來(lái)框架開始執(zhí)行后就進(jìn)入C++執(zhí)行器,無(wú)法從python層提供或者返回任何執(zhí)行結(jié)果,也無(wú)法在python層執(zhí)行邏輯進(jìn)行插件化的擴(kuò)展。為了滿足預(yù)期用戶將來(lái)需要進(jìn)行調(diào)試的需求,我模擬tf.Session和tf.Estimator對(duì)執(zhí)行層的接口做了重構(gòu)。這樣用戶可以通過(guò)feed/fetch的方式單步調(diào)試執(zhí)行的過(guò)程。也可以通過(guò)Hook的方式在執(zhí)行前后擴(kuò)展任意的邏輯,提高框架的適用場(chǎng)景。
另外一個(gè)問(wèn)題是python層基本完全是全局變量,很難進(jìn)行多模型的封裝。像TensorFlow有Graph實(shí)例或者Paddle有Program實(shí)例。因?yàn)閜ython層需要重構(gòu)的量比較大,我暫時(shí)先加入了Context的封裝,勉強(qiáng)將各種狀態(tài)和配置封裝在了Context下。考慮到短期可能不會(huì)有更復(fù)雜的需求,暫時(shí)沒(méi)有把這件事做完。
reader那塊也做了一些重構(gòu)。最開始那塊的線程模型異常復(fù)雜,一部分是因?yàn)榉植际轿募到y(tǒng)等基礎(chǔ)設(shè)施無(wú)法提供比較好的SDK,導(dǎo)致許多邏輯不得不在深度學(xué)習(xí)框架里面,比如文件的本地緩存。考慮到特征加工的邏輯比較復(fù)雜,以及一些老的TensorFlow用戶可能習(xí)慣于tf.Example和tf.feature_column等基礎(chǔ)算子庫(kù),我在reader層引入了基于TensorFlow的tf.dataset。不過(guò)后來(lái)發(fā)現(xiàn)用戶似乎更關(guān)心性能問(wèn)題,喜歡自定義C++ lib的方式來(lái)解決特征處理的問(wèn)題。
API設(shè)計(jì)是個(gè)老大難的問(wèn)題。TensorFlow,Paddle,無(wú)量都沒(méi)能幸免。在一個(gè)多人協(xié)同的團(tuán)隊(duì)里,每個(gè)研發(fā)更多還是關(guān)注每個(gè)獨(dú)立功能是否完成開發(fā),而功能的接口往往需要考慮到整體的API設(shè)計(jì)風(fēng)格,易用性,兼容性等許多因素,常常在高速迭代的過(guò)程中被忽略掉。不幸的是API常常不能像內(nèi)部實(shí)現(xiàn)一樣后期優(yōu)化。當(dāng)API被放給用戶使用后,后續(xù)的修改往往會(huì)破壞用戶代碼的正確性。很多時(shí)候只能自己評(píng)審一下。
升級(jí)
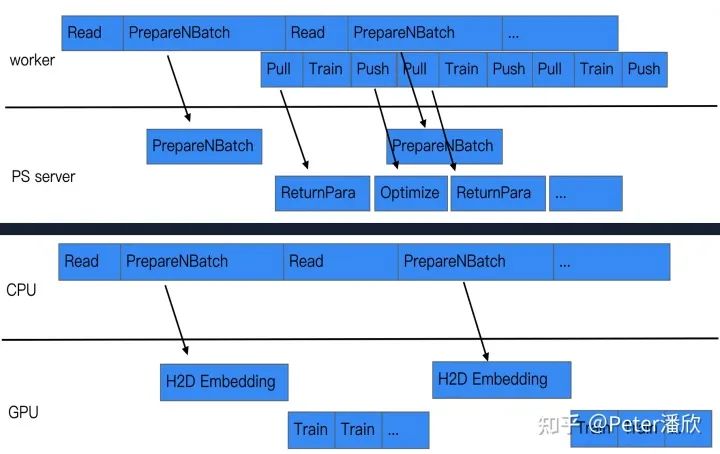
無(wú)量經(jīng)過(guò)一年基礎(chǔ)能力的打磨,逐漸的成為來(lái)整個(gè)事業(yè)群統(tǒng)一的大規(guī)模推薦模型訓(xùn)練和推理框架,支撐數(shù)十個(gè)業(yè)務(wù)場(chǎng)景,每天都能生產(chǎn)數(shù)千個(gè)增量和全量的模型。簡(jiǎn)單的完成功能已經(jīng)不能滿足業(yè)務(wù)和團(tuán)隊(duì)發(fā)展的需求,需要在技術(shù)上更加前沿。
數(shù)據(jù)處理
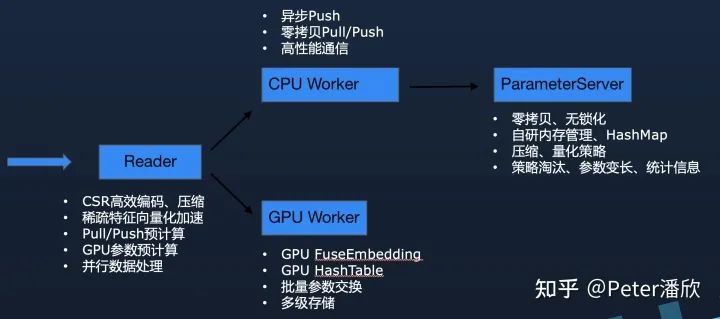
數(shù)據(jù)格式上要從原來(lái)的明文轉(zhuǎn)到更高效的二進(jìn)制。另外基于CSR編碼的稀疏數(shù)據(jù)可以進(jìn)一步的減少數(shù)據(jù)處理時(shí)的拷貝等額外開銷。
流水線
