") 運(yùn)用多種機(jī)器學(xué)習(xí)方法比較短文本分類處理過(guò)程與結(jié)果差別
運(yùn)用多種機(jī)器學(xué)習(xí)方法比較短文本分類處理過(guò)程與結(jié)果差別
目標(biāo)
從頭開(kāi)始實(shí)踐中文短文本分類,記錄一下實(shí)驗(yàn)流程與遇到的坑運(yùn)用多種機(jī)器學(xué)習(xí)(深度學(xué)習(xí) + 傳統(tǒng)機(jī)器學(xué)習(xí))方法比較短文本分類處理過(guò)程與結(jié)果差別
工具
深度學(xué)習(xí):keras
傳統(tǒng)機(jī)器學(xué)習(xí):sklearn
參與比較的機(jī)器學(xué)習(xí)方法
CNN 、 CNN + word2vec
LSTM 、 LSTM + word2vec
MLP(多層感知機(jī))
樸素貝葉斯
KNN
SVM
SVM + word2vec 、SVM + doc2vec
第 1-3 組屬于深度學(xué)習(xí)方法,第 4-6 組屬于傳統(tǒng)機(jī)器學(xué)習(xí)方法,第 7 組算是種深度與傳統(tǒng)合作的方法,畫風(fēng)清奇,拿來(lái)試試看看效果
源代碼、數(shù)據(jù)、word2vec模型下載
github:https://github.com/wavewangyue/text-classification
word2vec模型文件(使用百度百科文本預(yù)訓(xùn)練)下載:https://pan.baidu.com/s/13QWrN-9aayTTo0KKuAHMhw;提取碼 biwh
數(shù)據(jù)集:搜狗實(shí)驗(yàn)室 搜狐新聞數(shù)據(jù) 下載地址:http://www.sogou.com/labs/resource/cs.php
先上結(jié)果
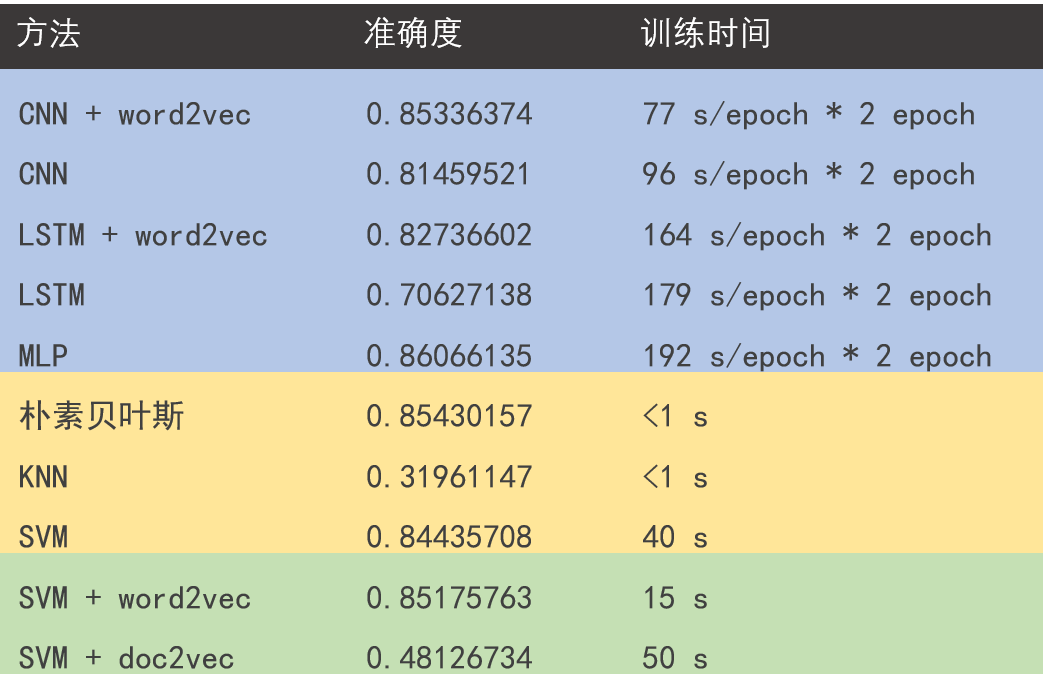
實(shí)驗(yàn)結(jié)論
引入預(yù)訓(xùn)練的 word2vec 模型會(huì)給訓(xùn)練帶來(lái)好處,具體來(lái)說(shuō):(1)間接引入外部訓(xùn)練數(shù)據(jù),防止過(guò)擬合;(2)減少需要訓(xùn)練的參數(shù)個(gè)數(shù),提高訓(xùn)練效率
LSTM 需要訓(xùn)練的參數(shù)個(gè)數(shù)遠(yuǎn)小于 CNN,但訓(xùn)練時(shí)間大于 CNN。CNN 在分類問(wèn)題的表現(xiàn)上一直很好,無(wú)論是圖像還是文本;而想讓 LSTM 優(yōu)勢(shì)得到發(fā)揮,首先讓訓(xùn)練數(shù)據(jù)量得到保證
將單詞在 word2vec 中的詞向量加和求平均獲得整個(gè)句子的語(yǔ)義向量的方法看似 naive 有時(shí)真挺奏效,當(dāng)然僅限于短句子,長(zhǎng)度 100 以內(nèi)應(yīng)該問(wèn)題不大
機(jī)器學(xué)習(xí)方法萬(wàn)千,具體選擇用什么樣的方法還是要取決于數(shù)據(jù)集的規(guī)模以及問(wèn)題本身的復(fù)雜度,對(duì)于復(fù)雜程度一般的問(wèn)題,看似簡(jiǎn)單的方法有可能是墜吼地
干貨上完了,下面是實(shí)驗(yàn)的具體流程
