 從BERT得到最強句子Embedding的打開方式
從BERT得到最強句子Embedding的打開方式
你有嘗試從 BERT 提取編碼后的 sentence embedding 嗎?很多小伙伴的第一反應是:不就是直接取頂層的[CLS] token的embedding作為句子表示嘛,難道還有其他套路不成?
nono,你知道這樣得到的句子表示捕捉到的語義信息其實很弱嗎?今天向大家介紹一篇來自于 CMU 和字節跳動合作,發表在 EMNLP2020 的 paper, 詳盡地分析了從預訓練模型得到 sentence embedding 的常規方式的缺陷和最佳打開方式,是一篇非常實用、輕松幫助大家用BERT刷分的文章。論文質量蠻高,分析和發現很有趣,通讀之后感覺收獲多多。
自2018年BERT驚艷眾人之后,基于預訓練模型對下游任務進行微調已成為煉丹的標配。然而近兩年的研究卻發現,沒有經過微調,直接由BERT得到的句子表示在語義文本相似性方面明顯薄弱,甚至會弱于GloVe得到的表示。此篇論文中首先從理論上探索了masked language model 跟語義相似性任務上的聯系,并通過實驗分析了BERT的句子表示,最后提出了BERT-Flow來解決上述問題。
為什么BERT的句子Embeddings表現弱?
由于Reimers等人之前已實驗證明 context embeddings 取平均要優于[CLS] token的embedding。因而在文章中,作者都以最后幾層文本嵌入向量的平均值來作為BERT句子的表示向量。
語義相似性與BERT預訓練的聯系
為了探究上述問題,作者首先將語言模型(LM)與掩蓋語言模型(MLM) 統一為: 給定context(c)預測得到 token(x) 的概率分布,即
這里 是context的embedding, 表示 的word embedding。進一步,由于將 embedding 正則化到單位超球面時,兩個向量的點積等價于它們的cosine 相似度,我們便可以將BERT句子表示的相似度簡化為文本表示的相似度,即 。
另外,考慮到在訓練中,當 c 與 w 同時出現時,它們對應的向量表示也會更接近。換句話說,context-context 的相似度可以通過 context-words 之間的相似度推出或加強。
各向異性嵌入空間
Jun Gao, Lingxiao Wang 等人在近幾年的ICLR paper中有提到語言模型中最大似然目標的訓練會產生各向異性的詞向量空間,即向量各個方向分布并不均勻,并且在向量空間中占據了一個狹窄的圓錐體,如下圖所示~
這種情況同樣也存在于預訓練好的基于Transformer的模型中,比如BERT,GPT-2。而在這篇paper中,作者通過實驗得到以下兩個發現:
詞頻率影響詞向量空間的分布:文中通過度量BERT詞向量表示與原點 l_2 距離的均值得到以下的圖表。我們可以看到高頻的詞更接近原點。由于word embedding在訓練過程中起到連接文本embedding的作用,我們所需的句子表示向量可能會相應地被單詞頻率信息誤導,且其保留的語義信息可能會被破壞。