盡量挖掘訓(xùn)練中可以并行的地方,通過(guò)流水線的方式提高并發(fā)度,進(jìn)而提高訓(xùn)練的速度。比如在數(shù)據(jù)讀取的過(guò)程中,就可以提前按照參數(shù)服務(wù)器的規(guī)模對(duì)數(shù)據(jù)進(jìn)行預(yù)切分,并告知參數(shù)服務(wù)器需要提前準(zhǔn)備哪些參數(shù)。這樣當(dāng)pull/push的時(shí)候能夠更快的完成計(jì)算,進(jìn)而提高每個(gè)minibatch的速度。
同樣,當(dāng)使用GPU訓(xùn)練時(shí),也可以在數(shù)據(jù)IO的并行過(guò)程中,預(yù)計(jì)算未來(lái)需要用的的Embedding參數(shù)。這樣GPU訓(xùn)練下一輪的數(shù)據(jù)時(shí),需要用到的Embedding已經(jīng)提前被計(jì)算好,可以直接開始訓(xùn)練,減少來(lái)等待的時(shí)間。
定制化參數(shù)服務(wù)器
由于無(wú)量解決的一個(gè)關(guān)鍵問(wèn)題是推薦模型的海量參數(shù)問(wèn)題,因此參數(shù)服務(wù)器必須是高度優(yōu)化過(guò)的。并且應(yīng)該合理的將推薦模型的領(lǐng)域知識(shí)引入到設(shè)計(jì)中,通過(guò)特殊的策略進(jìn)一步產(chǎn)生差異化的優(yōu)勢(shì)。
定制化的線程模型,內(nèi)存管理和HashMap。由于參數(shù)是被切分歸屬到不同線程上,所以可以通過(guò)無(wú)鎖化的把每次pull/push的參數(shù)處理好。另外由于海量參數(shù)消耗較大硬件成本,內(nèi)存空間都需要通過(guò)定制化的內(nèi)存池來(lái)管理。否則很可能有大量的空間碎片在默認(rèn)內(nèi)存庫(kù)中無(wú)法及時(shí)歸還給操作系統(tǒng)。另外也有無(wú)法精細(xì)化控制內(nèi)存清理機(jī)制,導(dǎo)致內(nèi)存OOM或者浪費(fèi)。定制化的內(nèi)存管理可以解決這些問(wèn)題,甚至通過(guò)特殊的內(nèi)存淘汰策略,在不損害模型效果的基礎(chǔ)上進(jìn)一步降低內(nèi)存的開銷。高性能HashMap則是需要解決Embedding快速的增刪改查的問(wèn)題。
Embedding向量的管理也是有非常多可以改進(jìn)的地方。1. 動(dòng)態(tài)的改變Embeding向量的長(zhǎng)度來(lái)支持模型的壓縮,提高模型效果。2. 擴(kuò)展Embedding的元數(shù)據(jù)來(lái)記錄熱度,點(diǎn)擊展現(xiàn)等統(tǒng)計(jì)值,有助于提高訓(xùn)練推理時(shí)高級(jí)分布式架構(gòu)的Cache命中率,已經(jīng)模型的訓(xùn)練效果。3. 模型的恢復(fù)和導(dǎo)出機(jī)制在大規(guī)模Embedding場(chǎng)景對(duì)于Serving時(shí)能夠?qū)崟r(shí)加載模型更新重要。另外還需要考慮到任務(wù)失敗重啟后資源伸縮等問(wèn)題。
GPU訓(xùn)練
傳統(tǒng)PS架構(gòu)的訓(xùn)練模式下,由于單臺(tái)機(jī)器的計(jì)算能力有限,需要幾十甚至上百個(gè)實(shí)例進(jìn)行分布式訓(xùn)練。但是這樣會(huì)導(dǎo)致大量的計(jì)算被用在來(lái)無(wú)效的開銷上。比如稀疏特征在網(wǎng)絡(luò)通信兩邊的處理。這種額外開銷甚至經(jīng)常超過(guò)有效計(jì)算。
GPU和相應(yīng)的高速網(wǎng)絡(luò)鏈接可以解決這一問(wèn)題。單臺(tái)8卡機(jī)器通過(guò)NVLink連接起來(lái),速度甚至可以超過(guò)幾十臺(tái)物理機(jī),有更高的性價(jià)比。但是由于幾百GB,甚至TB級(jí)的參數(shù)問(wèn)題,還有Embedding的GPU計(jì)算問(wèn)題,導(dǎo)致GPU一直都沒(méi)有被廣泛的用起來(lái)。