0 數(shù)據(jù)預(yù)處理
將下載的原始數(shù)據(jù)進(jìn)行轉(zhuǎn)碼,然后給文本標(biāo)類別的標(biāo)簽,然后制作訓(xùn)練與測(cè)試數(shù)據(jù),然后控制文本長(zhǎng)度,分詞,去標(biāo)點(diǎn)符號(hào)
哎,坑多,費(fèi)事,比較麻煩
首先,搜狗實(shí)驗(yàn)室提供的數(shù)據(jù)下載下來(lái)是 xml 格式,并且是 GBK (萬(wàn)惡之源)編碼,需要轉(zhuǎn)成 UTF8,并整理成 json 方便處理。原始數(shù)據(jù)長(zhǎng)這個(gè)樣:

這么大的數(shù)據(jù)量,怎么轉(zhuǎn)碼呢?先嘗試?yán)?python 先讀入數(shù)據(jù)然后轉(zhuǎn)碼再保存,可傲嬌 python 并不喜歡執(zhí)行這種語(yǔ)句。。。再嘗試?yán)?vim 的 :set fileencoding=utf-8,亂碼從███變成錕斤拷。。。
經(jīng)過(guò)幾次嘗試,菜雞的我只能通過(guò)文本編輯器打開(kāi),然后利用文本編輯器轉(zhuǎn)換編碼。這樣問(wèn)題來(lái)了,文件大小1.6G,記事本就不提了,Notepad 和 Editplus 也都紛紛陣亡。。。
還好最后發(fā)現(xiàn)了 UltraEdit,不但可以打開(kāi),速度簡(jiǎn)直飛起來(lái),轉(zhuǎn)碼后再整理成的 json 長(zhǎng)這個(gè)樣子:
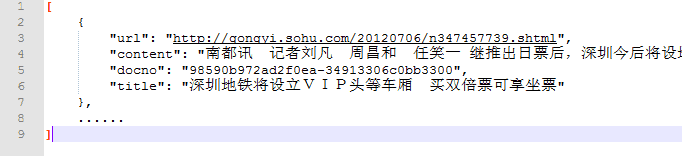
UltraEdit 就是好就是秒就是呱呱叫
搜狗新聞的數(shù)據(jù)沒(méi)有直接提供分類,而是得通過(guò)新聞來(lái)源網(wǎng)址的 url 來(lái)查其對(duì)應(yīng)得分類,比如 http://gongyi.sohu.com 的 url 前綴對(duì)應(yīng)的新聞?lì)愋途褪恰肮骖悺薄?duì)著他提供的對(duì)照表查,1410000+的總數(shù)據(jù),成功標(biāo)出來(lái)的有510000+,標(biāo)不出來(lái)的新聞基本都來(lái)自 http://roll.sohu.com,這是搜狐的滾動(dòng)新聞,亂七八糟大雜燴,難以確定是什么類
對(duì)成功標(biāo)出來(lái)的15個(gè)類的新聞,統(tǒng)計(jì)一下類別的分布,結(jié)果如下:
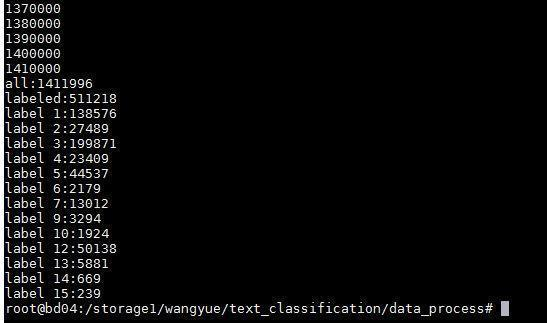
分布比較不均,第 14 類和第 15 類的新聞很少,另外第 8 類和第 11 類一個(gè)新聞也沒(méi)有
所以最后選了剩下的11個(gè)類,每個(gè)類抽2000個(gè)新聞,按4:1分成訓(xùn)練與測(cè)試,如圖
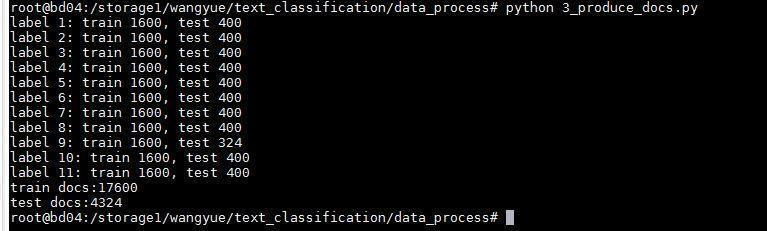
11個(gè)類分別是
對(duì)這些新聞的長(zhǎng)度進(jìn)行統(tǒng)計(jì)結(jié)果如下:
橫軸是新聞的長(zhǎng)度,縱軸是擁有此長(zhǎng)度的新聞數(shù)量。在長(zhǎng)度為500字和1600字時(shí)突然兩個(gè)峰,猜測(cè)是搜狐新聞的一些長(zhǎng)度限制???
