 如何用Bazel構建C++項目
如何用Bazel構建C++項目
前言
眾所周知,C/C++ 語言具備很強可移植性,作為高級的底層語言能兼容各式各樣的系統環境或應用。因此很多企業更偏向于將算法用 C/C++ 實現,從而減少不同業務平臺下的算法維護成本。所以,我們對 TensorFlow Lite 的 C++ 接口有很強的現實需求。然而,關于 TensorFlow Lite C++ 接口的詳細教程和案例不太常見,但它實際上并不復雜。因而,我參考 MediaPipe 整理一個案例項目分享到社區,希望能幫助有需要的同學。
編譯構建
我們創建一個 C++ 項目后,一般會先考慮編譯環境的搭建問題。
Bazel 是一個類似 Make、Maven 和 Gradle 的構建與測試工具。它的高級構建語言具有很好的可讀性。Bazel 支持多語言跨平臺的構建項目。它還支持大量用戶協作開發涵蓋多個代碼倉庫的大型代碼庫。它具有構建語言可讀性強、構建高速可靠、跨平臺兼容、大規模構建和擴展構建等優點。因此,我們這個項目采用 Bazel 作為構建工具,方便 TensorFlow Lite 與 OpenCV 等第三方庫的代碼版本管理。首先,我們一起了解一下如何用 Bazel 構建 C++ 項目。
設置構建環境
在構建項目之前,我們需要設置項目的構建環境 (Workspace)。構建環境表示一個目錄包含所有我們的代碼源文件與 Bazel 的構建結果輸出文件。其中有些文件會引導 Bazel 如何進行項目編譯:
WORKSPACE,它一般被放在項目的根目錄底下,負責導入第三方庫的代碼控制與管理。
BUILD,通常一個項目有很多個,它們負責告訴 Bazel 如何編譯項目的各個不同模塊。通常,構建環境下的每個模塊包 (Package) 目錄下都會有一個 BUILD。
下面是我們案例項目的目錄結構:
image-classifier ├── LICENSE ├── README.md ├── WORKSPACE ├── image_classifier │ ├── BUILD │ ├── apps │ │ ├── desktop │ │ │ ├── BUILD │ │ │ └── main.cc │ └── cc │ ├── BUILD │ ├── classifier_float_mobilenet.cc │ ├── classifier_float_mobilenet.h │ ├── image_classifier.cc │ ├── image_classifier.h │ ├── image_classify_service.cc │ ├── image_classify_service.h │ └── utils.h └── third_party ├── BUILD ├── com_google_absl_f863b622fe13612433fdf43f76547d5edda0c93001.diff ├── opencv_linux.BUILD ├── opencv_macos.BUILD └── org_tensorflow_compatibility_fixes.diff
我們將項目劃分成兩個模塊,第三方庫 third_party 和圖像分類模塊 image_classifier,其中 image_classifier 又分成 apps 應用模塊和 cc 代碼實現模塊。每模塊的具體設計后文詳細介紹,我們先看看構建環境的細節配置。
workspace(name = "image_classifier") load("@bazel_tools//tools/build_defs/repo:http.bzl", "http_archive") skylib_version = "0.9.0" http_archive( name = "bazel_skylib", type = "tar.gz", url = "https://github.com/bazelbuild/bazel-skylib/releases/download/{}/bazel_skylib-{}.tar.gz".format (skylib_version, skylib_version), sha256 = "1dde365491125a3db70731e25658dfdd3bc5dbdfd11b840b3e987ecf043c7ca0", ) load("@bazel_skylib//lib:versions.bzl", "versions") versions.check(minimum_bazel_version = "2.0.0") # ABSL cpp library lts_2020_02_25 http_archive( name = "com_google_absl", urls = [ "https://github.com/abseil/abseil-cpp/archive/20200225.tar.gz", ], # Remove after https://github.com/abseil/abseil-cpp/issues/326 is solved. patches = [ "@//third_party:com_google_absl_f863b622fe13612433fdf43f76547d5edda0c93001.diff" ], patch_args = [ "-p1", ], strip_prefix = "abseil-cpp-20200225", sha256 = "728a813291bdec2aa46eab8356ace9f75ac2ed9dfe2df5ab603c4e6c09f1c353" ) new_local_repository( name = "linux_opencv", path = "/usr", build_file="@//third_party:opencv_linux.BUILD" ) new_local_repository( name = "macos_opencv", build_file = "@//third_party:opencv_macos.BUILD", path = "/usr", ) # Needed by TensorFlow http_archive( name = "io_bazel_rules_closure", sha256 = "e0a111000aeed2051f29fcc7a3f83be3ad8c6c93c186e64beb1ad313f0c7f9f9", strip_prefix = "rules_closure-cf1e44edb908e9616030cc83d085989b8e6cd6df", urls = [ "http://mirror.tensorflow.org/github.com/bazelbuild/rules_closure/archive/cf1e44edb908e9616030cc83d085989b8e6cd6df.tar.gz", "https://github.com/bazelbuild/rules_closure/archive/cf1e44edb908e9616030cc83d085989b8e6cd6df.tar.gz", # 2019-04-04 ], ) #Tensorflow repo should always go after the other external dependencies. # 2020-08-30 _TENSORFLOW_GIT_COMMIT = "57b009e31e59bd1a7ae85ef8c0232ed86c9b71db" _TENSORFLOW_SHA256= "de7f5f06204e057383028c7e53f3b352cdf85b3a40981b1a770c9a415a792c0e" http_archive( name = "org_tensorflow", urls = [ "https://github.com/tensorflow/tensorflow/archive/%s.tar.gz" % _TENSORFLOW_GIT_COMMIT, ], patches = [ "@//third_party:org_tensorflow_compatibility_fixes.diff", ], patch_args = [ "-p1", ], strip_prefix = "tensorflow-%s" % _TENSORFLOW_GIT_COMMIT, sha256 = _TENSORFLOW_SHA256, ) load("@org_tensorflow//tensorflow:workspace.bzl", "tf_workspace") tf_workspace(tf_repo_name = "org_tensorflow")
上面是 image-classifier 的 WORKSPACE 配置,他導入 versions 對象檢查 Bazel 版本,加載 http_archive 函數管理 org_tensorflow、opencv、abseil 等類似的第三方庫。其中 abseil 庫很值得推薦,它是集成不少 C++14/17 新特性的工具庫,類似于 Boost 卻體積特別輕巧方便。我們經常會在 Google 開源代碼中看見它們的身影,如 absl::make_unique,absl::StrJoin 等等,因此我把這個項目引入到代碼里方便一些字符串和智能指針的處理。
接著,我們看看不同目錄下的 BUILD 文件是如何配置的。
image_classifier/apps/desktop/BUILD
cc_binary( name = "image_classifier.exe", srcs = ["main.cc"], deps = [ "@//third_party:opencv", "http://image_classifier/cc:image_classifier", ], )
我們看到 image_classifier/apps/desktop/BUILD 正在描述一個可執行文件的編譯依賴關系。其中,cc_binary 就表示編譯的輸出結果是二進制可執行文件,name 表示這個輸出文件的名字,srcs 是可執行文件編譯時依賴的一些源文件,deps 是指編譯鏈接過程中依賴的其他模塊目錄。我們很容易觀察出,這個目錄的 BUILD 其實描述的是一個桌面應用的主函數編譯過程,畢竟 srcs 依賴了一個 apps/desktop/main.cc(碼農們的命名習慣)。另外,還可以看到 deps 的依賴表里面的 "@//third_party:opencv" 比 "http://image_classifier/cc:image_classifier" 多了一個 @ 符號,它表示外部第三方庫的依賴。而 "http://image_classifier/cc:image_classifier" 表示我們從目錄 image_classifier/cc 引用 image_classifier 模塊。
