") 知乎搜索中文本相關(guān)性和知識(shí)蒸餾的工作實(shí)踐
知乎搜索中文本相關(guān)性和知識(shí)蒸餾的工作實(shí)踐
導(dǎo)讀:大家好,我是申站,知乎搜索團(tuán)隊(duì)的算法工程師。今天給大家分享下知乎搜索中文本相關(guān)性和知識(shí)蒸餾的工作實(shí)踐,主要內(nèi)容包括:
知乎搜索文本相關(guān)性的演進(jìn)
BERT在知乎搜索的應(yīng)用和問(wèn)題
知識(shí)蒸餾及常見(jiàn)方案
知乎搜索在BERT蒸餾上的實(shí)踐
01
知乎搜索文本相關(guān)性的演進(jìn)
1. 文本相關(guān)性的演進(jìn)
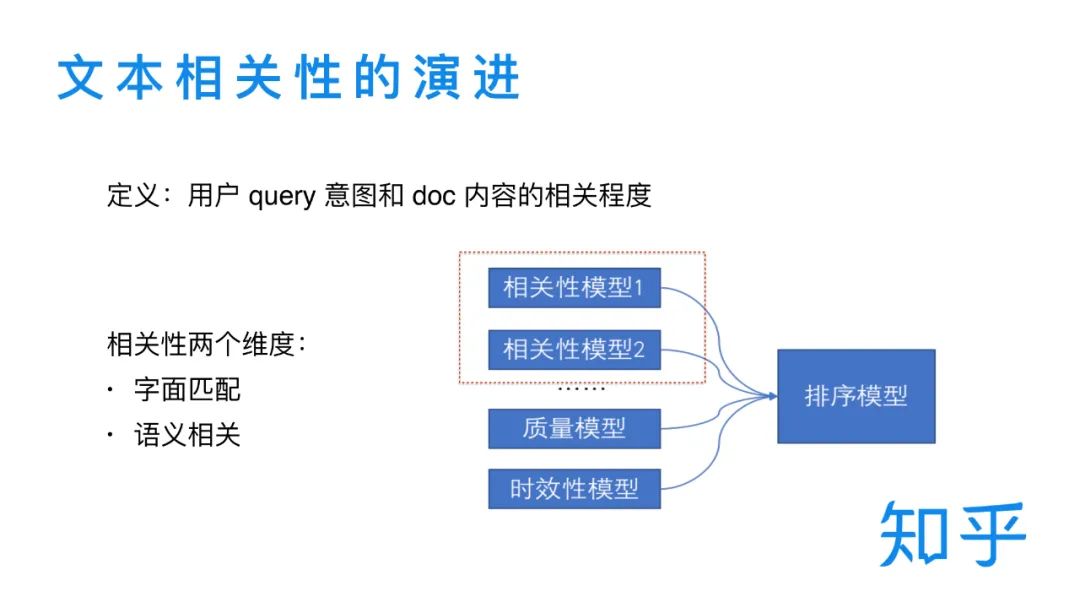
我們首先來(lái)介紹下知乎搜索中的文本相關(guān)性。在搜索場(chǎng)景中,文本相關(guān)性可以定義為?戶(hù)搜索query的意圖與召回 doc 內(nèi)容的相關(guān)程度。我們需要通過(guò)不同模型來(lái)對(duì)這種相關(guān)程度進(jìn)行建模。整體而言,文本的相關(guān)性一般可以分為兩個(gè)維度,字面匹配和語(yǔ)義相關(guān)。知乎搜索中文本相關(guān)性模型的演進(jìn)也是從這兩個(gè)方面出發(fā)并有所側(cè)重和發(fā)展。在知乎搜索的整個(gè)架構(gòu)中,文本相關(guān)性模型主要定位于為二輪精排模型提供更高維/抽象的特征,同時(shí)也兼顧了一部分召回相關(guān)的工作。
2. Before NN

知乎搜索中的文本相關(guān)性整體演進(jìn)可以分為三個(gè)階段。在引入深度語(yǔ)義匹配模型前,知乎搜索的文本相關(guān)性主要是基于TF-IDF/BM25的詞袋模型,下圖右邊是BM25的公式。詞袋模型通常來(lái)說(shuō)是一個(gè)系統(tǒng)的工程,除了需要人工設(shè)計(jì)公式外,在統(tǒng)計(jì)詞的權(quán)重、詞頻的基礎(chǔ)上,還需要覆蓋率、擴(kuò)展同義詞,緊密度等各種模塊的協(xié)同配合,才能達(dá)到一個(gè)較好的效果。知乎搜索相關(guān)性的一個(gè)比較早期的版本就是在這個(gè)基礎(chǔ)上迭代的。右下部分為在基于詞袋模型的基礎(chǔ)上,可以參考使用的一些具體特征。
3. Before BERT
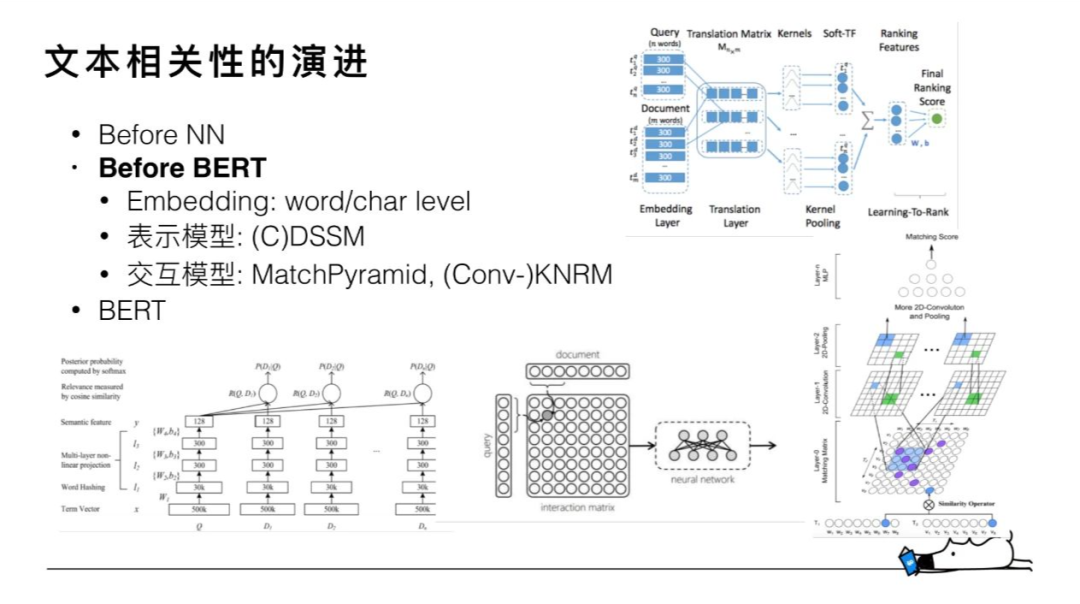