長(zhǎng)度0-100的放大觀察,分布還可以,說(shuō)明如果基于這套數(shù)據(jù)做短文本分類,需要對(duì)原始文本進(jìn)行固定長(zhǎng)度的截取,長(zhǎng)度 100 可能是個(gè)不錯(cuò)的選擇
上一步選出來(lái)的訓(xùn)練新聞長(zhǎng)這樣,因?yàn)榭紤]到新聞標(biāo)題的意義重大,這里就將新聞標(biāo)題和新聞內(nèi)容接到一起,用空格隔開(kāi),然后截取每條新聞的前 100 個(gè)字

一行是一條新聞,訓(xùn)練數(shù)據(jù)17600行,測(cè)試數(shù)據(jù)4324行。然后用jieba分詞,分詞后利用詞性標(biāo)注結(jié)果,把詞性為‘x’(字符串)的去掉,就完成了去標(biāo)點(diǎn)符號(hào)

jieba真是好真是秒真是呱呱叫
最后得到以下結(jié)果文件:(1)新聞文本數(shù)據(jù),每行 1 條新聞,每條新聞?dòng)扇舾蓚€(gè)詞組成,詞之間以空格隔開(kāi),訓(xùn)練文本 17600 行,測(cè)試文本 4324 行;(2)新聞標(biāo)簽數(shù)據(jù),每行 1 個(gè)數(shù)字,對(duì)應(yīng)這條新聞所屬的類別編號(hào),訓(xùn)練標(biāo)簽 17600行,測(cè)試標(biāo)簽 4324 行
1 CNN
深度學(xué)習(xí)用的 keras 工具,操作簡(jiǎn)單易懂,模型上手飛快,居家旅行必備。keras 后端用的 Tensorflow,雖然用什么都一樣
不使用預(yù)訓(xùn)練 word2vec 模型的 CNN:
首先一些先設(shè)定一些會(huì)用到的參數(shù)
MAX_SEQUENCE_LENGTH=100#每條新聞最大長(zhǎng)度 EMBEDDING_DIM=200#詞向量空間維度 VALIDATION_SPLIT=0.16#驗(yàn)證集比例 TEST_SPLIT=0.2#測(cè)試集比例
第一步先把訓(xùn)練與測(cè)試數(shù)據(jù)放在一起提取特征,使用 keras 的 Tokenizer 來(lái)實(shí)現(xiàn),將新聞文檔處理成單詞索引序列,單詞與序號(hào)之間的對(duì)應(yīng)關(guān)系靠單詞的索引表 word_index 來(lái)記錄,這里從所有新聞中提取到 65604 個(gè)單詞,比如 [茍,國(guó)家,生死] 就變成了 [1024, 666, 233] ;然后將長(zhǎng)度不足 100 的新聞?dòng)?0 填充(在前端填充),用 keras 的 pad_sequences 實(shí)現(xiàn);最后將標(biāo)簽處理成 one-hot 向量,比如 6 變成了 [0,0,0,0,0,0,1,0,0,0,0,0,0],用 keras 的 to_categorical 實(shí)現(xiàn)
fromkeras.preprocessing.textimportTokenizer fromkeras.preprocessing.sequenceimportpad_sequences fromkeras.utilsimportto_categorical importnumpyasnp tokenizer=Tokenizer() tokenizer.fit_on_texts(all_texts) sequences=tokenizer.texts_to_sequences(all_texts) word_index=tokenizer.word_index print('Found%suniquetokens.'%len(word_index)) data=pad_sequences(sequences,maxlen=MAX_SEQUENCE_LENGTH) labels=to_categorical(np.asarray(all_labels)) print('Shapeofdatatensor:',data.shape) print('Shapeoflabeltensor:',labels.shape)
再將處理后的新聞數(shù)據(jù)按 6.4:1.6:2 分為訓(xùn)練集,驗(yàn)證集,測(cè)試集
p1=int(len(data)*(1-VALIDATION_SPLIT-TEST_SPLIT)) p2=int(len(data)*(1-TEST_SPLIT)) x_train=data[:p1] y_train=labels[:p1] x_val=data[p1:p2] y_val=labels[p1:p2] x_test=data[p2:] y_test=labels[p2:] print'traindocs:'+str(len(x_train)) print'valdocs:'+str(len(x_val)) print'testdocs:'+str(len(x_test))
然后就是搭建模型,首先是一個(gè)將文本處理成向量的 embedding 層,這樣每個(gè)新聞文檔被處理成一個(gè) 100 x 200 的二維向量,100 是每條新聞的固定長(zhǎng)度,每一行的長(zhǎng)度為 200 的行向量代表這個(gè)單詞在空間中的詞向量。下面通過(guò) 1 層卷積層與池化層來(lái)縮小向量長(zhǎng)度,再加一層 Flatten 層將 2 維向量壓縮到 1 維,最后通過(guò)兩層 Dense(全連接層)將向量長(zhǎng)度收縮到 12 上,對(duì)應(yīng)新聞分類的 12 個(gè)類(其實(shí)只有 11 個(gè)類,標(biāo)簽 0 沒(méi)有用到)。搭完收工,最后,訓(xùn)練模型,測(cè)試模型,一鼓作氣,攻下高地。
fromkeras.layersimportDense,Input,Flatten,Dropout fromkeras.layersimportConv1D,MaxPooling1D,Embedding fromkeras.modelsimportSequential model=Sequential() model.add(Embedding(len(word_index)+1,EMBEDDING_DIM,input_length=MAX_SEQUENCE_LENGTH)) model.add(Dropout(0.2)) model.add(Conv1D(250,3,padding='valid',activation='relu',strides=1)) model.add(MaxPooling1D(3)) model.add(Flatten()) model.add(Dense(EMBEDDING_DIM,activation='relu')) model.add(Dense(labels.shape[1],activation='softmax')) model.summary()
模型長(zhǎng)這個(gè)樣子
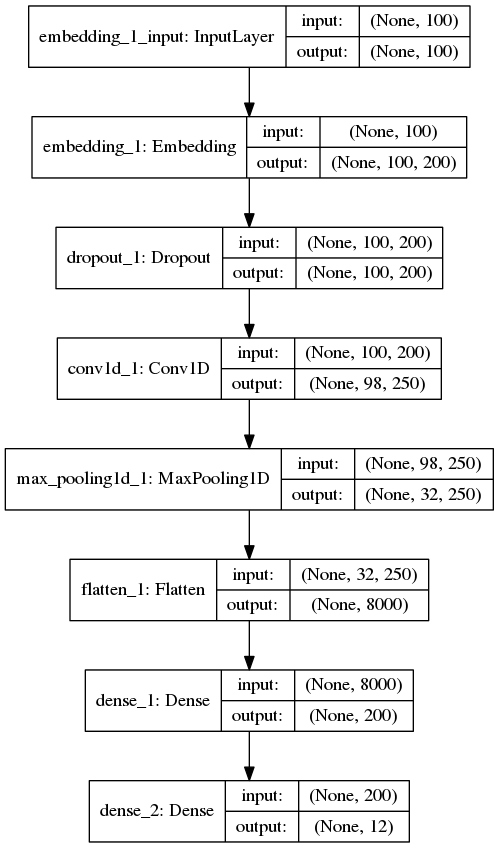
問(wèn):這里只使用了 1 層卷積層,為什么不多加幾層?
答:新聞長(zhǎng)度只有100個(gè)單詞,即特征只有100維,1 層卷積加池化后特征已經(jīng)縮減為 32 維,再加卷積可能就卷沒(méi)了。2 層 3 層也做過(guò),效果都不好
問(wèn):為什么只訓(xùn)練 2 輪
答:?jiǎn)栴}比較簡(jiǎn)單,1 輪訓(xùn)練已經(jīng)收斂,實(shí)驗(yàn)表明第 2 輪訓(xùn)練基本沒(méi)什么提升
問(wèn):為什么卷積核為什么選擇 250 個(gè)?