image_classifier 模塊的 BUILD 描述如下:
image_classifier/cc/BUILD
cc_library( name = "image_classifier", srcs = glob(["*.cc"]), hdrs = glob(["*.h"]), visibility = ["http://visibility:public"], deps = [ "@com_google_absl//absl/memory", "@org_tensorflow//tensorflow/lite:builtin_op_data", "@org_tensorflow//tensorflow/lite/kernels:builtin_ops", "@org_tensorflow//tensorflow/lite:framework", "@//third_party:opencv", ], )
image_classifier/cc/BUILD 正在描述一個 C++ 庫文件的編譯依賴關系。很容易注意到,這個 BUILD 文件與前面都寫區別。首先,我用 cc_library 函數告訴 Bazel 這個目錄的編譯輸出的結果是一個庫文件。其次,我用 glob 函數實現對 image_classifier/cc/目錄下所有 .cc 和 .h 文件進行依賴,hdrs 表示需要依賴包含的頭文件。然后,我通過 visiblity 屬性對外部模塊公開 API 的細節,方便 apps/desktop 等其他模塊的調用,具體細節可以參考 Bazel 的編譯規則說明。最后,不難發現我的 deps 引用了 TensorFlow Lite 的關鍵模塊,因為 TensorFlow Lite 在我的案例項目中屬于外部第三方庫,所以關鍵模塊的路徑前面有一個 @ 符號。
Bazel 的編譯規則說明
https://docs.bazel.build/versions/3.6.0/be/c-cpp.html
構建環境搭建完成后,我們就可以運行 Bazel 進行項目的編譯構建。
$ bazel build -c opt --experimental_repo_remote_exec //image_classifier/apps/desktop:image_classifier.exe
其中 -c opt表示 C 的編譯優化,--experimental_repo_remote_exec僅為處理第三方庫的編譯問題。最后,以 MacOS 為例,我們可以執行這個二進制可執行文件。
$ ./bazel-bin/image_classifier/apps/desktop/image_classifier.exe
如果有同學在構建過程中遇到問題,請到 Issue 反饋你構建的情況。
代碼結構
我們結合目錄結構和構建文件配置,分析源碼可以得到下面的代碼結構示意圖。
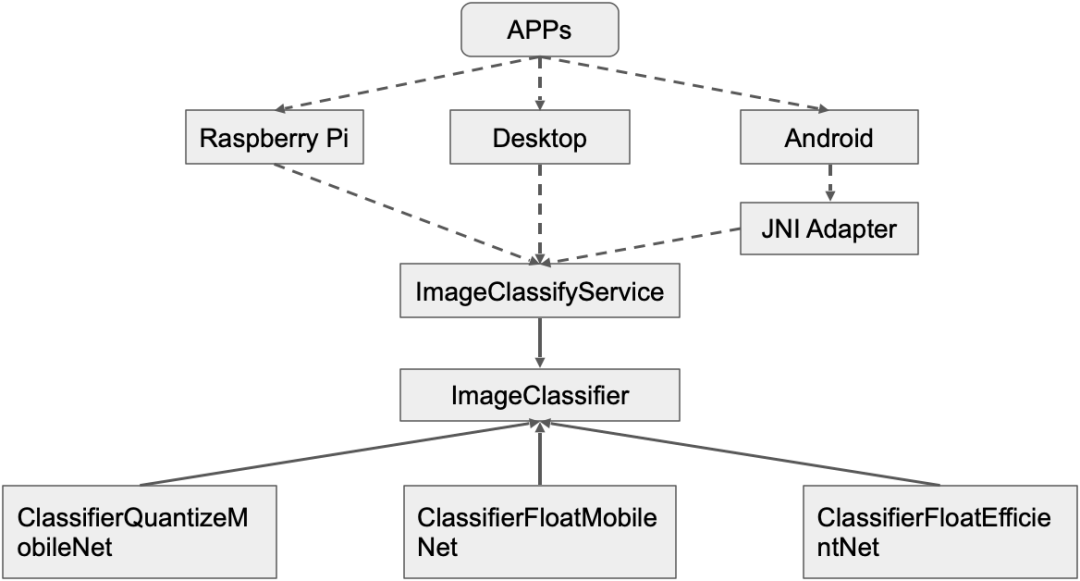
這是案例項目的代碼結構設計,在企業開發中我們總是希望自己的算法代碼無須修改即可跨平臺復用,減少維護成本,但算法的實現卻總會不斷地被優化。因此,我設計一個 ImageClassifyService 作為業務算法代理提供服務,不同平臺的 APP 開發者根據需求平臺的情況在接口適配層調用這個代理為應用提供接口。比如,Android 平臺的開發者可以在 JNI 層調用 C++ 類 ImageClassifyService 的 RecognizeImage 接口封裝圖像分類識別的功能給 Java 層使用。一般這種情況,我會把 ImageClassifyService 設計成單例方便管理,畢竟移動端資源緊張,不會同時運行兩個分類服務。哪怕出現墨菲定律的情況,我們也應該修改 ImageClassifyService,讓他提供兩個適合同時分類服務的接口。但是,這對于一個入門教程案例來說過于復雜,所以我沒在案例代碼做類似的實現。
然后,ImageClassifyService 有一個 ImageClassifier 抽象成員負責完成具體的分類任務。前面說過,具體的圖像分類實現會經常被修改優化,甚至會做 A/B 測試。因此,我沿用 TFLite Android 官方案例的設計模式,讓 ImageClassifier 組合不同的實現,如 ClassifierFloatMobileNet,ClassifierEfficientNet 等。
TFLite Android 官方案例
https://github.com/tensorflow/examples/tree/master/lite/examples/image_classification/android
模型分析
