 網絡IO套路分享
網絡IO套路分享
轉自:我是程序員小賤-L的存在
1 阻塞與非阻塞--開胃菜
阻塞
我們知道在調用某個函數的時候無非就是兩種情況,要么馬上返回,然后根據返回值進行接下來的業務處理。當在使用阻塞IO的時候,應用程序會被無情的掛起,等待內核完成操作,因為此時的內核可能將CPU時間切換到了其他需要的進程中,在我們的應用程序看來感覺被卡主(阻塞)了。
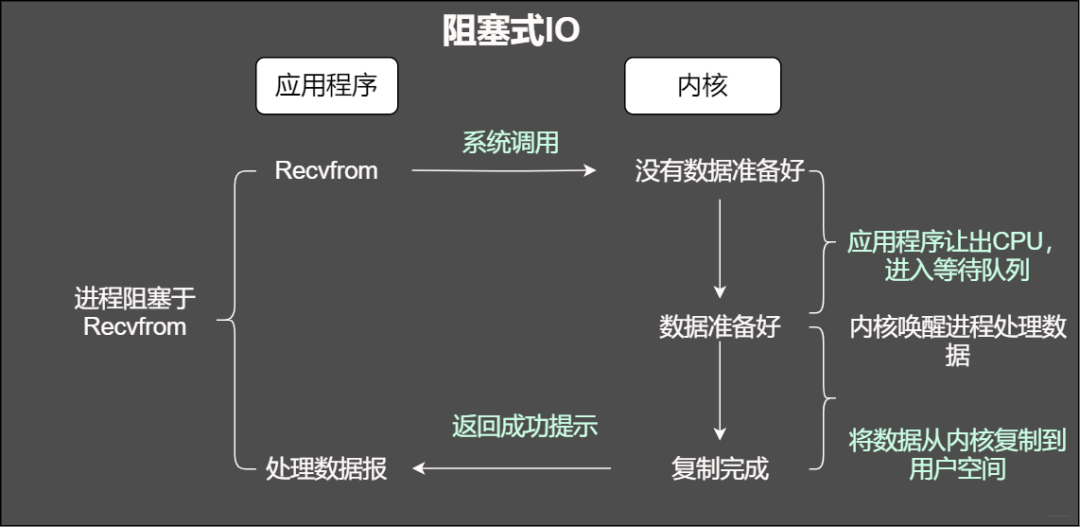
阻塞IO
傳統阻塞IO模型
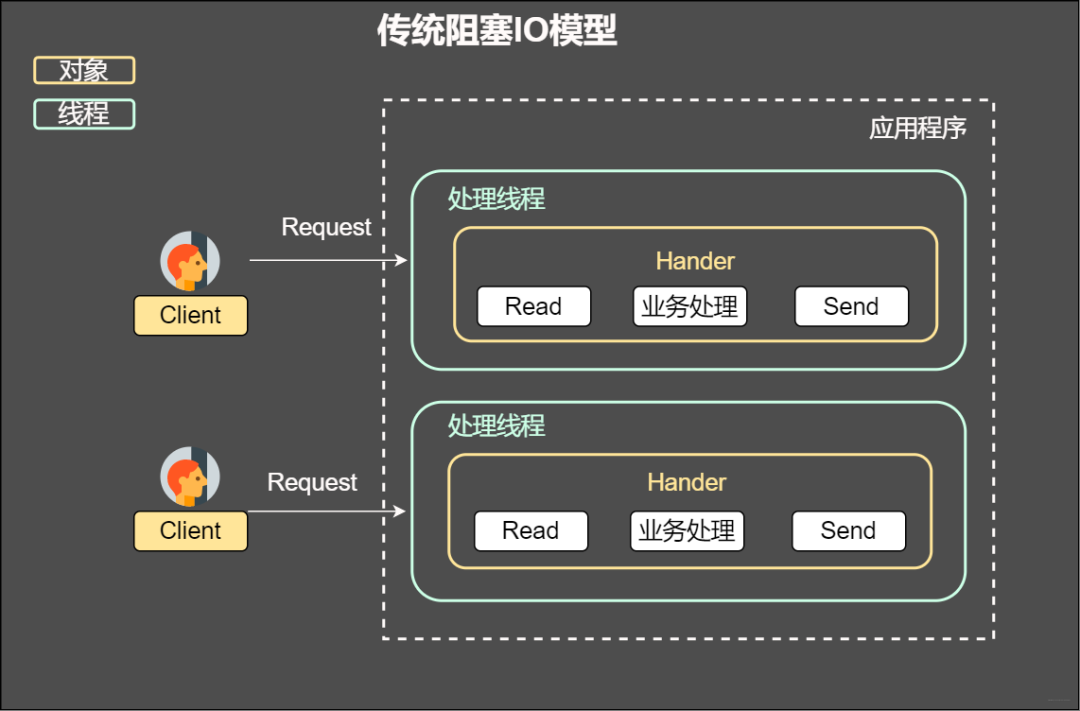
傳統阻塞IO模型
特點:
通過阻塞式IO獲取輸入的數據
其中每個連接都采用獨立的線程完成數據輸入,業務處理以及數據返回的操作
這種方案有什么問題?