答:因?yàn)殚_(kāi)心
實(shí)驗(yàn)結(jié)果如下
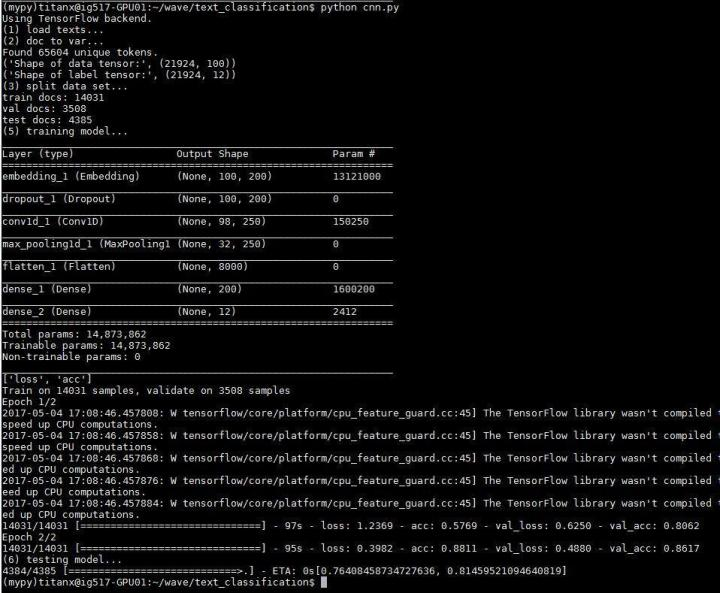
準(zhǔn)確度 0.81459521
擁有11個(gè)分類的問(wèn)題達(dá)到這個(gè)準(zhǔn)確度,應(yīng)該也不錯(cuò)(易滿足)。并且搜狗給的數(shù)據(jù)本來(lái)也不是很好(甩鍋)。可以看到在訓(xùn)練集上的準(zhǔn)確度達(dá)到了 0.88,但是測(cè)試集上的準(zhǔn)確度只有 0.81,說(shuō)明還是有些過(guò)擬合。另外,整個(gè)模型需要訓(xùn)練的參數(shù)接近 1500 萬(wàn),其中 1300 萬(wàn)都是 embedding 層的參數(shù),說(shuō)明如果利用 word2vec 模型替換 embedding 層,解放這 1300 萬(wàn)參數(shù),肯定會(huì)讓訓(xùn)練效率得到提高
基于預(yù)訓(xùn)練的 word2vec 的 CNN :
keras示例程序 pretrained_word_embeddings.py 代碼地址https://github.com/fchollet/keras/blob/master/examples/pretrained_word_embeddings.py
中文講解地址(在Keras模型中使用預(yù)訓(xùn)練的詞向量)http://keras-cn.readthedocs.io/en/latest/blog/word_embedding/
既然提到了 word2vec 可能會(huì)提高訓(xùn)練效率,那就用實(shí)驗(yàn)驗(yàn)證一下。(重點(diǎn))(重點(diǎn))(重點(diǎn))正常的深度學(xué)習(xí)訓(xùn)練,比如上面的 CNN 模型,第一層(除去 Input 層)是一個(gè)將文本處理成向量的 embedding 層。這里為了使用預(yù)訓(xùn)練的 word2vec 來(lái)代替這個(gè) embedding 層,就需要將 embedding 層的 1312 萬(wàn)個(gè)參數(shù)用 word2vec 模型中的詞向量替換。替換后的 embedding 矩陣形狀為 65604 x 200,65604 行代表 65604 個(gè)單詞,每一行的這長(zhǎng)度 200 的行向量對(duì)應(yīng)這個(gè)詞在 word2vec 空間中的 200 維向量。最后,設(shè)定 embedding 層的參數(shù)固定,不參加訓(xùn)練,這樣就把預(yù)訓(xùn)練的 word2vec 嵌入到了深度學(xué)習(xí)的模型之中
VECTOR_DIR='wiki.zh.vector.bin'#詞向量模型文件 fromkeras.utilsimportplot_model fromkeras.layersimportEmbedding importgensim w2v_model=gensim.models.KeyedVectors.load_word2vec_format(VECTOR_DIR,binary=True) embedding_matrix=np.zeros((len(word_index)+1,EMBEDDING_DIM)) forword,iinword_index.items(): ifunicode(word)inw2v_model: embedding_matrix[i]=np.asarray(w2v_model[unicode(word)], dtype='float32') embedding_layer=Embedding(len(word_index)+1, EMBEDDING_DIM, weights=[embedding_matrix], input_length=MAX_SEQUENCE_LENGTH, trainable=False)
模型搭建與剛才類似,就是用嵌入了 word2vec 的 embedding_layer 替換原來(lái)的 embedding 層
fromkeras.layersimportDense,Input,Flatten,Dropout fromkeras.layersimportConv1D,MaxPooling1D,Embedding fromkeras.modelsimportSequential model=Sequential() model.add(embedding_layer) model.add(Dropout(0.2)) model.add(Conv1D(250,3,padding='valid',activation='relu',strides=1)) model.add(MaxPooling1D(3)) model.add(Flatten()) model.add(Dense(EMBEDDING_DIM,activation='relu')) model.add(Dense(labels.shape[1],activation='softmax')) model.summary() #plot_model(model,to_file='model.png',show_shapes=True) model.compile(loss='categorical_crossentropy', optimizer='rmsprop', metrics=['acc']) model.fit(x_train,y_train,validation_data=(x_val,y_val),epochs=2,batch_size=128) model.save('word_vector_cnn.h5') printmodel.evaluate(x_test,y_test)