然而實(shí)驗(yàn)發(fā)現(xiàn)其實(shí)稀疏特征存在顯著的Power-law分布,少部分Hot特征使用遠(yuǎn)多于其他大量不Hot的特征。因此,通過(guò)在數(shù)據(jù)處理時(shí)統(tǒng)計(jì)特征,然后批量將將來(lái)新需要的Embedding換入GPU,就可以讓GPU長(zhǎng)時(shí)間的進(jìn)行連續(xù)訓(xùn)練,而不需要頻繁的和CPU內(nèi)存交換參數(shù)。
GPU預(yù)測(cè)
隨著推薦模型復(fù)雜度提高,引入傳統(tǒng)CV,NLP的一些結(jié)構(gòu)需要消耗更多的計(jì)算。CPU往往很難在有效的時(shí)間延遲下(幾十毫秒)完成大量候(幾百上千)選集在復(fù)雜推薦模型的推理。而GPU則成為了一個(gè)潛在的解決方案。
同樣,GPU推理也需要解決顯存遠(yuǎn)小于Embedding參數(shù)的問(wèn)題。通過(guò)在訓(xùn)練時(shí)預(yù)先計(jì)算Hot Embedding,然后加載如推理GPU,可以一定程度的緩解這個(gè)問(wèn)題。在推理時(shí)僅有少部分的Embedding沒(méi)有在GPU顯存中緩存,需要通過(guò)CPU內(nèi)存拷貝進(jìn)入GPU。
而通過(guò)模型的量化和壓縮能進(jìn)一步減少Embedding參數(shù)的規(guī)模。實(shí)驗(yàn)表明當(dāng)大部分Embedding參數(shù)的值控制為0時(shí),模型依然能夠表現(xiàn)出原來(lái)的效果,甚至略優(yōu)。
總結(jié)
深度學(xué)習(xí)算法的發(fā)展和深度學(xué)習(xí)框架的發(fā)展是相輔相成,互相促進(jìn)的。從2002年時(shí)Torch論文發(fā)表后,框架的技術(shù)發(fā)展相對(duì)緩慢,性能無(wú)法顯著提升導(dǎo)致無(wú)法探索更加復(fù)雜的算法模型,或者利用更加大規(guī)模的數(shù)據(jù)集。
在2010年后逐漸出現(xiàn)了Caffe, Theano等框架,通過(guò)將更高性能的GPU引入,可以訓(xùn)練更加復(fù)雜的CNN和RNN模型,深度學(xué)習(xí)算法的發(fā)展出現(xiàn)來(lái)顯著的加速。
到了2014~2017年幾年間,TensorFlow的出現(xiàn)讓用戶可以通過(guò)簡(jiǎn)單的Python語(yǔ)言將細(xì)粒度的算子組裝各種模型結(jié)構(gòu)。并且模型可以簡(jiǎn)單的被分布式訓(xùn)練,然后自動(dòng)化部署在服務(wù)器,手機(jī),攝像頭等各種設(shè)備上。而Pytorch的動(dòng)態(tài)圖用法滿足了研究人員對(duì)易用性和靈活性更高的要求,進(jìn)一步推進(jìn)算法研究。
國(guó)內(nèi)的深度學(xué)習(xí)框架技術(shù)在這股浪潮中也緊跟這世界的步伐。Paddle在14年左右產(chǎn)生,在國(guó)內(nèi)積累了一定的用戶,在當(dāng)時(shí)基本能比肩其他的框架。雖然在TensorFlow和Pytorch等更先進(jìn)的框架出現(xiàn)后,國(guó)內(nèi)錯(cuò)過(guò)了寶貴的幾年技術(shù)升級(jí)的窗口以及社區(qū)生態(tài)培育時(shí)機(jī),但是我們看到從18年到20年間,新版的PaddlePaddle,OneFlow, MindSpore等深度學(xué)習(xí)框架陸續(xù)開源,技術(shù)上逐漸趕了上來(lái)。
