 通過引入實例 scale-uniform 采樣策略與 crop-aware 邊框回歸損失實現 SOTA 性能
通過引入實例 scale-uniform 采樣策略與 crop-aware 邊框回歸損失實現 SOTA 性能
高分辨率圖像上的全景分割面臨著大量的挑戰,當處理很大或者很小的物體時可能會遇到很多困難。來自 Facebook 的研究者通過引入實例 scale-uniform 采樣策略與 crop-aware 邊框回歸損失,能夠在所有尺度上改善全景分割效果,并在多個數據集上實現 SOTA 性能。
全景分割網絡可以應對很多任務(目標檢測、實例分割和語義分割),利用多批全尺寸圖像進行訓練。然而,隨著任務的日益復雜和網絡主干容量的不斷增大,盡管在訓練過程中采用了諸如 [25,20,11,14] 這樣的節約內存的策略,全圖像訓練還是會被可用的 GPU 內存所抑制。明顯的緩解策略包括減少訓練批次大小、縮小高分辨率訓練圖像,或者使用低容量的主干。不幸的是,這些解決方法引入了其他問題:1) 小批次大小可能導致梯度出現較大的方差,從而降低批歸一化的有效性 [13],降低模型的性能 ;2)圖像分辨率的降低會導致精細結構的丟失,這些精細結構與標簽分布的長尾目標密切相關;3)最近的一些工作[28,5,31] 表明,與容量較低的主干相比,具有復雜策略的更大的主干可以提高全景分割的結果。
克服上述問題的一個可能策略是從基于全圖像的訓練轉向基于 crop 的訓練。這被成功地用于傳統的語義分割[25,3,2]。由于任務被限定在逐像素的分類問題,整個問題變得更加簡單。通過固定某個 crop 的大小,精細結構的細節得以保留。而且,在給定的內存預算下,可以將多個 crop 堆疊起來,形成大小合理的訓練批次。但對于更復雜的任務,如全景分割,簡單的 cropping 策略也會影響目標檢測的性能,進而影響實例分割的性能。具體來說,在訓練過程中,從圖像中提取固定大小的 crop 會引入對大目標進行截取的偏置,在對完整圖像進行推斷時低估這些目標的實際邊界框大小(參見圖 1 左)。