模型長(zhǎng)相跟之前一致,實(shí)驗(yàn)輸出與測(cè)試結(jié)果如下
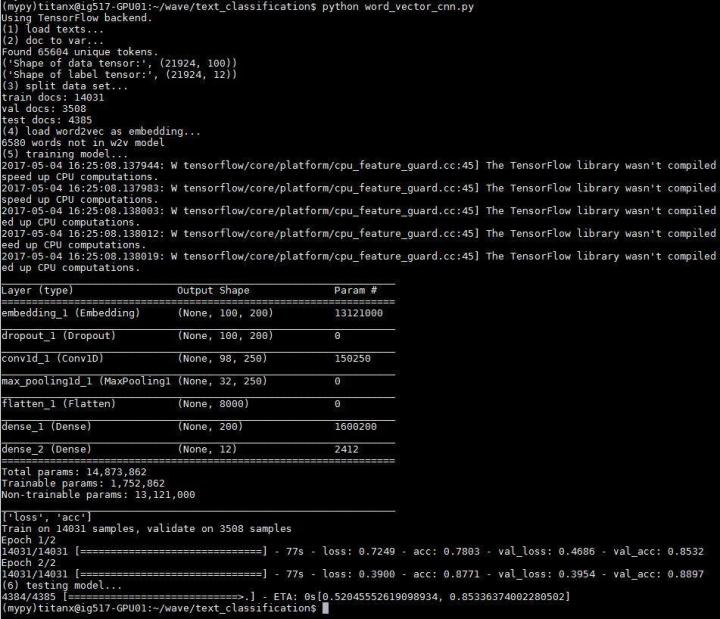
準(zhǔn)確度 0.85336374
相比不使用 word2vec 的 cnn,過(guò)擬合的現(xiàn)象明顯減輕,使準(zhǔn)確度得到了提高。并且需要訓(xùn)練的參數(shù)大大減少了,使訓(xùn)練時(shí)間平均每輪減少 20s 左右
2 LSTM
終于到了自然語(yǔ)言處理界的大哥 LSTM 登場(chǎng),還有點(diǎn)小期待
fromkeras.layersimportDense,Input,Flatten,Dropout fromkeras.layersimportLSTM,Embedding fromkeras.modelsimportSequential model=Sequential() model.add(Embedding(len(word_index)+1,EMBEDDING_DIM, input_length=MAX_SEQUENCE_LENGTH)) model.add(LSTM(200,dropout=0.2,recurrent_dropout=0.2)) model.add(Dropout(0.2)) model.add(Dense(labels.shape[1],activation='softmax')) model.summary()
模型長(zhǎng)這樣
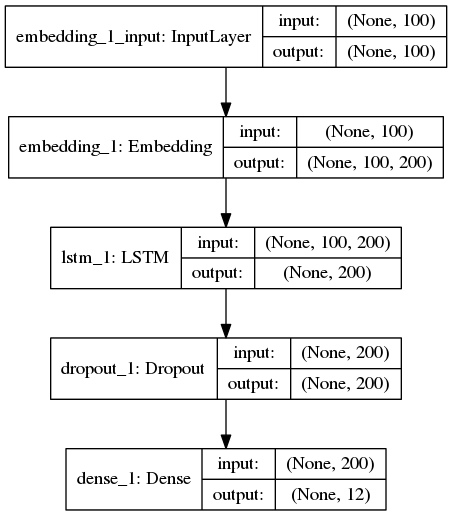
大哥開(kāi)動(dòng)!
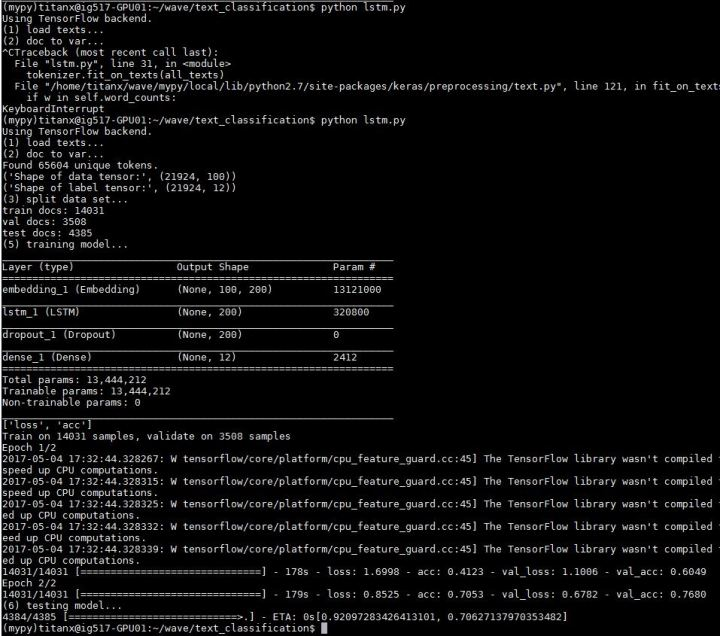
準(zhǔn)確度 0.70627138
并沒(méi)有期待中那么美好。。。原因是這點(diǎn)小數(shù)據(jù)量,并沒(méi)有讓 LSTM 發(fā)揮出它的優(yōu)勢(shì)。并不能給大哥一個(gè)奔馳的草原。。。并不能讓大哥飛起來(lái)。。。另外使用 LSTM 需要訓(xùn)練的參數(shù)要比使用 CNN 少很多,但是訓(xùn)練時(shí)間是 CNN 的 2 倍。大哥表示不但飛不動(dòng),還飛的很累。。。
基于預(yù)訓(xùn)練的 word2vec 模型:
流程跟上面使用 word2vec 的 CNN 的基本一致,同樣也是用嵌入了 word2vec 的 embedding_layer 替換原始的 embedding 層
fromkeras.layersimportDense,Input,Flatten,Dropout fromkeras.layersimportLSTM,Embedding fromkeras.modelsimportSequential model=Sequential() model.add(embedding_layer) model.add(LSTM(200,dropout=0.2,recurrent_dropout=0.2)) model.add(Dropout(0.2)) model.add(Dense(labels.shape[1],activation='softmax')) model.summary()
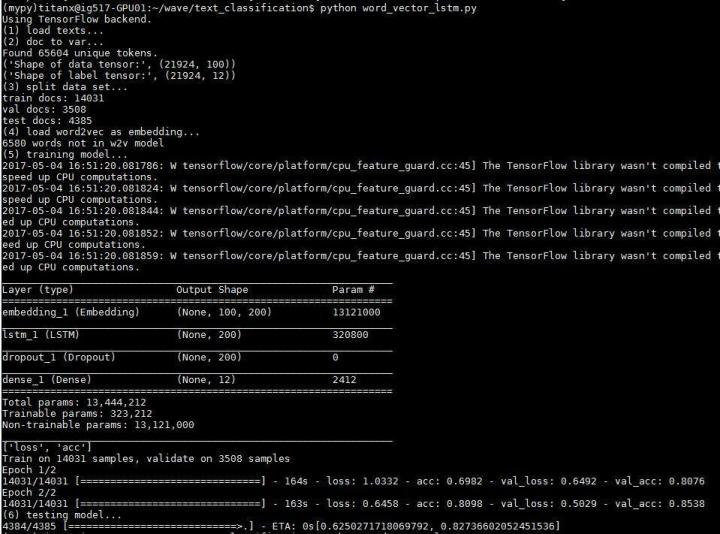
準(zhǔn)確度 0.82736602
效果好了不少,依然存在過(guò)擬合現(xiàn)象,再一次說(shuō)明了數(shù)據(jù)量對(duì) LSTM 的重要性,使用預(yù)訓(xùn)練的 word2vec 模型等于間接增加了訓(xùn)練語(yǔ)料,所以在這次實(shí)驗(yàn)中崩壞的不是很嚴(yán)重
LP(多層感知機(jī))
參考資料
keras 示例程序:reuters_mlp.py
代碼地址:https://github.com/fchollet/keras/blob/master/examples/reuters_mlp.py
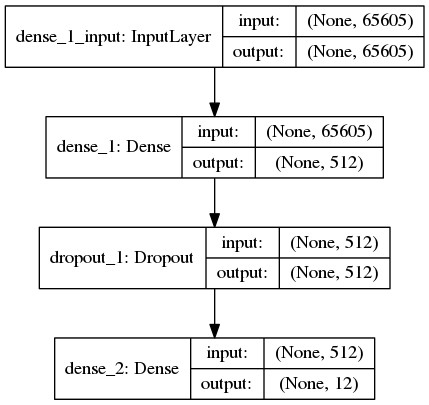
MLP 是一個(gè)結(jié)構(gòu)上很簡(jiǎn)單很 naive 的神經(jīng)網(wǎng)絡(luò)。數(shù)據(jù)的處理流程也跟上面兩個(gè)實(shí)驗(yàn)差不多,不過(guò)不再將每條新聞處理成 100 x 200 的 2 維向量,而是成為長(zhǎng)度 65604 的 1 維向量。65604 代表數(shù)據(jù)集中所有出現(xiàn)的 65604 個(gè)單詞,數(shù)據(jù)的值用 tf-idf 值填充,整個(gè)文檔集成為一個(gè)用 17600 x 65604 個(gè) tf-idf 值填充的矩陣,第 i 行 j 列的值表征了第 j 個(gè)單詞在第 i 個(gè)文檔中的的 tf-idf值(當(dāng)然這里也可以不用 tf-idf 值,而只是使用 0/1 值填充, 0/1 代表第 j 個(gè)單詞在第 i 個(gè)文檔中是否出現(xiàn),但是實(shí)驗(yàn)顯示用 tf-idf 的效果更好)