首先當并發較大的時候,需要創建大量的線程來處理連接,需要占用大量的系統資源。
連接建立完成以后,如果當前線程沒有數據可讀,將會阻塞在read操作上造成線程資源的浪費
鑒于上面的兩個問題,通常是解決方案是啥呢?
第一種是采用IO復用的模型,所謂IO復用模型即多個連接共享一個阻塞對象,應用程序只會在一個阻塞對象上等待。當某個連接有新的數據處理,操作系統直接通知應用程序,線程從阻塞狀態返回并開始業務處理
第二種方案即采用線程池復用的方式。將連接完成后的業務處理任務分配給線程,一個線程處理多個連接的業務。IO復用結合線程池的方案即Reactor模式。
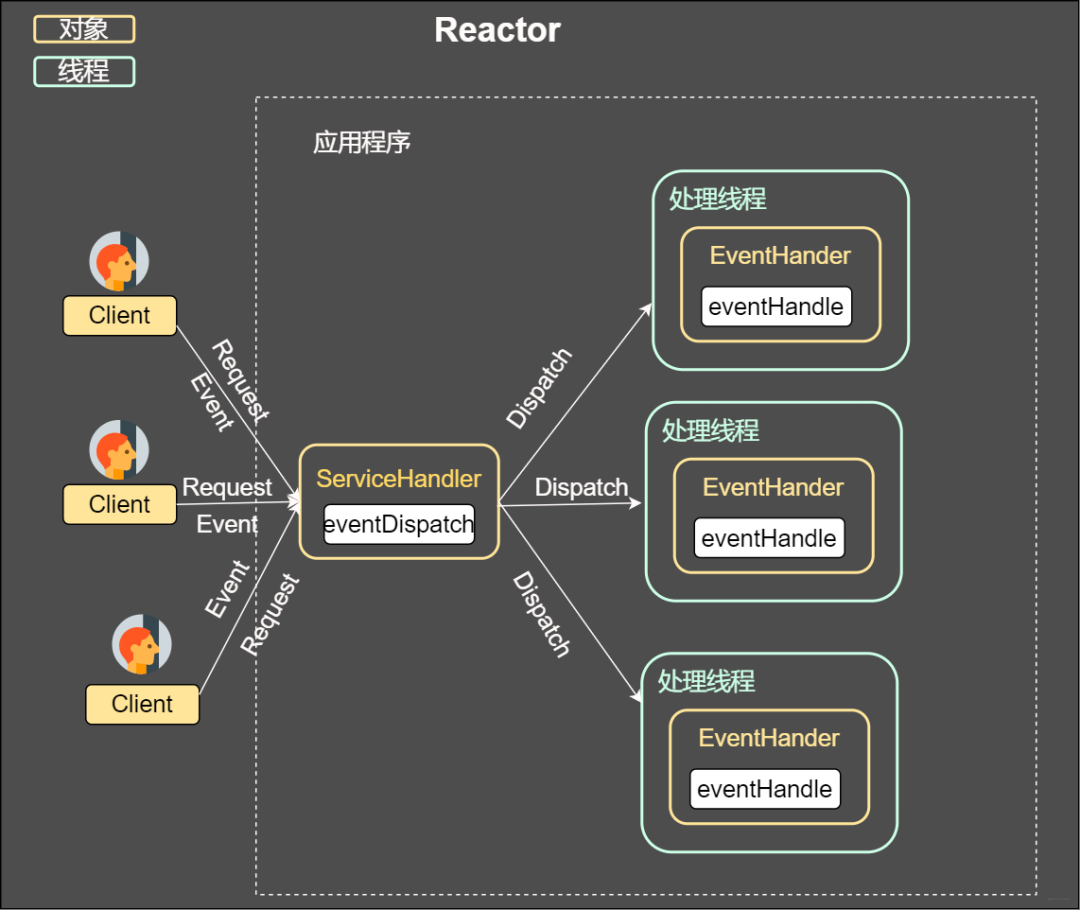
Reactor
從上圖我們可以發現,通過一個或者多個請求傳遞給服務器,通過統一的事件管理機制進行請求分發,這種模式即事件驅動處理模式。
通常一個服務端處理網絡請求的過程是啥樣的?
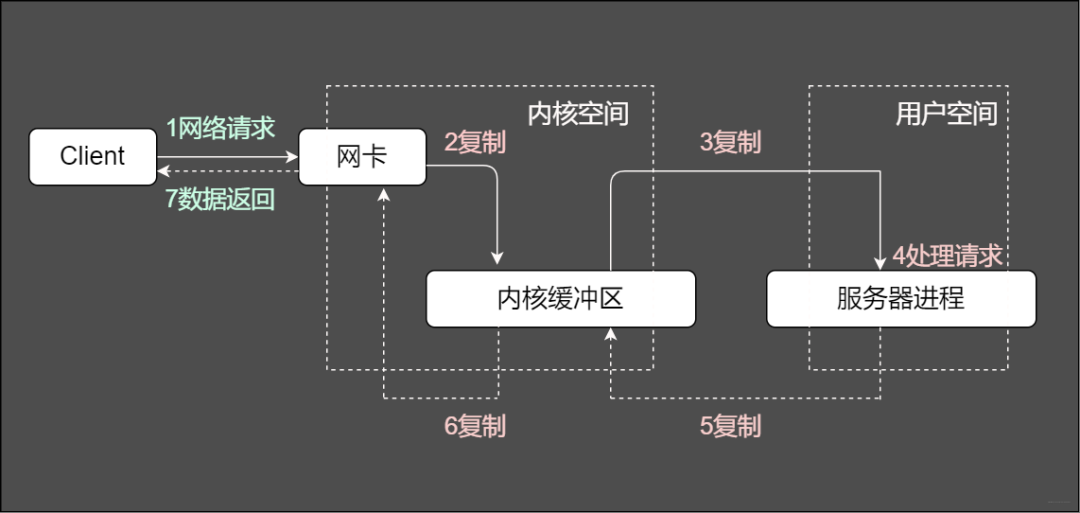
服務端處理請求的常規過程
服務端將這些請求分別同步分派給多個處理線程,即IO多路復用統一監聽事件,收到事件再進行分發。那么圖中重要的兩個關鍵字是啥意思?
