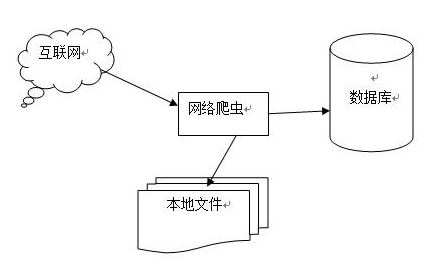
") 什么是爬蟲看了就知道
什么是爬蟲看了就知道
因?yàn)榻柚鶫TTP協(xié)議,我可以通過全球全部的website和瀏覽器獲取我想要的數(shù)據(jù)。而我要加裝自己是一個(gè)瀏覽器,向server發(fā)送HTTP請(qǐng)求,進(jìn)而請(qǐng)求到網(wǎng)頁文件。之后按照HTML的格式規(guī)范解析其中的圖片、鏈接、表單,獲得我感興趣的內(nèi)容。

得到鏈接標(biāo)簽之后,我會(huì)進(jìn)一步爬取鏈接背后的內(nèi)容,這樣往復(fù),用不了多長(zhǎng)時(shí)間,我就能爬完這個(gè)站點(diǎn)中開放出來的所有內(nèi)容。
都說盜亦有道,當(dāng)然了,咱們爬蟲也有底線。在我們這一行混,必須遵守一個(gè)規(guī)矩——Robots協(xié)議。robots.txt的文件被放在網(wǎng)站的根目錄下充當(dāng)門神,里面寫上哪些目錄禁止訪問,爬蟲就會(huì)繞道而行,robots里面的內(nèi)容長(zhǎng)這樣:
User-agent: *
Disallow: /a/
Disallow: /b/
Disallow: /c/
如果你以為只有在程序員之間存在鄙視鏈,那你就錯(cuò)了,實(shí)際上他們的作品之間也存在鄙視鏈。
在這個(gè)星球上大佬級(jí)別的爬蟲當(dāng)屬谷歌搜索引擎,當(dāng)它想要爬取什么內(nèi)容的時(shí)候全球所有網(wǎng)站都巴不得被爬取。全球幾乎所有的網(wǎng)站都想被收錄到搜索引擎的花名冊(cè),進(jìn)而自己的網(wǎng)站可以被廣大網(wǎng)民搜索到。
當(dāng)然總有一些不法爬蟲,有一些爬蟲不遵守robots協(xié)議,隨意亂爬,一天天只知道爬美女圖片,把人家server都爬崩潰了。
但是像我這樣老實(shí)本分的爬蟲,日常就是爬取一些網(wǎng)站數(shù)據(jù),比如購物網(wǎng)站、點(diǎn)評(píng)網(wǎng)站。但這些網(wǎng)站也不待見我們。
為了爬到數(shù)據(jù),我們與網(wǎng)站之間一直在對(duì)峙。
再說說反爬蟲
那些網(wǎng)站不待見咱們這些爬蟲是因?yàn)樾奶圩约旱?a href="http://m.1cnz.cn/v/tag/1722/" target="_blank">網(wǎng)絡(luò)帶寬。
況且,我們不像搜索引擎爬蟲可以給他們的網(wǎng)站帶來流量,卻會(huì)占用他們的服務(wù)器一部分性能,占據(jù)他們珍貴的流量,那些可都是雪花銀,想想就揪心啊?
這些網(wǎng)站為了對(duì)付我們,采取了一個(gè)措施:在HTTP請(qǐng)求中的user-agent字段識(shí)別出這是爬蟲,就不會(huì)理睬我們了。user-agent是HTTP協(xié)議中用來代表客戶端名字的一個(gè)字段。在我剛?cè)胄袝r(shí)沒什么經(jīng)驗(yàn),就經(jīng)常被識(shí)破。

最后我只能換一身行頭,冒充瀏覽器,更有甚者圈子里有個(gè)兄弟冒充搜索引擎,我不會(huì)像他那么沒有底線。
沒多久這招就失靈了,那些網(wǎng)站升級(jí)了策略,通過我們的行為來識(shí)別是不是真的瀏覽器。我們畢竟是程序,那速度比人類點(diǎn)擊快多了,如果網(wǎng)站發(fā)現(xiàn)我們?cè)诙虝r(shí)間內(nèi)發(fā)起了居多請(qǐng)求,那就掐斷連接。被逼無奈,我只好降低爬取的頻率。
在江湖漂,難免要挨刀,有些網(wǎng)站會(huì)設(shè)下陷阱,靜靜等候我們這些爬蟲到來。他們?cè)诰W(wǎng)頁里面放上一些假的圖片作為誘餌,實(shí)際上可能是只有幾個(gè)像素、肉眼無法識(shí)別的假圖片,但是我們不知道啊,對(duì)我來說只要是《img》標(biāo)簽就是圖片。記得,有一次我一訪問就中計(jì)了,立刻被拉入黑名單!
上次栽了跟頭,但我沒有退縮,翻越高墻,出來后我要變得更強(qiáng)大。
聽說圈子里有些大佬用上了分布式技術(shù),組團(tuán)去爬,很多個(gè)IP地址,其中一個(gè)或者幾個(gè)封了也不用怕,我真是很羨慕。慕名而去,我學(xué)會(huì)了這項(xiàng)本領(lǐng),黑夜看到了我猙獰的笑。
前端后端
在我的爬蟲生涯中遇到過一些奇怪的網(wǎng)站,網(wǎng)頁中有數(shù)據(jù),但是訪問拿到的HTML中啥也沒有。
原來這種網(wǎng)站用了前后端分離開發(fā)的技術(shù)。數(shù)據(jù)是瀏覽器通過單獨(dú)的API接口拿到后再動(dòng)態(tài)加載出來,而不是渲染到網(wǎng)頁中,難怪我拿到的只是一個(gè)空殼子。