因為我們正在開發的 C++ 項目與深度學習有關,所以我們很難避免模型在不同推理框架的轉換問題。然而,本教程主要目的是 TensorFlow Lite C++ 部署流程說明,因此我不在本文詳細描述模型的轉換方法,有需要的讀者可以參考官方文檔。我的案例模型是從 TFLite Android 官方示例程序拷貝的,部署前我習慣于對準備使用的模型進行觀察分析,以便關注到一些模型的輸入預處理和輸出后處理的注意事項。TFLite 的模型分析工具有 visualize 和 minimal,其中 visualize 是官方主推的分析工具,能圖示模型的推理流程。而 minimal 作為 TFLite 的Examples也能顯示 TFLite 模型的詳情信息,但是無模型圖示。
官方文檔
https://tensorflow.google.cn/lite/convert?hl=zh_cn
TFLite Android 官方示例程序
https://github.com/tensorflow/examples/tree/master/lite/examples/image_classification/android
Examples
https://github.com/tensorflow/tensorflow/tree/master/tensorflow/lite/examples/minimal
Interpreter has 103 tensors and 31 nodes Inputs: 87 Outputs: 86 Tensor 0 MobilenetV1/Conv2d_0/weights kTfLiteFloat32 kTfLiteMmapRo 3456 bytes ( 0.0 MB) 32 3 3 3 Tensor 1 MobilenetV1/Conv2d_10_depthwise/depthwise_weights kTfLiteFloat32 kTfLiteMmapRo 18432 bytes ( 0.0 MB) 1 3 3 512 Tensor 2 MobilenetV1/Conv2d_10_pointwise/weights kTfLiteFloat32 kTfLiteMmapRo 1048576 bytes ( 1.0 MB) 512 1 1 512 ... Tensor 84 MobilenetV1/MobilenetV1/Conv2d_9_pointwise/Conv2D_bias kTfLiteFloat32 kTfLiteMmapRo 2048 bytes ( 0.0 MB) 512 Tensor 85 MobilenetV1/MobilenetV1/Conv2d_9_pointwise/Relu6 kTfLiteFloat32 kTfLiteArenaRw 401408 bytes ( 0.4 MB) 1 14 14 512 Tensor 86 MobilenetV1/Predictions/Reshape_1 kTfLiteFloat32 kTfLiteArenaRw 4004 bytes ( 0.0 MB) 1 1001 Tensor 87 input kTfLiteFloat32 kTfLiteArenaRw 602112 bytes ( 0.6 MB) 1 224 224 3 Tensor 88 (null) kTfLiteFloat32 kTfLiteArenaRwPersistent 3456 bytes ( 0.0 MB) 27 32 Tensor 89 (null) kTfLiteFloat32 kTfLiteArenaRwPersistent 8192 bytes ( 0.0 MB) 32 64 ... Tensor 102 (null) kTfLiteFloat32 kTfLiteArenaRwPersistent 4100096 bytes ( 3.9 MB) 1024 1001
上面的 MobileNetV1 模型,我們可以看到它有 102 個張量 (tensor),其中 15 個中間特征映射 (Feature Map) 張量沒有節點名字 (Node Name) 而不可見。我們分析模型的輸入輸出張量,Tensor 87 和 Tensor 86。這個 MobileNetV1 的張量索引 (Tensor Index) 比較獨特,它的輸入張量索引為 87 與輸出索引的 86 鄰近,張量索引其實只是 TensorFlow Lite 對模型參數和中間特征映射的內存進行編號標記,方便在 AllocateTensors 安排模型執行順序時找到對應的張量。另外,我們還能看到這兩個輸入輸出內存的 Memory 類型都是 kTfLiteArenaRw,它表示內存可讀寫。有的模型參數的 Memory 類型是 kTfLiteMmapRo 是只讀內存,一般我們代碼無法訪問。還有的是 kTfLiteDynamic 類型,它會根據輸入情況動態調整內存大小,我只在 ResizeOp 遇到過這種類型。有時 ResizeOp 的輸出張量大小 (Size) 是固定 kTfLiteMmapRo 的,動態修改 ResizeOp 的輸入大小會導致 AllocateTensors 分配內存不對的情況。關于這個 ResizeOp Dynamic Shape 的問題,我們將在后文詳細討論。現在,我們基本清楚 MobileNetV1 的 tflite 模型細節,下面我們看看如何利用這些模型細節進行推理實現圖像分類算法。
算法實現
在了解模型細節信息后,我們就可以按照下面的基本流程實現算法的部署。
// minimal.cc 官方案例實現 // Load model std::unique_ptr