低頻詞分布偏向稀疏:文中度量了詞向量空間中與K近鄰單詞的 l_2 距離的均值。我們可以看到高頻詞分布更集中,而低頻詞分布則偏向稀疏。然而稀疏性的分布會導致表示空間中存在很多“洞”,這些洞會破壞向量空間的“凸性”。考慮到BERT句子向量的產生保留了凸性,因而直接使用其句子embeddings會存在問題。
Flow-based 生成模型
那么,如何無監督情況下充分利用BERT表示中的語義信息?為了解決上述存在的問題,作者提出了一種將BERT embedding空間映射到一個標準高斯隱空間的方法(如下圖所示),并稱之為“BERT-flow”。而選擇 Gaussian 空間的動機也是因為其自身的特點:
標準高斯分布滿足各向同性
高斯分布區域沒有“洞”,即不存在破壞“凸性”的情況
上圖中 表示隱空間, 表示觀測到的空間,f: 是可逆的變換。根據概率密度函數中變量替換的定理,我們可以得到觀測變量的概率密度函數如下:
進一步,作者通過最大化BERT句子表示的邊緣似然函數來學習基于流的生成模型,即通過如下的公式來訓練flow的參數:
其中 表示數據集分布, 為神經網絡。需要注意的是,在訓練中,不需要任何人工標注!另外,BERT的參數保持不變,僅有流的參數進行優化更新。其次,在實驗中,作者基于Glow (Dinh et al., 2015)的設計(多個可逆變換組合)進行改動,比如將仿射耦合(affine coupling)替換為了加法耦合(additive coupling)。
實驗及結果
論文的實驗部分在7個數據集上進行衡量語義文本相似性任務的效果。
實驗步驟:
通過句子encoder得到每個句子的向量表示。
計算句子之間的cosine similarity 作為模型預測的相似度。
計算Spearman系數。
實驗結果:
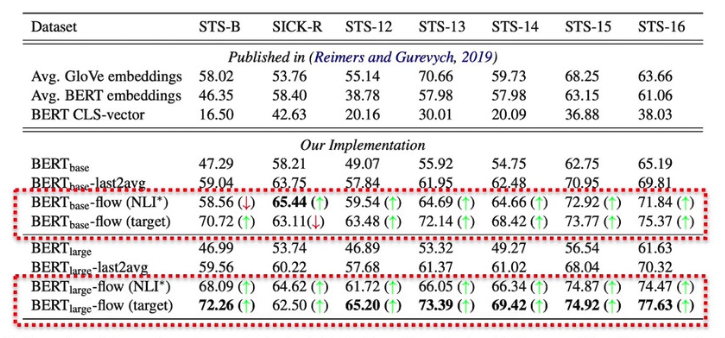
上圖匯報了sentence embeddings的余弦相似度同多個數據集上真實標簽之間的Spearman等級相關性得分(),其中flow-target 表示在完整的目標數據集(train+validation+test)上進行學習,flow-NLI 表示模型在NLI(natual language inference)任務的測試,綠色箭頭表示相對于BERT的baseline,模型的效果有提升,紅色反之。
我們可以注意到模型的改進對于效果的提升還是很顯著滴!文章同樣還在無監督問答任務證明模型的有效性,并將BERT-flow得到的語義相似度同詞法相似度(通過編輯距離來衡量)進行對比,結果同樣證明模型在引入流的可逆映射后減弱了語義相似性與詞法相似性之間的聯系!具體信息大家可查閱paper~
小結
總之,這篇paper探究了BERT句子表示對于語義相似性上潛在的問題,并提出了基于流的可逆映射來改進在對應任務上的表現。想多了解的童鞋可以看看原文,相信你們也會喜歡上這篇paper!
原文標題:還在用[CLS]?從BERT得到最強句子Embedding的打開方式!
文章出處:【微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
責任編輯:haq
-
計算機
+關注
關注
19文章
7572瀏覽量
89035 -
模型
+關注
關注
1文章
3406瀏覽量
49457
原文標題:還在用[CLS]?從BERT得到最強句子Embedding的打開方式!
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
接入AI大模型!利爾達蜂窩模組讓設備秒變“機靈小話癆”

Giada杰和科技ISE展會直擊|在巴塞羅那,遇見視聽未來的N種打開方式

【「基于大模型的RAG應用開發與優化」閱讀體驗】+Embedding技術解讀
掌握壓鑄鋁件氣密性檢測設備的正確打開方式-岳信儀器

嵌入式學習-飛凌嵌入式ElfBoard ELF 1板卡 -通用文件I/O模型之open
飛凌嵌入式ElfBoard ELF 1板卡-通用文件I/O模型之open
內置誤碼率測試儀(BERT)和采樣示波器一體化測試儀器安立MP2110A

M8020A J-BERT 高性能比特誤碼率測試儀
換熱設備清洗的正確打開方式,不僅清洗效果好,而且安全無腐蝕

AWG和BERT常見問題解答
新品|酷暑的新打開方式:SXB3568主板

Jacob:純提效的工具,也許不是AI正確的打開方式

汽車水箱氣密性檢測儀的正確打開方式






 工商網監
工商網監
評論