推薦場(chǎng)景在電商,視頻,資訊等眾多頭部互聯(lián)網(wǎng)公司的火爆導(dǎo)致推薦系統(tǒng)對(duì)AI硬件的消耗在互聯(lián)網(wǎng)公司超過(guò)了傳統(tǒng)NLP,CV,語(yǔ)音等應(yīng)用的總和。許多公司開始針對(duì)推薦場(chǎng)景(以及廣告,搜索)的特殊需求對(duì)深度學(xué)習(xí)框架進(jìn)行定制優(yōu)化。百度的abacus是比較早期的框架,和其他早期框架一樣,在易用性和靈活性上較弱。無(wú)量,XDL等框架則進(jìn)行了改進(jìn),兼顧了社區(qū)兼容性,算法易用性和系統(tǒng)的性能等緯度。
深度學(xué)習(xí)的框架的觸角其實(shí)遠(yuǎn)不止我們常見(jiàn)到的。隨著AI技術(shù)的推廣,Web、H5、嵌入式設(shè)備、手機(jī)等場(chǎng)景下都有許多優(yōu)秀的深度學(xué)習(xí)框架產(chǎn)生,如PaddleMobile, TFLite,tensorflow.js等等。
深度學(xué)習(xí)框架的技術(shù)也逐漸從更多緯度開始拓展。ONNX被提出來(lái)作為統(tǒng)一的模型格式,雖然離目標(biāo)有很長(zhǎng)的距離和問(wèn)題需要解決。但是從它的流行我們能看到社區(qū)對(duì)于框架間互通的渴望。隨著摩爾定律難以維持,框架開始更多的從新的硬件和異構(gòu)計(jì)算領(lǐng)域?qū)で笸黄啤榱酥С趾A康乃阕釉贑PU、FPGA、GPU、TPU、NPU、Cerebras等眾多AI芯片上運(yùn)行,TVM、XLA等借鑒編譯技術(shù)幾十年來(lái)的積累,在更加艱巨的道路上進(jìn)行來(lái)持續(xù)的探索,經(jīng)常能傳來(lái)新進(jìn)展的好消息。深度學(xué)習(xí)框架也不再僅應(yīng)用于深度學(xué)習(xí),還在科學(xué)計(jì)算,物理化學(xué)等領(lǐng)域發(fā)光發(fā)熱。
責(zé)任編輯:lq
-
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5507瀏覽量
121294 -
tensorflow
+關(guān)注
關(guān)注
13文章
329瀏覽量
60542 -
ai技術(shù)
+關(guān)注
關(guān)注
1文章
1281瀏覽量
24351
原文標(biāo)題:從我開發(fā)過(guò)的Tensorflow、飛槳、無(wú)量框架看深度學(xué)習(xí)這幾年
文章出處:【微信號(hào):zenRRan,微信公眾號(hào):深度學(xué)習(xí)自然語(yǔ)言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
HarmonyOS NEXT應(yīng)用元服務(wù)開發(fā)Intents Kit(意圖框架服務(wù))習(xí)慣推薦方案概述
Pytorch深度學(xué)習(xí)訓(xùn)練的方法

GPU深度學(xué)習(xí)應(yīng)用案例
FPGA加速深度學(xué)習(xí)模型的案例
FPGA做深度學(xué)習(xí)能走多遠(yuǎn)?
今年蘋果營(yíng)收預(yù)計(jì)突破4000億美元大關(guān),創(chuàng)歷史新高
NVIDIA推出全新深度學(xué)習(xí)框架fVDB
PyTorch深度學(xué)習(xí)開發(fā)環(huán)境搭建指南
深度學(xué)習(xí)與nlp的區(qū)別在哪
深度學(xué)習(xí)常用的Python庫(kù)
TensorFlow與PyTorch深度學(xué)習(xí)框架的比較與選擇
FPGA在深度學(xué)習(xí)應(yīng)用中或?qū)⑷〈鶪PU
為什么深度學(xué)習(xí)的效果更好?

免費(fèi)學(xué)習(xí)鴻蒙(HarmonyOS)開發(fā),一些地址分享
詳解深度學(xué)習(xí)、神經(jīng)網(wǎng)絡(luò)與卷積神經(jīng)網(wǎng)絡(luò)的應(yīng)用






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論