基于 BM25 的詞袋模型不管如何設(shè)計(jì),主要還是只解決文本相關(guān)性中的字面匹配這部分問(wèn)題。第二階段引入的深度語(yǔ)義匹配模型則聚焦于解決語(yǔ)義相關(guān)的問(wèn)題,主要分為兩部分:雙塔表示模型和底層交互模型。微軟的DSSM(左下)是雙塔模型的典型代表。雙塔模型通過(guò)兩個(gè)不同的 encoder來(lái)分別獲取query和doc的低維語(yǔ)義句向量表示,然后針對(duì)兩個(gè)語(yǔ)義向量來(lái)設(shè)計(jì)相關(guān)性函數(shù)(比如cosine)。DSSM擺脫了詞袋模型復(fù)雜的特征工程和子模塊設(shè)計(jì),但也存在固有的缺陷:query和doc的語(yǔ)義表示是通過(guò)兩個(gè)完全獨(dú)立的 encoder 來(lái)獲取的,兩個(gè)固定的向量無(wú)法動(dòng)態(tài)的擬合doc在不同 query的不同表示。這個(gè)反應(yīng)到最后的精度上,肯定會(huì)有部分的損失。
底層交互模型一定程度上解決了這個(gè)問(wèn)題。這個(gè)交互主要體現(xiàn)在 query 和 doc term/char 交互矩陣(中)的設(shè)計(jì)上,交互矩陣使模型能夠在靠近輸入層就能獲取 query 和 doc 的相關(guān)信息。在這個(gè)基礎(chǔ)上,后續(xù)通過(guò)不同的神經(jīng)網(wǎng)絡(luò)設(shè)計(jì)來(lái)實(shí)現(xiàn)特征提取得到 query-doc pair 的整體表示,最后通過(guò)全連接層來(lái)計(jì)算最終相關(guān)性得分。Match-Pyramid(右下)、KNRM(右上)是交互模型中比較有代表性的設(shè)計(jì),我們?cè)谶@兩個(gè)模型的基礎(chǔ)上做了一些探索和改進(jìn),相比于傳統(tǒng)的 BM25 詞袋模型取得了很大的提升。
4.BERT
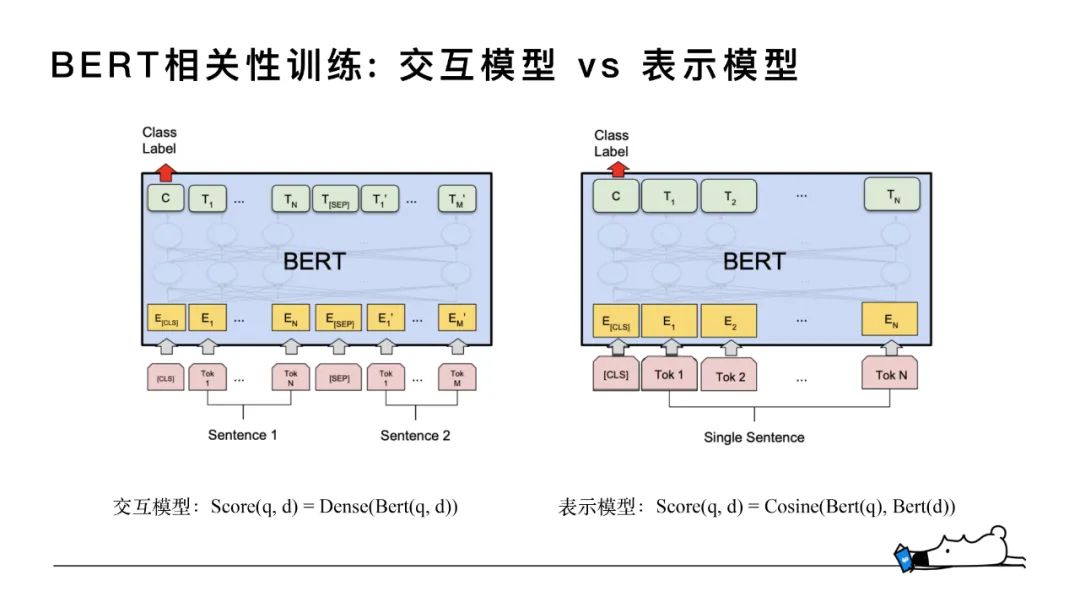
BERT模型得益于 transformer 結(jié)構(gòu)擁有非常強(qiáng)大的文本表示能力。第三階段我們引入了 BERT希望能夠進(jìn)一筆提高知乎搜索中文本相關(guān)性的表型。BERT 的應(yīng)用也分為表示模型和交互模型。
對(duì)于交互模型來(lái)說(shuō),如下左圖,query和doc分別為sentence1和sentence2直接輸入到BERT模型中,通過(guò)BERT做一個(gè)整體的encoder去得到sentence pair的向量表示,再通過(guò)全連接層得到相似性打分,因?yàn)槊總€(gè)doc都是依賴(lài)query的,每個(gè)query-doc pair都需要線(xiàn)上實(shí)時(shí)計(jì)算,對(duì)GPU機(jī)器資源的消耗非常大,對(duì)整體的排序服務(wù)性能有比較大的影響。