為了拿到數(shù)據(jù),我只好也學(xué)著去請(qǐng)求這些數(shù)據(jù)接口,不過因?yàn)檫@些網(wǎng)站都有API網(wǎng)關(guān),會(huì)檢查請(qǐng)求的Token或者Authorization之類的認(rèn)證字段,再加上我不知道他們的接口參數(shù)格式,導(dǎo)致我經(jīng)常拿不到數(shù)據(jù)。直到最近兩年,我拿到的網(wǎng)頁HTML越來越簡(jiǎn)單了,在瀏覽器中豐富多彩的頁面,一查看源代碼竟然只有簡(jiǎn)單幾行,真是見了鬼了!
有一天,一個(gè)前輩告訴我,現(xiàn)在流行單頁應(yīng)用SPA了,頁面全都是在前端動(dòng)態(tài)生成的,拿到的HTML根本沒有價(jià)值。這簡(jiǎn)直欺人太甚了!
沒辦法了,我決定變成一個(gè)真正的瀏覽器。
這個(gè)內(nèi)嵌的瀏覽器沒有界面,專門為我服務(wù),嵌入到我的程序中,讓他去真正地渲染網(wǎng)頁,渲染完成后我再去取數(shù)據(jù)。這是真正意義上模擬人類去訪問網(wǎng)站了,再也不用模擬繁瑣的數(shù)據(jù)接口訪問,也不用擔(dān)心單頁應(yīng)用,前端渲染就前端渲染,我再也不怕了!
難搞的驗(yàn)證碼
到后來,不知道是誰發(fā)明的,網(wǎng)站們紛紛用上了一種叫驗(yàn)證碼的技術(shù),給我們出了難題。開始的驗(yàn)證碼一般都是些簡(jiǎn)單的數(shù)字、英文字符做了些變形,就像這樣:
江湖上很快有大佬教我用文字識(shí)別技術(shù)OCR來自動(dòng)識(shí)別這種驗(yàn)證碼,我也折騰了一下,費(fèi)了老大勁終于可以識(shí)別出來,準(zhǔn)確率不敢說100%,99%還是有的。
沒多久這驗(yàn)證碼就變得越來越復(fù)雜,什么漢字識(shí)別,物體識(shí)別,滑動(dòng)解鎖,一個(gè)比一個(gè)難,像是簡(jiǎn)單的小游戲。你瞧瞧下面這些驗(yàn)證碼,這不是故意為難爬蟲嗎?
這些網(wǎng)站的反爬蟲技術(shù)越來越先進(jìn),我們能發(fā)揮的空間被一步步擠壓。內(nèi)憂外患不斷,不少爬蟲兄弟失業(yè)的失業(yè),轉(zhuǎn)行的轉(zhuǎn)行,爬蟲這碗飯,真是越來越不好吃了。據(jù)說有個(gè)愣頭青爬蟲強(qiáng)行爬取一家公司的網(wǎng)站,最后把人公司server給爬崩潰了,他還被抓了起來。
責(zé)任編輯人:CC
-
爬蟲
+關(guān)注
關(guān)注
0文章
82瀏覽量
6959
原文標(biāo)題:詳解什么是爬蟲?
文章出處:【微信號(hào):c-stm32,微信公眾號(hào):STM32嵌入式開發(fā)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
Python數(shù)據(jù)爬蟲學(xué)習(xí)內(nèi)容
爬蟲可以采集哪些數(shù)據(jù)
網(wǎng)絡(luò)爬蟲之關(guān)于爬蟲http代理的常見使用方式
網(wǎng)絡(luò)爬蟲nodejs爬蟲代理配置
Golang爬蟲語言接入代理?
如何運(yùn)行imdb爬蟲?
0基礎(chǔ)入門Python爬蟲實(shí)戰(zhàn)課
python網(wǎng)絡(luò)爬蟲概述
labview實(shí)現(xiàn)網(wǎng)絡(luò)爬蟲功能
python爬蟲入門教程之python爬蟲視頻教程分布式爬蟲打造搜索引擎
爬蟲是如何實(shí)現(xiàn)數(shù)據(jù)的獲取爬蟲程序如何實(shí)現(xiàn)





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論