tokenizer=Tokenizer() tokenizer.fit_on_texts(all_texts) sequences=tokenizer.texts_to_sequences(all_texts) word_index=tokenizer.word_index print('Found%suniquetokens.'%len(word_index)) data=tokenizer.sequences_to_matrix(sequences,mode='tfidf') labels=to_categorical(np.asarray(all_labels))
模型很簡(jiǎn)單,僅有兩個(gè)全連接層組成,將長(zhǎng)度 65604 的 1 維向量經(jīng)過(guò) 2 次壓縮成為長(zhǎng)度 12 的 1 維向量
fromkeras.layersimportDense,Dropout fromkeras.modelsimportSequential model=Sequential() model.add(Dense(512,input_shape=(len(word_index)+1,),activation='relu')) model.add(Dropout(0.2)) model.add(Dense(labels.shape[1],activation='softmax')) model.summary()
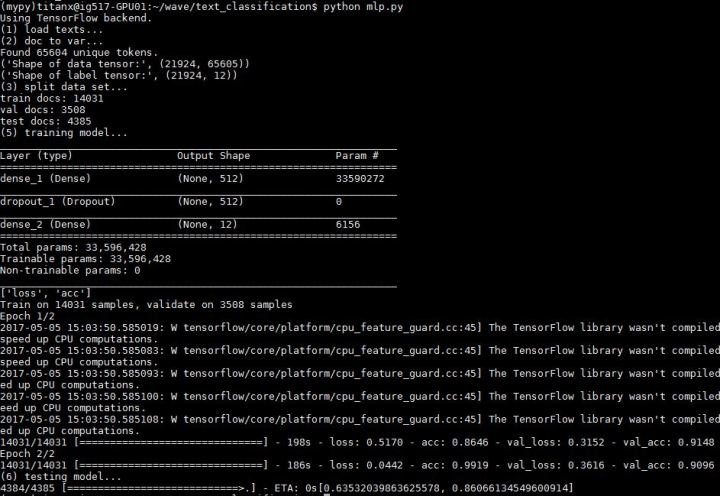
準(zhǔn)確度 0.86066135
相比 CNN 與 LSTM 的最好成績(jī),雖然簡(jiǎn)單,但是依然 NB
只是不能像 CNN 與 LSTM 那樣借助預(yù)訓(xùn)練 word2vec 的幫助,加上數(shù)據(jù)量不大,所以稍微有些過(guò)擬合,不過(guò)結(jié)果依舊很不錯(cuò)。沒(méi)有復(fù)雜的 embedding,清新脫俗的傳統(tǒng)感知機(jī)模型在這種小數(shù)據(jù)集的簡(jiǎn)單問(wèn)題上表現(xiàn)非常好(雖然訓(xùn)練參數(shù)已經(jīng)達(dá)到了 3300 萬(wàn)個(gè),單輪耗時(shí)也將近 200s 了)
4 樸素貝葉斯
非深度學(xué)習(xí)方法這里使用 sklearn 來(lái)實(shí)踐
首先登場(chǎng)的是樸素貝葉斯。數(shù)據(jù)處理的過(guò)程跟上述的 MLP 是一致的,也是將整個(gè)文檔集用 tf-idf 值填充,讓整個(gè)文檔集成為一個(gè) 17600 x 65604 的 tf-idf 矩陣。這里需要使用 sklearn 的 CountVectorizer 與 TfidfTransformer 函數(shù)實(shí)現(xiàn)。代碼如下
fromsklearn.feature_extraction.textimportCountVectorizer,TfidfTransformer count_v0=CountVectorizer(); counts_all=count_v0.fit_transform(all_text); count_v1=CountVectorizer(vocabulary=count_v0.vocabulary_); counts_train=count_v1.fit_transform(train_texts); print"theshapeoftrainis"+repr(counts_train.shape) count_v2=CountVectorizer(vocabulary=count_v0.vocabulary_); counts_test=count_v2.fit_transform(test_texts); print"theshapeoftestis"+repr(counts_test.shape) tfidftransformer=TfidfTransformer(); train_data=tfidftransformer.fit(counts_train).transform(counts_train); test_data=tfidftransformer.fit(counts_test).transform(counts_test);
這里有一個(gè)需要注意的地方,由于訓(xùn)練集和測(cè)試集分開(kāi)提取特征會(huì)導(dǎo)致兩者的特征空間不同,比如訓(xùn)練集里 “茍” 這個(gè)單詞的序號(hào)是 1024,但是在測(cè)試集里序號(hào)就不同了,或者根本就不存在在測(cè)試集里。所以這里先用所有文檔共同提取特征(counts_v0),然后利用得到的詞典(counts_v0.vocabulary_)再分別給訓(xùn)練集和測(cè)試集提取特征。然后開(kāi)始訓(xùn)練與測(cè)試
fromsklearn.naive_bayesimportMultinomialNB fromsklearnimportmetrics clf=MultinomialNB(alpha=0.01) clf.fit(x_train,y_train); preds=clf.predict(x_test); num=0 preds=preds.tolist() fori,predinenumerate(preds): ifint(pred)==int(y_test[i]): num+=1 print'precision_score:'+str(float(num)/len(preds))
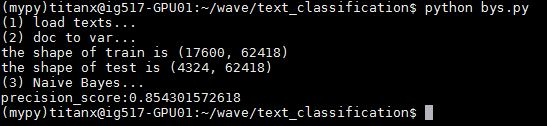