基于上述原因,我們也做了類(lèi)似于DSSM形式的表示模型,將BERT作為encoder,訓(xùn)練數(shù)據(jù)的中的每個(gè)query和doc在輸入層沒(méi)有區(qū)分,都是做為不同的句子輸入,得到每個(gè)句向量表示,之后再對(duì)兩個(gè)表示向量做點(diǎn)乘,得到得到相關(guān)度打分。通過(guò)大量的實(shí)驗(yàn),我們最終采用了 BERT 輸出 token 序列向量的 average 作為句向量的表示。從交互模型到表示模型的妥協(xié)本質(zhì)是空間換時(shí)間,因?yàn)閐oc是可以全量離線(xiàn)計(jì)算存儲(chǔ)的,在線(xiàn)只需要實(shí)時(shí)計(jì)算比較短的 query ,然后doc直接通過(guò)查表,節(jié)省了大量的線(xiàn)上計(jì)算。相比于交互模型,精度有一部分損失。
02
BERT在知乎搜索的應(yīng)用和問(wèn)題
1.搜索業(yè)務(wù)架構(gòu)中的BERT
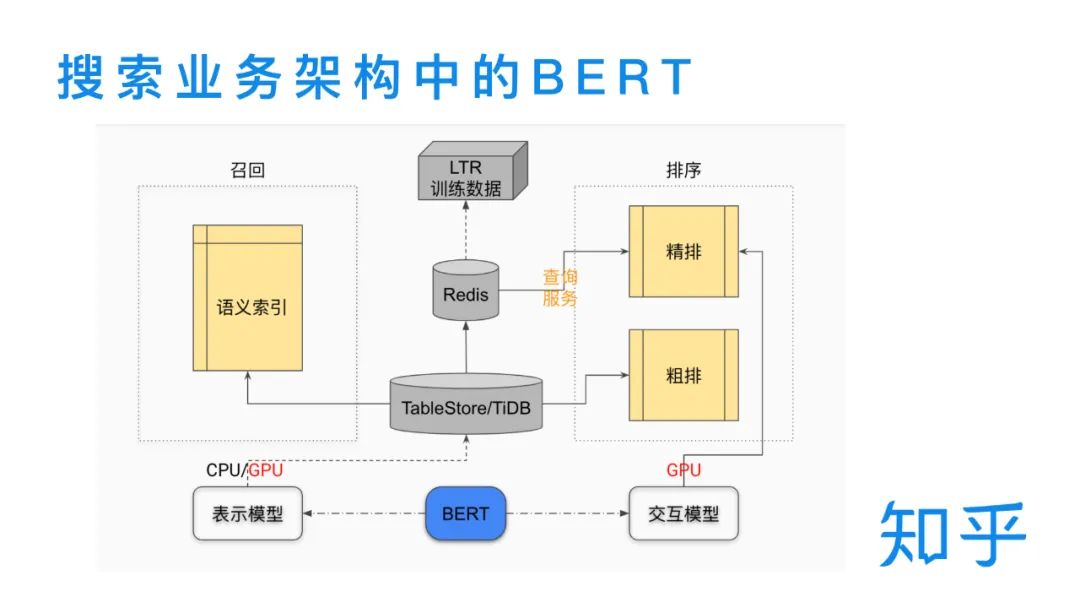
在下圖中我們可以看到,BERT在知乎搜索業(yè)務(wù)的召回和排序階段都扮演了比較重要的角色。交互模型的主要服務(wù)于二輪精排模型,依賴(lài)于線(xiàn)上實(shí)時(shí)的計(jì)算query和doc,為精排模塊提供相關(guān)性特征。表示模型又分為在線(xiàn)和離線(xiàn)兩塊,在線(xiàn)表示模型實(shí)時(shí)的為用戶(hù)輸入的query提供句向量表示,離線(xiàn)表示模型為庫(kù)中的doc進(jìn)行批量句向量計(jì)算。一方面,doc向量通過(guò)TableStore/TiDB 和Redis的兩級(jí)存儲(chǔ)設(shè)計(jì),為線(xiàn)上排序做查詢(xún)服務(wù);另一方面,使用 faiss 對(duì)批量doc 向量構(gòu)建語(yǔ)義索引,在傳統(tǒng)的 term 召回基礎(chǔ)上補(bǔ)充向量語(yǔ)義召回。
2. BERT表示模型語(yǔ)義召回
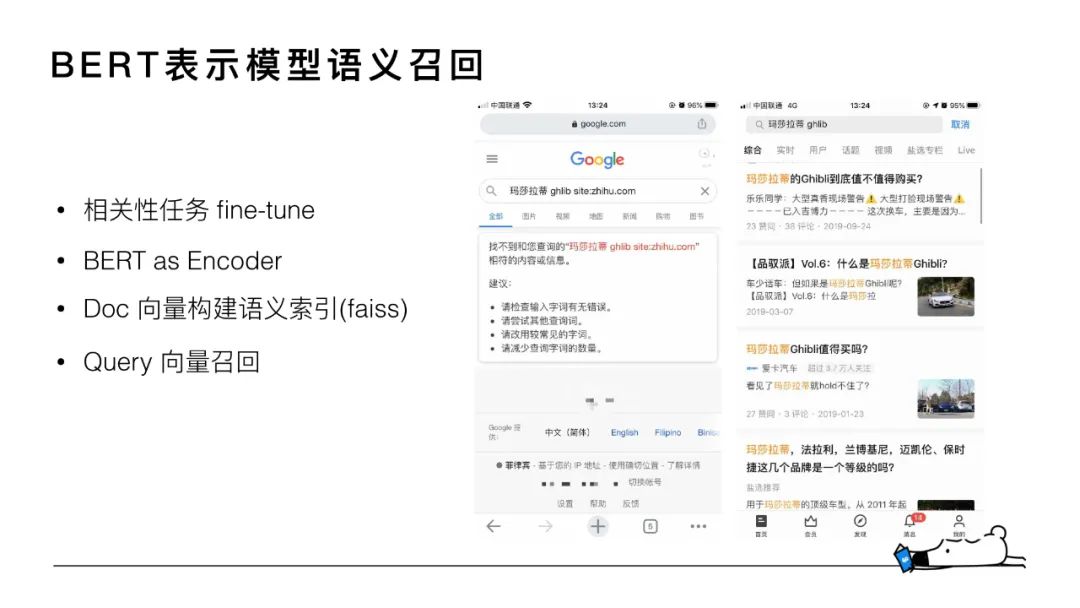
下面詳細(xì)介紹下我們的語(yǔ)義召回模型。首先看個(gè)例子,對(duì)于「瑪莎拉蒂 ghlib」這個(gè)case,用戶(hù)真正想搜的是「瑪莎拉蒂 Ghibli」這款車(chē),但用戶(hù)一般很難記住完整的名稱(chēng),可能會(huì)輸錯(cuò)。在輸錯(cuò)的情況下,基于傳統(tǒng)的term匹配方式(Google搜索的例子)只能召回“瑪莎拉蒂”相關(guān)的 doc,而無(wú)法進(jìn)行這輛車(chē)型的召回,這種場(chǎng)景下就需要進(jìn)行語(yǔ)義召回。更通用的來(lái)說(shuō),語(yǔ)義召回可以理解為增加了字面不匹配但是語(yǔ)義相關(guān)的 doc 的召回。