Reactor
在一個單獨的線程運行,主要負責監聽和分發事件。就仿佛我們手機設置的轉接,將來自前任的電話轉接給適當的聯系人
Handlers
主要負責處理執行IO實際的事情。
根據Reactor的數量和處理的資源大小通常又分為單Reactor線程,單Reactor多線程,主從Reactor多線程。這部分將在文章后面進行詳細闡述,先和大家一起復習幾個基本概念
非阻塞
當使用非阻塞函數的時候,和阻塞IO類比,內核會立即返回,返回后獲得足夠的CPU時間繼續做其他的事情。
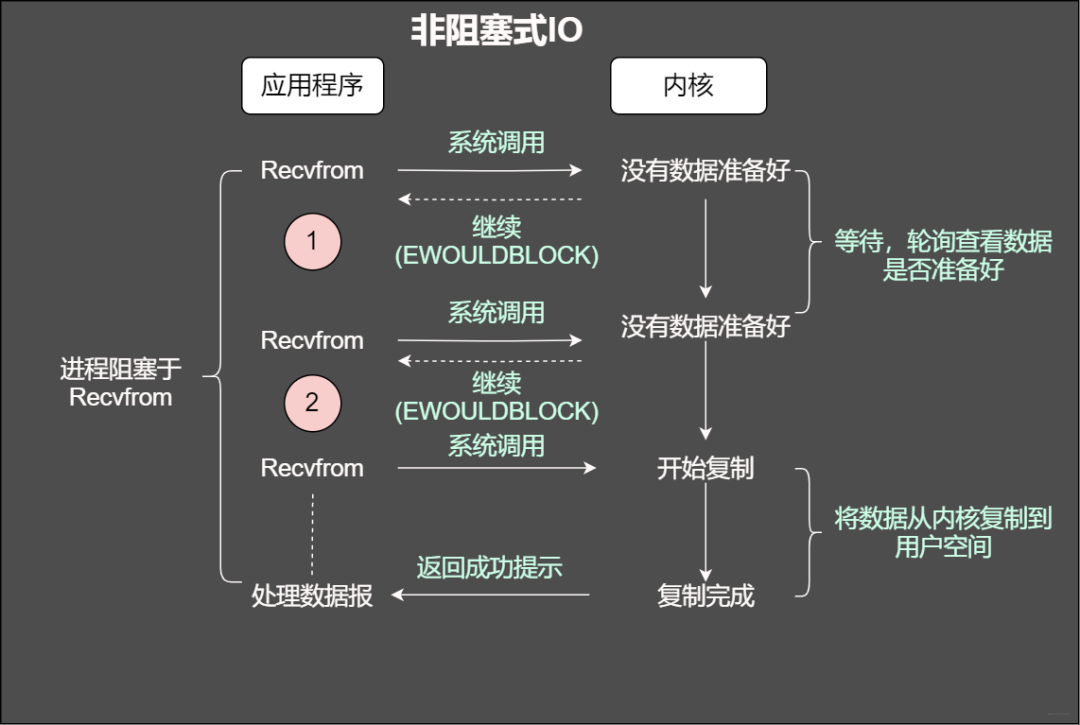
非阻塞
這樣說可能有點不太好理解,試試一個例子來
小藍經常去樓下的小賣部買煙,因為那小姐姐確實好看,即使不買去看看也飽了那種。有一天去買煙,讓我等下,他去倉庫看看,就一直在那里等著小姐姐回復,就仿佛阻塞在了小姐姐的店。
那么阻塞IO是個啥樣子嘞?
小姐姐,今天有黃鶴樓煙沒,小姐姐看看了柜臺,沒有,到處找也沒有了,然后告訴我這周沒有了,下周應該會有貨,好嘛,我寂寞的小手顫抖了,其實我就是想去小姐姐家買東西,于是下周我又去問小姐姐,小姐姐果然有心,就知道我回去她家店買,直接給我留了兩包黃鶴樓,就這樣反反復復,和小姐姐的感情越來越好,這樣就是阻塞IO的輪詢,我沒有被阻塞而是不斷地咨詢小姐姐(輪詢)。
抽煙的人,經常一句話就是“這一根抽了就不抽了”,怎么能忍住一周?看來輪詢效率太低,直接給小姐姐打電話:“小姐姐,煙到了麻煩通知一聲,我來你家拿”,這就是IO多路復用。
感情嘛,最激烈的時期不外乎是最開始的那么兩個月,不,渣男,怎么可能就兩個月,感情真是越來越好,然后我就給小姐姐說:“小姐姐,我給你個地址,還有微信,到時候到貨了麻煩給我寄過來”,這尼瑪,不僅加了微信,還給我送到了家,這就是異步IO,至于后續的故事是怎么樣的想知道?