準(zhǔn)確度 0.85430157
這只是一個(gè)簡(jiǎn)單的樸素貝葉斯方法,準(zhǔn)確度高到驚人,果然最簡(jiǎn)單的有時(shí)候就是最有效的
5 KNN
跟上面基本一致,只是將 MultinomialNB 函數(shù)變成 KNeighborsClassifier 函數(shù),直接上結(jié)果
fromsklearn.neighborsimportKNeighborsClassifier forxinrange(1,15): knnclf=KNeighborsClassifier(n_neighbors=x) knnclf.fit(x_train,y_train) preds=knnclf.predict(x_test); num=0 preds=preds.tolist() fori,predinenumerate(preds): ifint(pred)==int(y_test[i]): num+=1 print'K='+str(x)+',precision_score:'+str(float(num)/len(preds))
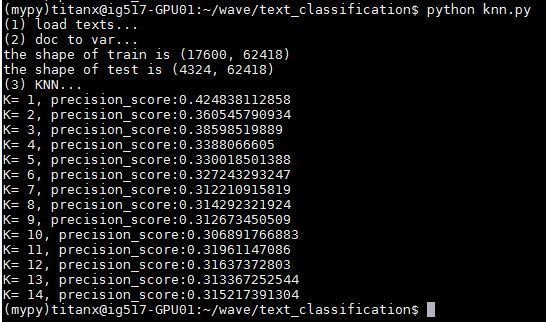
K=11時(shí),準(zhǔn)確度 0.31961147,非常低,說(shuō)明 KNN 方法不太適合做此類問(wèn)題
6 SVM
這里 svm 的 kernel 選用了線性核,其他的比如多項(xiàng)式核和高斯核也都試過(guò),效果極差,直接上結(jié)果
fromsklearn.svmimportSVC svclf=SVC(kernel='linear') svclf.fit(x_train,y_train) preds=svclf.predict(x_test); num=0 preds=preds.tolist() fori,predinenumerate(preds): ifint(pred)==int(y_test[i]): num+=1 print'precision_score:'+str(float(num)/len(preds))
準(zhǔn)確度 0.84435708,還是不錯(cuò)的,超過(guò) LSTM ,不及 CNN 與 MLP
7 SVM + word2vec 與 doc2vec
這兩個(gè)實(shí)驗(yàn)是后期新加入的,畫風(fēng)比較清奇,是騾是馬溜一圈,就決定拿過(guò)來(lái)做個(gè)實(shí)驗(yàn)一起比較一下
svm + word2vec:
這個(gè)實(shí)驗(yàn)的主要思想是這樣:原本每條新聞?dòng)扇舾蓚€(gè)詞組成,每個(gè)詞在 word2vec 中都有由一個(gè)長(zhǎng)度 200 的詞向量表示,且這個(gè)詞向量的位置是與詞的語(yǔ)義相關(guān)聯(lián)的。那么對(duì)于每一條新聞,將這條新聞中所有的詞的詞向量加和取平均,既能保留句子中所有單詞的語(yǔ)義,又能生成一個(gè)蘊(yùn)含著這句話的綜合語(yǔ)義的“句向量”,再基于這個(gè)長(zhǎng)度 200 的句向量使用 svm 分類。這個(gè)思想看起來(lái)很 naive,但是又說(shuō)不出什么不合理的地方。嘗試一下,代碼與結(jié)果如下:
importgensim importnumpyasnp w2v_model=gensim.models.KeyedVectors.load_word2vec_format(VECTOR_DIR,binary=True) x_train=[] x_test=[] fortrain_docintrain_docs: words=train_doc.split('') vector=np.zeros(EMBEDDING_DIM) word_num=0 forwordinwords: ifunicode(word)inw2v_model: vector+=w2v_model[unicode(word)] word_num+=1 ifword_num>0: vector=vector/word_num x_train.append(vector) fortest_docintest_docs: words=test_doc.split('') vector=np.zeros(EMBEDDING_DIM) word_num=0 forwordinwords: ifunicode(word)inw2v_model: vector+=w2v_model[unicode(word)] word_num+=1 ifword_num>0: vector=vector/word_num x_test.append(vector)
準(zhǔn)確度 0.85175763,驚了,這種看似很 naive 的方法竟然取得了非常好的效果。相比于之前所有包括 CNN、LSTM、MLP、SVM 等方法,這種方法有很強(qiáng)的優(yōu)勢(shì)。它不需要特征提取的過(guò)程,也不需固定新聞的長(zhǎng)度,一個(gè)模型訓(xùn)練好,跨著數(shù)據(jù)集都能跑。但是也有其缺陷一面,比如忽略詞語(yǔ)的前后關(guān)系,并且當(dāng)句子長(zhǎng)度較長(zhǎng)時(shí),求和取平均已經(jīng)無(wú)法準(zhǔn)確保留語(yǔ)義信息了。但是在短文本分類上的表現(xiàn)還是很亮
svm + doc2vec:
上面 svm + word2vec 的實(shí)驗(yàn)提到當(dāng)句子很長(zhǎng)時(shí),簡(jiǎn)單求和取平均已經(jīng)不能保證原來(lái)的語(yǔ)義信息了。偶然發(fā)現(xiàn)了 gensim 提供了一個(gè) doc2vec 的模型,直接為文檔量身訓(xùn)練“句向量”,神奇。具體原理不講了(也不是很懂),直接給出使用方法
importgensim sentences=gensim.models.doc2vec.TaggedLineDocument('all_contents.txt') model=gensim.models.Doc2Vec(sentences,size=200,window=5,min_count=5) model.save('doc2vec.model') print'numofdocs:'+str(len(model.docvecs))
all_contents.txt 里是包括訓(xùn)練文檔與測(cè)試文檔在內(nèi)的所有數(shù)據(jù),同樣每行 1 條新聞,由若干個(gè)詞組成,詞之間用空格隔開(kāi),先使用 gensim 的 TaggedLineDocument 函數(shù)預(yù)處理下,然后直接使用 Doc2Vec 函數(shù)開(kāi)始訓(xùn)練,訓(xùn)練過(guò)程很快(可能因?yàn)閿?shù)據(jù)少)。然后這所有 21924 篇新聞就變成了 21924 個(gè)長(zhǎng)度 200 的向量,取出前 17600 個(gè)給 SVM 做分類訓(xùn)練,后 4324 個(gè)測(cè)試,代碼和結(jié)果如下:
importgensim model=gensim.models.Doc2Vec.load('doc2vec.model') x_train=[] x_test=[] y_train=train_labels y_test=test_labels foridx,docvecinenumerate(model.docvecs): ifidx
準(zhǔn)確度 0.48126734,慘不忍睹。原因可能就是文檔太短,每個(gè)文檔只有不超過(guò) 100 個(gè)詞,導(dǎo)致對(duì)“句向量”的學(xué)習(xí)不準(zhǔn)確,word2vec 模型訓(xùn)練需要 1G 以上的數(shù)據(jù)量,這里訓(xùn)練 doc2vec 模型20000個(gè)文檔卻只有 5M 的大小,所以崩壞
另外!這里對(duì) doc2vec 的應(yīng)用場(chǎng)景有一些疑問(wèn),如果我新加入一條新聞想要分類,那么我必須先要把這個(gè)新聞加到文檔集里,然后重新對(duì)文檔集進(jìn)行 doc2vec 的訓(xùn)練,得到這個(gè)新新聞的文檔向量,然后由于文檔向量模型變了, svm 分類模型應(yīng)該也需要重新訓(xùn)練了。所以需要自底向上把所有模型打破重建才能讓為新文檔分類?那實(shí)用性很差啊。也可能我理解有誤,希望是這樣
總結(jié)
總結(jié)放在開(kāi)頭了
打完收工
責(zé)任編輯:xj
原文標(biāo)題:新聞上的文本分類:機(jī)器學(xué)習(xí)大亂斗
文章出處:【微信公眾號(hào):深度學(xué)習(xí)自然語(yǔ)言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
-
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8406瀏覽量
132565 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5500瀏覽量
121113 -
cnn
+關(guān)注
關(guān)注
3文章
352瀏覽量
22203
原文標(biāo)題:新聞上的文本分類:機(jī)器學(xué)習(xí)大亂斗
文章出處:【微信號(hào):zenRRan,微信公眾號(hào):深度學(xué)習(xí)自然語(yǔ)言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
如何使用自然語(yǔ)言處理分析文本數(shù)據(jù)
什么是機(jī)器學(xué)習(xí)?通過(guò)機(jī)器學(xué)習(xí)方法能解決哪些問(wèn)題?

使用LLM進(jìn)行自然語(yǔ)言處理的優(yōu)缺點(diǎn)
【《時(shí)間序列與機(jī)器學(xué)習(xí)》閱讀體驗(yàn)】+ 了解時(shí)間序列
【《大語(yǔ)言模型應(yīng)用指南》閱讀體驗(yàn)】+ 基礎(chǔ)篇
利用TensorFlow實(shí)現(xiàn)基于深度神經(jīng)網(wǎng)絡(luò)的文本分類模型
深度學(xué)習(xí)中的時(shí)間序列分類方法
深度學(xué)習(xí)中的無(wú)監(jiān)督學(xué)習(xí)方法綜述
自然語(yǔ)言處理過(guò)程的五個(gè)層次
卷積神經(jīng)網(wǎng)絡(luò)在文本分類領(lǐng)域的應(yīng)用
基于神經(jīng)網(wǎng)絡(luò)的呼吸音分類算法
一種利用光電容積描記(PPG)信號(hào)和深度學(xué)習(xí)模型對(duì)高血壓分類的新方法
機(jī)器學(xué)習(xí)8大調(diào)參技巧





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論