語(yǔ)義召回模型整體是BERT 相關(guān)性任務(wù)中雙塔表示模型的一個(gè)應(yīng)用。BERT做為encoder來(lái)對(duì)query和doc進(jìn)行向量的表示,基于faiss對(duì)全量 doc 向量構(gòu)建語(yǔ)義索引,線(xiàn)上實(shí)時(shí)的用query向量進(jìn)行召回。這個(gè)策略上線(xiàn)后,線(xiàn)上top20 doc中語(yǔ)義召回doc數(shù)量占總召回 doc 數(shù)量的比例能到達(dá) 5%+。
3. BERT帶來(lái)的問(wèn)題

BEER 模型上線(xiàn)后,為不同的模塊都取得了不錯(cuò)收益的同時(shí),也給整個(gè)系統(tǒng)帶來(lái)了不少問(wèn)題。這些問(wèn)題整體可以歸結(jié)為線(xiàn)上實(shí)時(shí)計(jì)算、離線(xiàn)存儲(chǔ)、模型迭代三個(gè)方面。具體的見(jiàn)上圖。
4. 蒸餾前的嘗試
針對(duì)上述性能或存儲(chǔ)的問(wèn)題,在對(duì)BERT 蒸餾之前,我們也進(jìn)行了很多不同的嘗試。

BERT 交互模型的部署放棄了使用原生TF serving,而是在cuda 的基礎(chǔ)上用c++ 重寫(xiě)了模型的加載和serving,加上混合精度的使用。在我們的業(yè)務(wù)規(guī)模上,線(xiàn)上實(shí)時(shí)性能提高到原來(lái)的約 1.5 倍,使BERT交互模型滿(mǎn)足了的最低的可上線(xiàn)要求。在這個(gè)基礎(chǔ)上,對(duì)線(xiàn)上的 BERT 表示模型增加 cache,減少約 60% 的請(qǐng)求,有效減少了GPU 機(jī)器資源的消耗。
另一個(gè)思路是嘗試給BERT在橫向和縱向維度上瘦身。橫向上,一方面可以減小serving 時(shí) max_seq_length長(zhǎng)度,減少計(jì)算量;另一方面可以對(duì)表示向量進(jìn)行維度壓縮來(lái)降低存儲(chǔ)開(kāi)銷(xiāo)。這兩種嘗試在離線(xiàn)和在線(xiàn)指標(biāo)上都有不同程度的損失,因此被放棄。縱向上,主要是減少模型的深度,即減少 transformer層數(shù)。這對(duì)于顯存和計(jì)算量都能得到顯著的優(yōu)化。前期嘗試過(guò)直接訓(xùn)練小模型,以及使用BERT-base若干層在下游的相關(guān)性任務(wù)上進(jìn)行fine-tune。這兩種方案,在離線(xiàn)指標(biāo)上的表現(xiàn)就沒(méi)法達(dá)到要求,因此也沒(méi)有上線(xiàn)。