好勒,就是寫IO模型,配上線程/進程所向披靡(網絡編程的核心)
非阻塞IO之讀(繼續查閱資料)
咱們知道套接字有個緩沖區,如果緩沖區沒有數據可讀,那么在非阻塞的情況下調用read就會立即返回,返回自然會有個狀態,不然我們一臉懵逼,無法進行下一步。返回可能是EWOULDBLOCK或者EAGAIN出錯信息。
非阻塞IO之寫
剛才我們說了,有個叫做緩沖區的概念,當然也有發送緩沖區,如果發送緩沖區滿了,不能容納更多的字節,這個時候操作系統內核就會盡全力從應用程序拷貝數據到發送緩沖區并立即從write調用返回。在拷貝的過程中,可能全部拷貝了,也可能一字節也沒拷貝,所以使用返回值來告訴應用程序到底有多少數據拷貝到了發送發送緩沖區,方便再次調用write,輸出未完成的字節。
總結下兩種方式:
阻塞IO是:拷貝-知道所有數據拷貝到發送緩沖區。
非阻塞IO是拷貝-返回-再拷貝-再返回。ok,read和write的騷操作如下圖

讀寫阻塞不同點
說了這么多,當面試官問你的時候,能不能對答如流嘞,總結如下:
read總是在接受緩存區有數據的時候直接返回,而不是等到應用程序哥頂的數據充滿才返回。如果此時緩沖區是空的,那么阻塞模式會等待,非阻塞則會返回-1并有EWOULDBLOCK或EAGAIN錯誤
和read不太一樣的是,在阻塞模式下,write只有在發送緩沖區足矣容納應用程序的輸出字節時才會返回。在非阻塞的模式下,能寫入多少則寫入多少,并返回實際寫入的字節數
當使用fgets等待標準輸入的時候,如果此時套接字有數據但不能讀出。IO多路復用意味著可以將標準輸入、套接字等都當做IO的一路,任何一路IO有事件發生,都將通知相應的應用程序去處理相應的IO事件,在我們看來就反復同時可以處理多個事情。這就是IO復用。
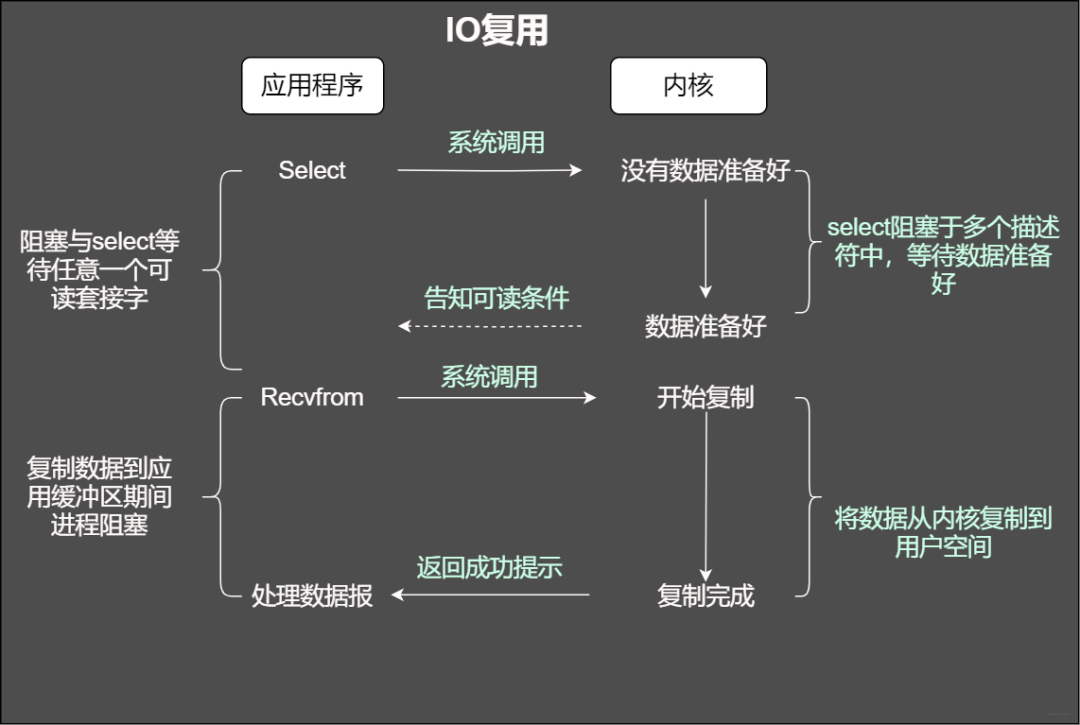
IO復用
2 select
當使用select函數的時候,先通知內核掛起進程,一旦一個或者多個IO事情發生,控制權將返回給應用程序,然后由應用程序進行IO處理。
那么IO事件都包含哪些
標準輸入文件描述符可以讀
已連接套接字準備好可以寫
如果一個IO事件等待超過10秒,發生超時
select使用方法
intselect(intmaxfdp,fd_set*readset,fd_set*writeset,fd_set*exceptset,structtimeval*timeout);
maxfdp 表示待測試描述符基數,它的值為待測試最大描述符加1.假設當前的select的測試描述符集合為{0,1,3},那么這個時候maxfd為4,
隨后為三個描述符集合,分別為讀集合readset,寫集合writeset和異常集合exceptset。它們會通知內核,當有可讀可寫發生的時候記得通知它們
如何設置這些描述符
intFD_ZERO(intfd,fd_set*fdset);//一個fd_set類型變量的所有位都設為0 intFD_CLR(intfd,fd_set*fdset);//清除某個位時可以使用 intFD_SET(intfd,fd_set*fd_set);//設置變量的某個位置位 intFD_ISSET(intfd,fd_set*fdset);//測試某個位是否被置位
最后一個參數是時間
structtimeval { longtv_sec;/*秒*/ longtv_usec;/*微秒*/ };
設置為NULL,select會一直等待下去
設置非零值,等待固定時間后返回