為了解決這一問題,Facebook 的研究者進行了以下兩方面的改進。首先,他們提出了一種基于 crop 的訓練策略,該策略可以利用 crop-aware 損失函數(crop-aware bounding box, CABB)來解決裁剪大型目標的問題;其次,他們利用 instance scale-uniform sampling(ISUS)作為數據增強策略來解決訓練數據中目標尺度不平衡的問題。
論文鏈接:https://arxiv.org/abs/2012.07717
研究者表示,他們的解決方案擁有上述從基于 crop 訓練中得到的所有益處。此外,crop-aware 損失還會鼓勵模型預測出與被裁剪目標可視部分一致的邊界框,同時又不過分懲罰超出 crop 區域的預測。
背后的原理非常簡單:雖然一個目標邊界框的大小在裁剪后發生了變化,但實際的目標邊界框可能比模型在訓練過程中看到的還要大。對于超出 crop 可視范圍但仍在實際大小范圍內的預測采取不懲罰的做法,這有助于更好地對原始訓練數據給出的邊界框大小分布進行建模。通過 ISUS,研究者引入了一種有效的數據增強策略,以改進多個尺度上用于目標檢測的特征金字塔狀表示。該策略的目的是在訓練過程中更均勻地在金字塔尺度上分布目標實例監督,從而在推理過程中提高所有尺度實例的識別準確率。
實驗結果表明,研究者提出的 crop-aware 損失函數對具有挑戰性的 Mapillary Vistas、Indian Driving 或 Cityscapes 數據集中的高分辨率圖像特別有效。總體來說,研究者的解決方案在這些數據集上實現了 SOTA 性能。其中,在 MVD 數據集上,PQ 和 mAP 分別比之前的 SOTA 結果高出 4.5% 和 5.2%。
算法介紹
實例 Scale-Uniform 采樣 (ISUS)
研究者對 Samuel Rota Bulo 等人提出的 Class-Uniform 采樣(CUS)方法進行了擴展,創建了全新的 Instance Scale-Uniform 采樣(ISUS)方法。標準的 CUS 數據準備過程遵循四個步驟:1)以均勻的概率對語義類進行采樣;2)加載包含該類的圖像并重新縮放,使其最短邊與預定義大小 s_0 匹配;3)數據增強(例如翻轉、隨機縮放);4)從所選類可見的圖像區域中生成隨機 crop。
在 ISUS 方法中,研究者遵循與 CUS 相同的步驟,只是尺度增強過程是 instance-aware 的。具體地,當在步驟 1 中選擇「thing」類( 可數的 objects,如 people, animals, tools 等),并在完成步驟 2 之后,研究者還從圖像和隨機特征金字塔層級中采樣該類的隨機實例。然后在第 3 步中,他們計算了一個縮放因子σ,這樣所選實例將根據訓練網絡采用的啟發式方法分配到所選層級。
為了避免出現過大或過小的縮放因子,研究者將σ限制在有限范圍 r_th 中。當在步驟 1 中選擇「stuff」類(相同或相似紋理或材料的不規則區域,如 grass、sky、road 等)時,他們遵循標準的尺度增強過程,即從一個范圍 r_st 均勻采樣 σ。從長遠來看,ISUS 具有平滑目標尺度分布的效果,在所有尺度上提供更統一的監督。
Crop-Aware 邊界框 (CABB)
在 crop 操作之后,研究者將真值邊界框 G 的概念放寬為一組與 G|_C 一致的真值框。用ρ(G,C)函數計算給定真值框 G 和 cropping 面積 C,公式如下
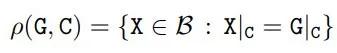
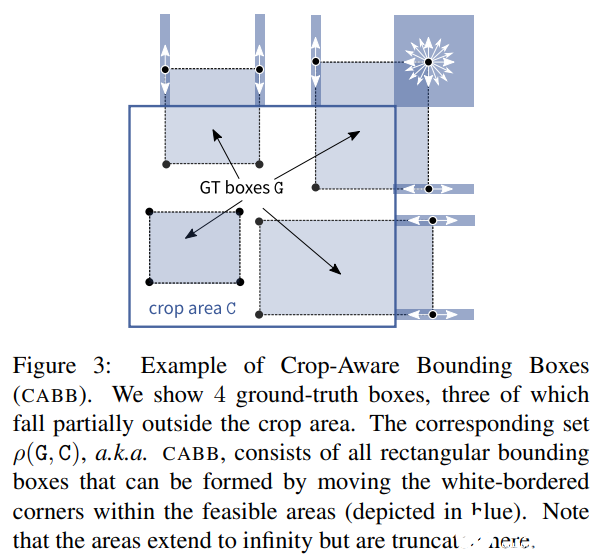
其中 X 覆蓋所有可能的邊界框Β。研究者將 ρ(G, C) 作為 Crop-Aware 邊框(CABB),它實際上是一組邊框(參見下圖 3)。如果真值邊框 G 嚴格地包含在 crop 區域中,那么 CABB 歸結為原始真值,在這種情況下 ρ(G, C) = {G}。
Crop-aware 邊框損失:該研究對給定的真值框 G、anchor 框 A 和 crop 區域 C 引入了以下新的損失函數:
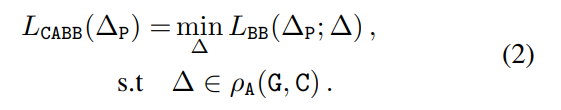
實驗
研究者在以下三個公開高分辨率全景分割數據集上評估了 CABB 損失:它們分別是 Mapillary Vistas(MVD)、Indian Driving Dataset(IDD)和 Cityscapes(CS)。
網絡與訓練細節
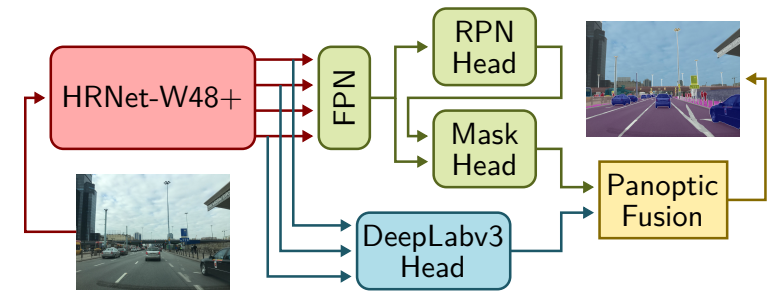
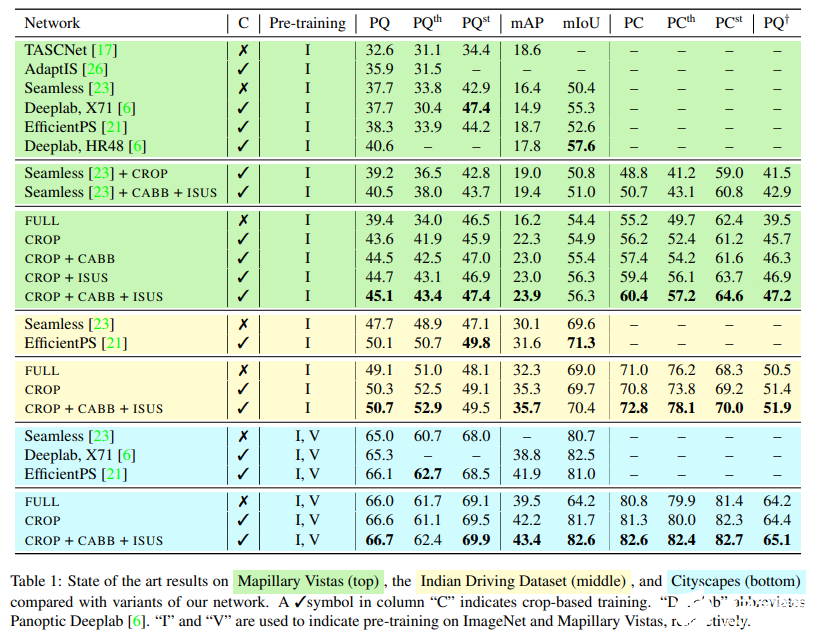
該研究遵循無縫場景分割(Seamless-Scene-Segmentation)[23]框架,并進行了修改。首先,研究者用 HRNetV2-W48+[28,6]替換 ResNet-50 主體,前者是一種專門的骨干網絡,它保存從圖像到網絡最后階段的高分辨率信息;其次,研究者將 [23] 中的 Mini-DL 分割頭替換為 DeepLabV3+[4]模塊,該模塊連接到 HRNetV2-W48 + 主干。最后將同步的 InPlace-ABN [25]應用于整個網絡,并在候選區域和目標檢測模塊中使用 CABB 損失替換標準邊界框回歸損失。
具體流程如下圖所示:
與 SOTA 結果進行比較
下表 1 頂部的 MVD 結果表明,CROP 在所有指標上均優于 FULL,這證明了基于 crop 訓練的優勢。除此以外,即使是該網絡變體中最弱的,也超過了所有的 PQ 基準,唯一的例外是基于 HRNet-W48 的 Panooptic Deeplab 版本。
表 1 中間的 IDD 實驗得到了類似的結果:CROP 在大多數指標上優于 FULL,而 CABB+ISUS 帶來了進一步改進,在 PC 中最為顯著。與之前的工作相比,該研究觀察到 mAP 分數和 SOTA PQ 都有了很大的提高,而分割指標有點落后。
表 1 底部的 Cityscapes 結果呈現相同趨勢,盡管邊際損失(margin)有所下降。需要注意,Cityscapes 是比 IDD 和 MVD 都小的數據集,在某些度量標準中,SOTA 結果接近 90%,因此預計會有較小的改進。盡管如此,與以前最佳方法相比,CROP+CABB+ISUS 在 mAP 上實現了 1.5%以上的顯著提升。
實驗細節
上表 1 為均在 1024×1024 crop 上訓練的兩種設置的結果:從其原始代碼中復制(Seamless + CROP)的未修改網絡 [23],以及結合 CABB 損失和 ISUS 網絡(Seamless+CABB+ISUS)的同一網絡。
與該研究的其他結果一致,基于 crop 訓練的引入相較基準實現了一致改進,特別是在檢測指標方面,同時 CABB 損失和 ISUS 進一步提高了分數,在 PQ w.r.t.Seamelss 上提升了 2.8% 以上。
下圖 6 展示了在具有大型目標的 12Mpixels Mapillary Vistas 驗證圖像上,CROP 與 CROP+CABB+ISUS 的輸出之間的對比情況:

責任編輯:PSY
-
算法
+關注
關注
23文章
4613瀏覽量
92945 -
圖像分割
+關注
關注
4文章
182瀏覽量
18003 -
分割
+關注
關注
0文章
17瀏覽量
11903
發布評論請先 登錄
相關推薦
Mamba入局圖像復原,達成新SOTA
華為云 X 實例 CPU 性能測試詳解與優化策略

華為云Flexus X實例,Redis性能加速評測及對比
Flexus X 實例 CPU、內存及磁盤性能實測與分析
使用PWM實現電源管理的策略
什么是回歸測試_回歸測試的測試策略
PCM1864采樣音頻數據的諧波及底噪可能會是由什么引入的呢?
基于ArkTS語言的OpenHarmony APP應用開發:圖片處理

電流采樣電阻的采樣原理
請問如何才能實現ESP32的2MSPS采樣?
旋變位置不變的情況下,當使能SOTA功能與關閉SOTA功能時,APP中DSADC采樣得到的旋變sin和cos兩者值不一樣,為什么?
Scale out成高性能計算更優解,通用互聯技術大有可為

如何通過GD32 MCU內部ADC參考電壓通道提高采樣精度?
對象檢測邊界框損失函數–從IOU到ProbIOU介紹
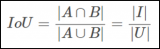





 工商網監
工商網監
評論