大致分為 5 個步驟: 1. 從文件加載模型并建立模型解釋器 (Interpreter),BuiltinOpResolver 表示用 TFLite 內部算子 (Ops) 解析模型,如果有自定義算子 (Custom Ops) 的情況,我們會在這個階段進行算子注冊。自定義算子是屬于高階技能,這份入門級教程不做過多詳細介紹,有興趣的同學可以參考官方文檔。將 BuiltinOpResolver 和 FlatBufferModel 組合構造出一個解釋器建造者 (Interpreter Builder),利用這個建造者初始化模型解釋器。這時,解釋器里面已經擁有模型的具體細節信息,并知道該用何種實現運行這個模型。
官方文檔
https://tensorflow.google.cn/lite/guide/ops_custom?hl=zh_cn
2. 分配張量推理運行內存 (Allocate tensor buffers),因為大多情況下深度學習模型的運行內存消耗都比較固定,所以提前計算分配有利于減少動態內存分配的資源消耗。然而,有時候我們會遇到類似人臉識別、文本識別等后級網絡模型的輸入圖像的數量并不確定的情況,畢竟檢測器能從圖像定位多少個目標與場景有關,場景包含目標的個數是隨機的。這時,我們可以利用 ResizeInputTensor 設置輸入 batch size。代碼片段如下:
// kInputIndex 是輸入張量索引,kNum 是輸入圖片張數,即 batch size。 interpreter_->ResizeInputTensor(kInputIndex, {kNum, kInputHeight, kInputWidth, kInputChannels}); // 按照新的輸入張量的大小重新分配內存。 interpreter_->AllocateTensors(); // 循環填充輸入張量的內存,其中 kInputIndex 是輸入張量索引。 float* input_buffer = interpreter_-> typed_tensor
3. 將輸入數據填入輸入張量。一般我們會在這步做一些數據預處理操作比如白化、數據類型轉換等。如果是多圖片同時預測的情況,可以參考上面的代碼片段。
4. 運行深度學習網絡模型推斷過程,這時候只用簡單調用 Interpreter::Invoke 接口,檢查是否有返回錯誤即可。
5. 如果模型推斷過程沒有發生錯誤,那么網絡模型的推斷結果就會被放到 Interpreter 的輸出張量上。我們只需要讀取并按照業務邏輯進行后處理解析,就能得到期望的業務結果。
值得注意的是,ResizeInputTensor,AllocateTensors,Invoke都是有返回值可以檢查的,我建議盡量不要直接用默認的 assert 斷言處理。因為我在 MacOS 用 Bazel 構建時,發現 assert(interpreter_->AllocateTensors())竟然沒有執行,這可能是 Bazel 構建程序時會默認屏蔽 assert 斷言,具體情況請感興趣的同學自行研究,所以我教程案例中寫了一個 CHECK 宏函數處理這個問題。
另外,我們還需要注意 Interpreter::typed_tensor 與 Interpreter::typed_input_tensor的細微差別,他們的輸入參數雖然都是索引 (Index),但是 typed_tensor 的參數是張量索引,而 typed_input_tensor是輸入張量的序號,比如 MobileNetV1模型的輸入張量索引是 87 但序號是 0,假如我不小心錯寫成 float* input_buffer = interpreter_ -> typed_input_tensor
最后,我們討論一下關于 ResizeOp 的問題。前文提到, AllocateTensor 有時無法正確推理 ResizeOp 的輸出結果大小 (Size),從而導致內存錯誤的情況。發生該問題的主要原因是,模型轉換器 (TFLite Converter) 一般會認為 ResizeOp 的輸出大小 (Size) 是常量,并在轉換過程對其常量化,導致縮放算子輸出大小固定 (Fixed ResizeOp Output Size) 的情況。對于這個問題,我們討論下面兩種解決思路。
思路一
首先,我們考慮修改模型轉換部分的 Python 代碼,用 tf.shape 獲取輸入張量的大小,從而動態控制 ResizeOp 的縮放比例,實現對其輸出結果大小的修改。代碼片段大致如下:
import tensorflow.compat.v1 as tf import numpy as np tf.disable_v2_behavior() input_t = tf.placeholder(dtype=tf.float32, shape=[1, None, None, 3]) shape = tf.shape(input_t) h = shape[1] // 2 w = shape[2] // 2 out_t = tf.compat.v1.image.resize_bilinear(input_t, [h, w]) with tf.Session() as sess: converter = tf.lite.TFLiteConverter(sess.graph_def, [input_t], [out_t]) tfl_model = converter.convert() interpreter = tf.lite.Interpreter(model_content=tfl_model) input_index = (interpreter.get_input_details()[0]['index']) interpreter.resize_tensor_input(input_index, tensor_size=[1, 300, 300, 3]) try: interpreter.allocate_tensors() except ValueError: assert False random_input = np.array(np.random.random([1, 300, 300, 3]), dtype=np.float32) interpreter.set_tensor(input_index, random_input) interpreter.invoke() output_index = (interpreter.get_output_details()[0]['index']) result = interpreter.get_tensor(output_index) print(result.shape)
從上面的代碼片段,我們只要修改 resize_tensor_input 的 tensor_size,result.shape 就是它的 0.5 倍。
思路二
另外,我們還可以考慮在模型轉換時配置適合的輸入大小,然后在預處理做一些 Crop-Padding-Resize 的操作,最后對模型的輸出結果按照 Reisze 的比例進行解析得到我們期望的結果。具體的操作流程與原理如下圖所示:
深度學習模型在訓練階段其實也是通過預處理固定輸入大小的,因此推理階段使用原有的輸入大小其實并不會引入太多的誤差。
TensorFlow Lite 現在也開始逐漸支持 Dynamic Shape ,同時也有一些修改 tflite::Interpreter 的模型信息的 Hack 技巧,這里我不一一介紹了,有興趣可以關注我知乎的其他文章。
知乎
https://www.zhihu.com/people/hu-xu-hua-4
效果展現
可以看到我的教程案例效果與官方教程的效果基本一致。
未來的工作
有些同學可能發現我并沒有把代碼類圖結構中的 Raspberry Pi 和 Android 部分進行實現。實際上,我只完成了 TFLite C++ API 應用的主干流程。因此,我仍需努力完成 Raspberry Pi 的編譯支持與 Android 的應用層案例實現。而且,Tensorflow Lite 團隊最近又推出了能減少開發工作量的新特性——Tensorflow Lite Library TaskAPI,現在這一新特性在 tflite-support 的項目里面與 Android TFLite metadata 代碼生成器放在一起。
tflite-support
https://github.com/tensorflow/tflite-support
所以,我希望未來能在這個教程案例項目集成類似 TFLite-support 的新特性幫助大家節省工作量。另外,這個案例代碼只有 TFLite 算子的標準 C++ 實現,并未涉及 GPU 與 SIMD 等指令集優化的 TFLite Delegate API 應用。盡管這些算子指令優化受限于移動設備的訪存帶寬影響,未必達到顯著優化效果,但我相信隨著硬件設備與軟件框架的更新迭代,這些問題終將被一一解決。
這個教程案例
http://github.com/SunAriesCN/image-classifier
TFLite Delegate API
https://tensorflow.google.cn/lite/performance/delegates
這個開源的教程案例項目現在可能并不完美,畢竟我的個人的時間和能力都相當有限。然而,我期望這個項目最終能幫助各位開發者在人工智能時代展現出自身優勢,應用開發者做有趣好玩的智能應用,架構性能優化師能讓用戶體驗流暢的智能交互,算法研發人員能帶來各種奇妙的黑科技等等。
責任編輯:lq
-
C++
+關注
關注
22文章
2114瀏覽量
73831 -
代碼
+關注
關注
30文章
4823瀏覽量
68985 -
tensorflow
+關注
關注
13文章
329瀏覽量
60615
原文標題:社區分享 | TensorFlow Lite C++ API 開源案例教程
文章出處:【微信號:tensorflowers,微信公眾號:Tensorflowers】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
Spire.XLS for C++組件說明
同樣是函數,在C和C++中有什么區別
Klocwork 2024.3新特性速覽


用GNU構建裸機系統
ModusToolbox 3.2在c代碼中包含c++代碼的正確步驟是什么?
C++中實現類似instanceof的方法

如何在FX3 SuperSpeed explorer等電路板上使用openOCD調試C++項目?
如何用CubeMX產生C++專案?
鴻蒙OS開發實例:【Native C++】
使用 MISRA C++:2023? 避免基于范圍的 for 循環中的錯誤






 工商網監
工商網監
評論