將tv_sec和tv_usec均設置為0,表示不等待,檢測完畢就返回
程序案例
#include
但是他有個比較明顯的特點就是所支持文件描述符有限,默認為1024個,隨機出現poll
3 poll
鑒于select所支持的描述符有限,隨后提出poll解決這個問題
還是先看聲明
intpoll(structpollfd*fds,nfds_tnfds,inttimeout);
再看pollfd結構
structpollfd{ intfd;/*文件描述符*/ shortevents;/*描述符待檢測的事件*/ shortrevents;/*returnedevents*/ };
注意下這個結構體,分別包含了文件描述符和描述符對應的事件,這事件和文件描述符緊密相結合,其中事件使用二進制掩碼表示,如POLLIN代表讀事件,POLLOUT代表寫事件。
#definePOLLIN0x0001/*anyreadabledataavailable*/ #definePOLLPRI0x0002/*OOB/Urgentreadabledata*/ #definePOLLOUT0x0004/*filedescriptoriswriteable*/
從結構中可以看見還有個參數是revents,從字面意思可知事件備份。對的,相當于將poll每次檢測的結果保留在revents,這樣就不需要每次都重置描述符和事件。那到底有哪些事件
可讀事件---系統內核會通知應用程序數據可讀
#definePOLLIN0x0001/*anyreadabledataavailable*/ #definePOLLPRI0x0002/*OOB/Urgentreadabledata*/ #definePOLLRDNORM0x0040/*non-OOB/URGdataavailable*/ #definePOLLRDBAND0x0080/*OOB/Urgentreadabledata*/
可寫事件---系統內核會通知套接字緩沖區已經可以安排,隨后使用write函數不會被堵塞
#definePOLLOUT0x0004/*filedescriptoriswriteable*/ #definePOLLWRNORMPOLLOUT/*nowritetypedifferentiation*/ #definePOLLWRBAND0x0100/*OOB/Urgentdatacanbewritten*/
了解函數返回值
小于0----表示事件發生前永遠等待
-1---發生錯誤
0--在指定的而時間沒有任何事件發生
poll和select不同之處在于,在select中,文件描述符個數隨著fd_set的實現而固定,而在poll函數中,我們可以通過控制pollfd數組的大小來改變描述符的個數
案例
#include
5 epoll
epoll 通過監控注冊的多個描述字,來進行 I/O 事件的分發處理。不同于 poll 的是,epoll 不僅提供了默認的 level-triggered(條件觸發)機制,還提供了性能更為強勁的edge triggered(邊緣觸發)機制
在The Linux Programming Interface有張圖展示三種IO復用技術在面對不同文件描述符時的差異

The Linux Programming Interface
從上圖咱們知道即使10000個描述符的時候,常規的select和poll性能下降明顯,而epoll變化不大
那么epoll是什么操作這么6?