針對(duì) doc數(shù)量過(guò)大,存儲(chǔ)開(kāi)銷(xiāo)過(guò)大和語(yǔ)義索引構(gòu)建慢的問(wèn)題。在這方面做了一個(gè)妥協(xié)的方案:通過(guò)wilson score 等規(guī)則過(guò)濾掉大部分低質(zhì)量的 doc,只對(duì)約 1/3 的doc 存儲(chǔ)表示向量和構(gòu)建語(yǔ)義索引。該方案會(huì)導(dǎo)致部分文檔的相關(guān)性特征存在缺失。對(duì)于表示模型存在的低交互問(wèn)題,嘗試Poly-encoder(Facebook方案)將固定的 768維表示向量轉(zhuǎn)為多個(gè)head的形式,用多個(gè)head做attention的計(jì)算,保證性能在部分下降的前提得到部分精度的提升。
03
智知識(shí)蒸餾及常見(jiàn)方案
1.知識(shí)蒸餾
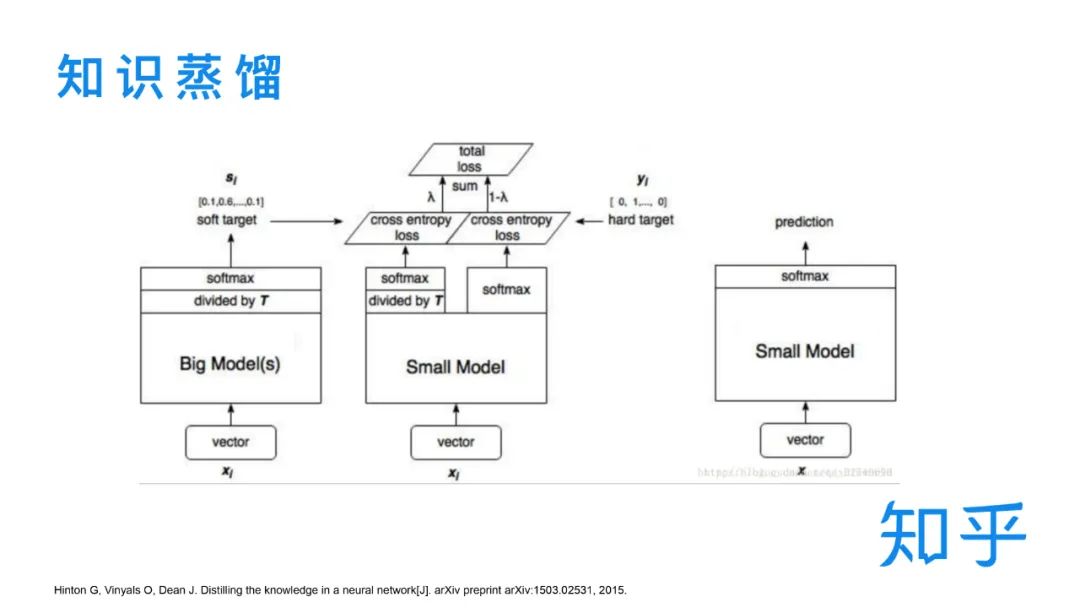
下面簡(jiǎn)單介紹下知識(shí)蒸餾。從下圖中看,我們可以把知識(shí)蒸餾的整體形式簡(jiǎn)化為:大模型不考慮性能問(wèn)題盡量學(xué)習(xí)更多的知識(shí)(數(shù)據(jù)),小模型通過(guò)適量的數(shù)據(jù)去高效地學(xué)習(xí)大模型的輸出,達(dá)到一個(gè)知識(shí)遷移的效果。實(shí)際 serving 使用的是小模型。

知識(shí)蒸餾為什么能有效?關(guān)鍵點(diǎn)在于 soft target 和 temperature。soft target對(duì)應(yīng)的是teacher模型的輸出,類(lèi)似于概率分布,知識(shí)蒸餾從hard target轉(zhuǎn)為soft target的學(xué)習(xí)有利于模型更好的去擬合標(biāo)簽,引入temperature則是為了進(jìn)一步平滑標(biāo)簽,讓模型去學(xué)習(xí)到類(lèi)別和類(lèi)別中的知識(shí)。這里需要注意的是,temperature 的選取不宜過(guò)大,太大的 temperature 會(huì)導(dǎo)致不同類(lèi)別之間的差異被完全平滑掉。
2.BERT蒸餾方案

對(duì)與BERT的蒸餾我們做了大量的調(diào)研,并對(duì)目前主流的蒸餾方案做了歸納分類(lèi)。基于任務(wù)維度來(lái)說(shuō),主要對(duì)應(yīng)于現(xiàn)在的pretrain + fine-tune 的兩段式訓(xùn)練。在預(yù)訓(xùn)練階段和下游任務(wù)階段都有不少的方案涉及。技巧層面來(lái)分的話(huà),主要包括不同的遷移知識(shí)和模型結(jié)構(gòu)的設(shè)計(jì)兩方面。后面我會(huì)選兩個(gè)典型的模型簡(jiǎn)單介紹一下。
3. 蒸餾-MiniLM
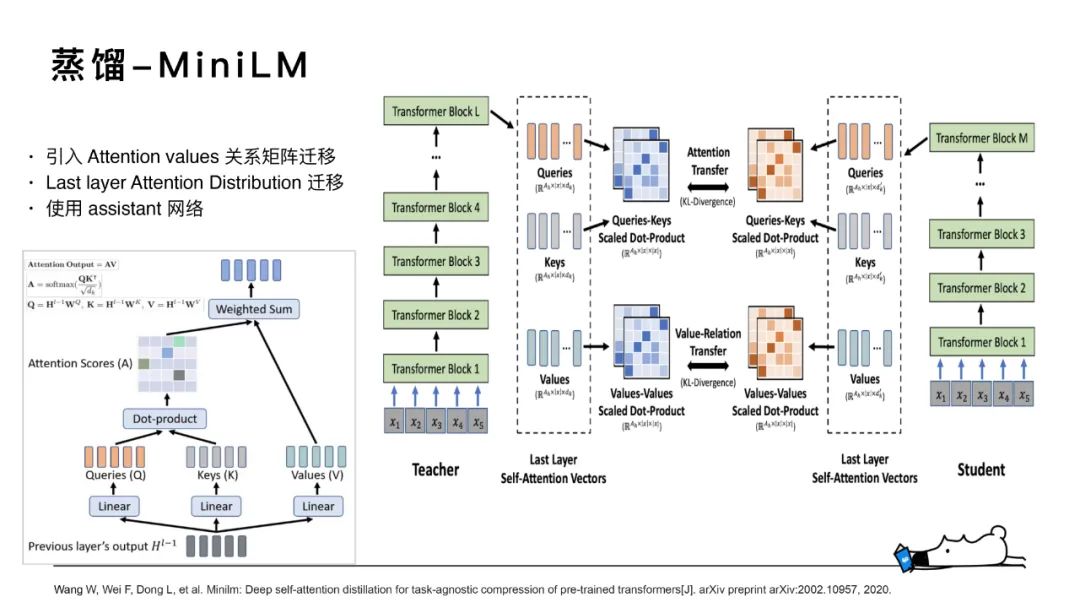
MiniLM是基于預(yù)訓(xùn)練任務(wù)的蒸餾,其是一種通用的面向Transformer-based預(yù)訓(xùn)練模型壓縮算法。主要改進(jìn)點(diǎn)有三個(gè),一是蒸餾teacher模型最后一層Transformer的自注意力模塊,二是在自注意模塊中引入 values-values點(diǎn)乘矩陣的知識(shí)遷移,三是使?了 assistant ?絡(luò)來(lái)輔助蒸餾。
4.蒸餾-BERT to Simple NN
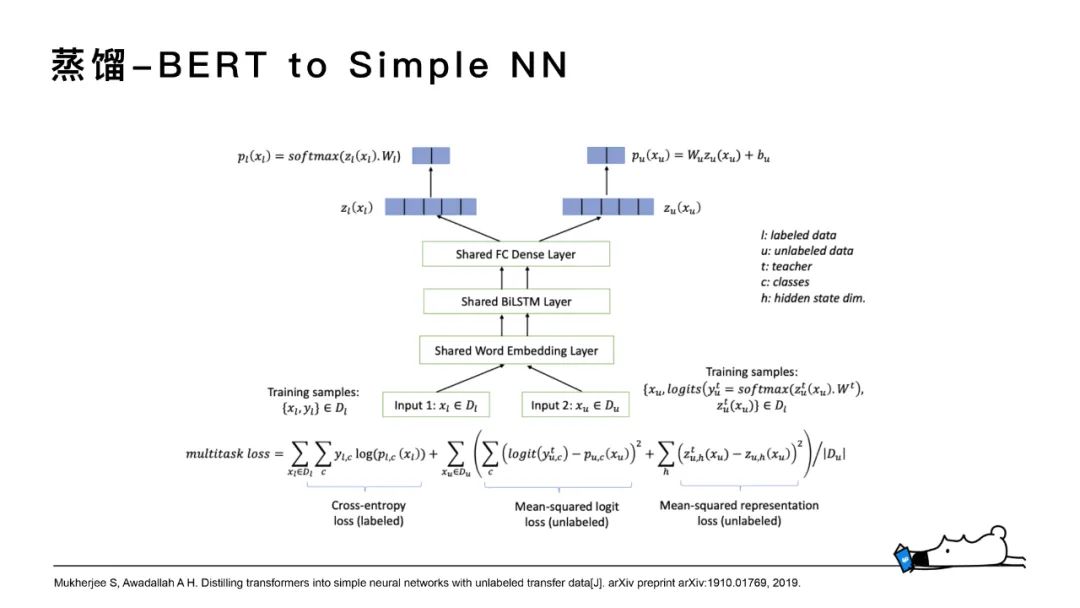
BERT to Simple NN更多的是做了一些loss形式的設(shè)計(jì),使其訓(xùn)練方式更高效。
04
知乎搜索再BERT蒸餾上的實(shí)踐
1.BERT蒸餾上的實(shí)踐和收益

前面的介紹中我有提到,在做 BERT蒸餾前其實(shí)已經(jīng)做了很多嘗試,但是多少都會(huì)有精度的損失。因此,我們做蒸餾的第一目標(biāo)是離線(xiàn)模型對(duì)?線(xiàn)上 BERT精度?損。但對(duì)BERT-base 直接進(jìn)行蒸餾,無(wú)論如何都沒(méi)辦法避免精度的損失,所以我們嘗試用更大的模型(比如BERT-large/Robert-large/XLNET)來(lái)作為 teacher 進(jìn)行蒸餾。這些多層的模型均在我們知乎全量語(yǔ)料先做pretrain,再做fine-tune,得到微調(diào)后的模型再做蒸餾。
2.蒸餾-Patient KD
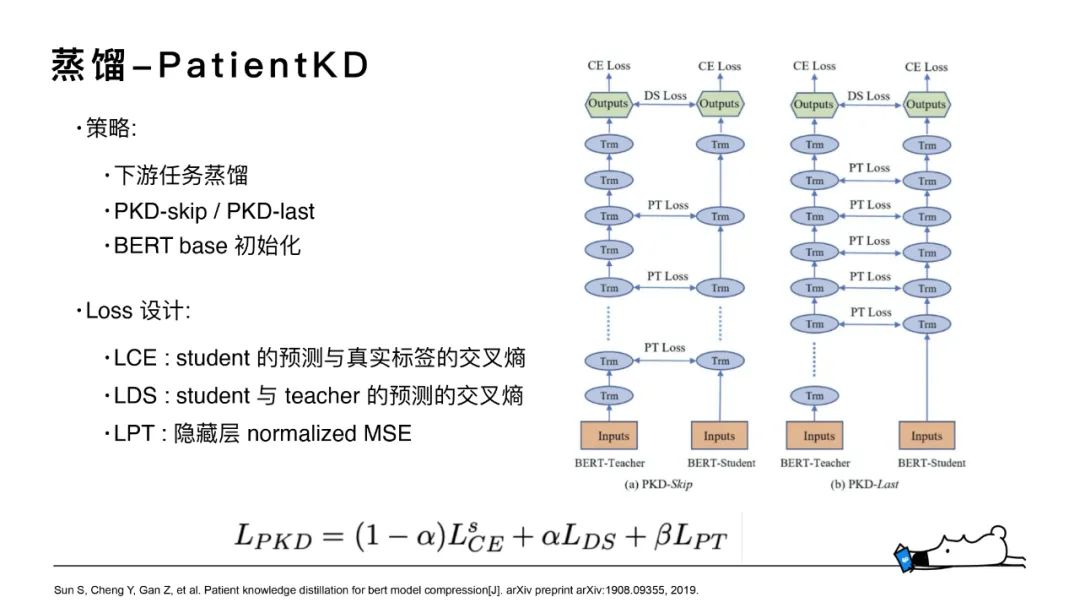
我們對(duì)交互模型和表示模型都做了蒸餾,主要采用了Patient KD模型的結(jié)構(gòu)設(shè)計(jì),Student模型基于BERT-base的若干層運(yùn)用不同的策略進(jìn)行參數(shù)的初始化,去學(xué)習(xí)Robert-large大模型的方案。
其中知識(shí)遷移主要有三部分:student的預(yù)測(cè)與真實(shí)標(biāo)簽的交叉熵、student與teacher的預(yù)測(cè)的交叉熵和中間隱層的向量之間的normalized MSE。
3.BERT交互模型蒸餾

對(duì)于我們選的teacher模型Robert-large,單純預(yù)訓(xùn)練模型其nDCG指標(biāo)為0.914,線(xiàn)上之前使用的BERT-base 是0.907,若對(duì)BERT-base的若干6層直接去做fine-tune能達(dá)到的最高指標(biāo)是0.903,對(duì)比于BERT-base精度會(huì)損失很多。
我們這塊做了一些嘗試,基于Robert-large從24層蒸餾到6層的話(huà)能到0.911,能超過(guò)線(xiàn)上BERT-base的效果。
訓(xùn)練數(shù)據(jù)方面,我們經(jīng)歷了點(diǎn)擊日志數(shù)據(jù)挖掘到逐漸建立起完善的標(biāo)注數(shù)據(jù)集。目前,相關(guān)性任務(wù)訓(xùn)練和蒸餾主要均基于標(biāo)注數(shù)據(jù)集。標(biāo)注數(shù)據(jù)分為 title和 content兩部分,Query 數(shù)量達(dá)到 10w+ 的規(guī)模,標(biāo)注 doc 在 300w ~ 400w 之間。
4. BERT表示模型蒸餾
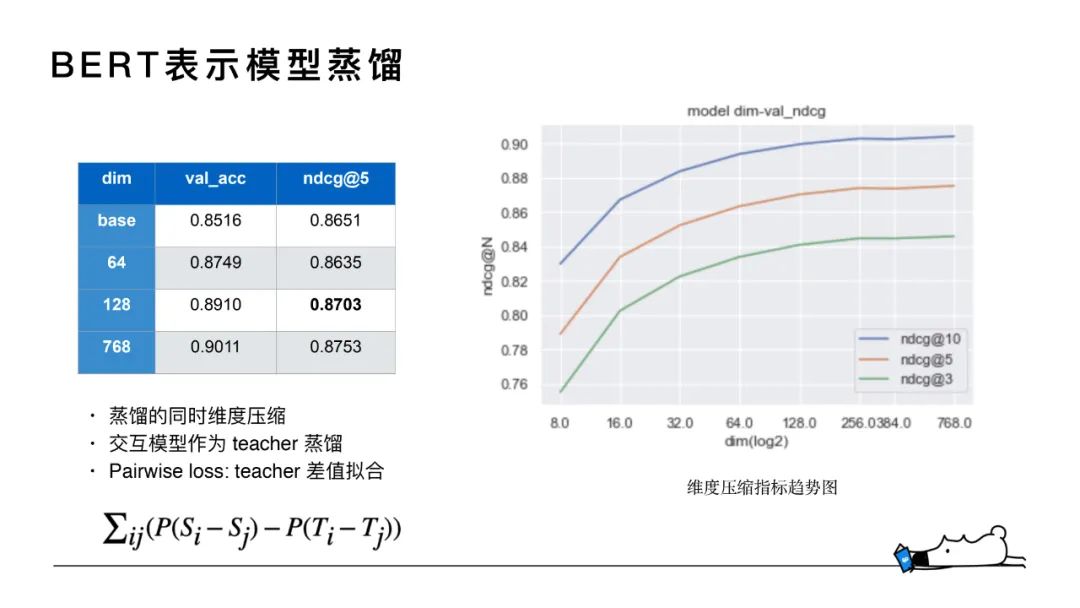
在BERT表示模型上,蒸餾時(shí)我們希望對(duì)向量維度和模型層數(shù)同時(shí)進(jìn)行壓縮,但蒸餾后得到的student模型表現(xiàn)不及預(yù)期。所以最后上線(xiàn)的方案中,表示模型層數(shù)還是維持了12層。在蒸餾時(shí),為了提高精度,選取交互模型作為teacher進(jìn)行蒸餾。因?yàn)榻换ツP褪莙uery和doc之間的打分,交互模型得到的logits與表示模型點(diǎn)乘后的打分在數(shù)量值會(huì)有較大差值,所以用pairwise形式通過(guò)teacher差值擬合來(lái)進(jìn)行l(wèi)oss的計(jì)算。
在維度壓縮方面我們做了對(duì)比實(shí)驗(yàn),BERT模型輸出做 average pooling 后接全連接層分別壓縮至8維到768維。如圖所示,128維和64維的表現(xiàn)跟768維差別不大,在上線(xiàn)時(shí)選擇維度為64和128進(jìn)行嘗試,兩者在線(xiàn)上表現(xiàn)沒(méi)有太明顯的差異,最終選擇了64維的方案,把模型的維度壓縮了12倍,存儲(chǔ)消耗更低。
5. 蒸餾的收益
蒸餾的收益主要分為在線(xiàn)和離線(xiàn)兩部分。

在線(xiàn)方面:
交互模型的層數(shù)從12層壓縮到6層,排序相關(guān)性特征P95減少為原本的1/2,整體搜索入口下降40ms,模型部署所需的GPU機(jī)器數(shù)也減少了一半,降低了資源消耗。
表示模型語(yǔ)義索引存儲(chǔ)規(guī)模title減為1/4,content維度從768維壓縮至64維,雖然維度減少了12倍,但增加了倒排索引doc的數(shù)量,所以content最終減為1/6,
語(yǔ)義索引召回也有比較大的提升,title減少為1/3,content減少為1/2。精排模塊需要線(xiàn)上實(shí)時(shí)查詢(xún)離線(xiàn)計(jì)算好的向量,所以查詢(xún)服務(wù)也有提升。
離線(xiàn)方面:
表示模型語(yǔ)義索引的構(gòu)建時(shí)間減少為1/4,底層知乎自研的TableStore/TIDB存儲(chǔ)減為原來(lái)的1/6,LTR訓(xùn)練數(shù)據(jù)和訓(xùn)練時(shí)間都有很大的提升,粗排早期用的是BM25等基礎(chǔ)特征,后來(lái)引入了32維的BERT向量,提升了精排精度。
責(zé)任編輯:xj
原文標(biāo)題:知乎搜索文本相關(guān)性與知識(shí)蒸餾
文章出處:【微信公眾號(hào):深度學(xué)習(xí)自然語(yǔ)言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
-
文本
+關(guān)注
關(guān)注
0文章
118瀏覽量
17092 -
相關(guān)性
+關(guān)注
關(guān)注
0文章
4瀏覽量
1304 -
自然語(yǔ)言
+關(guān)注
關(guān)注
1文章
288瀏覽量
13360
原文標(biāo)題:知乎搜索文本相關(guān)性與知識(shí)蒸餾
文章出處:【微信號(hào):zenRRan,微信公眾號(hào):深度學(xué)習(xí)自然語(yǔ)言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
云知聲榮獲“2024年上海市專(zhuān)利工作示范單位”認(rèn)定
知乎正式公布三季度財(cái)報(bào):月活躍用戶(hù)數(shù)穩(wěn)步增長(zhǎng)
【AWTK使用經(jīng)驗(yàn)】如何在A(yíng)WTK顯示阿拉伯文本

探索AC自動(dòng)機(jī):多關(guān)鍵詞搜索的原理與應(yīng)用案例
電商搜索革命:大模型如何重塑購(gòu)物體驗(yàn)?
知網(wǎng)狀告AI搜索:搜到我家論文題目和摘要,你侵權(quán)了!
知乎全新AI產(chǎn)品"知乎直答"亮相第十屆鹽Club新知青年大會(huì)
接觸與非接觸式測(cè)量相關(guān)性的方法
逆變器電池用蒸餾水理由,金屬觸點(diǎn)完全浸沒(méi)







 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論