epoll通過監控注冊多個描述字進行IO事件的分發。不同poll的是,epoll不僅提供默認的level-trigger機制還提供了邊緣觸發機制,這里可以先思考下兩者有什么區別
編程三步驟
intepoll_create(intsize);
就是通過它來創造實例,這個返回的值將用于后續的技能解鎖,如果不需要了這個實例,則需要使用close方法來釋放示例,不要占著坑不拉屎,這樣很不道德。
那這個size是干撒子的嘞?它告訴內核期望監控多少個描述符,然后使用這部分的信息來初始化內核底層的數據結構,不過時代在變化,在現在高版本的實現中,不在需要這個參數,自動動態化了,高級了吧。
intepoll_ctl(intepfd,intop,intfd,structepoll_event*event);
創建了實例,并有了返回值來標識這個示例,是時候添加事件了,此時就是使用epoll_ctl。第一個參數epfd即是上面的返回值。第二個參數表示是準備刪除事件還是監控事件,哪都有哪些選項呢

三個事件
第三個參數為注冊事件的文件描述符比如一個監聽字
第四個參數表示注冊的事件類型,可以在這個結構體中自定義數據。
intepoll_wait(intepfd,structepoll_event*events,intmaxevents,inttimeout); //返回值:成功返回的是一個大于0的數,表示事件的個數;返回0表示的是超時時間到;若出錯返回-1
epoll_wait函數和之前的select等類似,等待內核IO事件的分發。第一個參數為create返回值句柄。第二個參數回給用戶空間需要處理的 I/O 事件。第三個參數為一個大于0的整數,表示epoll_wait可以返回的最大事件值。第四個參數是epoll_wait阻塞時的超時值,如果設置為-1表示不超時,如果設置為0則立即返回。
6 epoll的底層實現
這部分內容,我在之前的文章中提過且給大家分享過一篇源碼筆記,大家需要的話也可以微信找我拿。
當我們使用epoll_fd增加一個fd的時候,內核會為我們創建一個epitem實例,講這個實例作為紅黑樹的節點,此時你就可以BB一些紅黑樹的性質,當然你如果遇到讓你手撕紅黑樹的大哥,在最后的提問環節就讓他寫寫吧
隨后查找的每一個fd是否有事件發生就是通過紅黑樹的epitem來操作
epoll維護一個鏈表來記錄就緒事件,內核會當每個文件有事件發生的時候將自己登記到這個就緒列表,然后通過內核自身的文件file-eventpoll之間的回調和喚醒機制,減少對內核描述字的遍歷,大俗事件通知和檢測的效率
7 C10K問題
這里的C代表并發,10K=10000。雖然現在通過現成的框架libevent/Netty可以輕松完成這個目標,但是在二十多年前,突破這個并發量還是非常困難的。那么要同時支撐這么多用戶,需要從哪些方面考慮呢
文件句柄
我們知道每個連接代表一個文件描述符,如果不夠用,新的鏈接將會被丟棄并產生錯誤
連接數過多
在Linux中默認為1024,但是如果你是root,你可以通過/etc/sysctl.cong來修改,使得支持1w個描述符
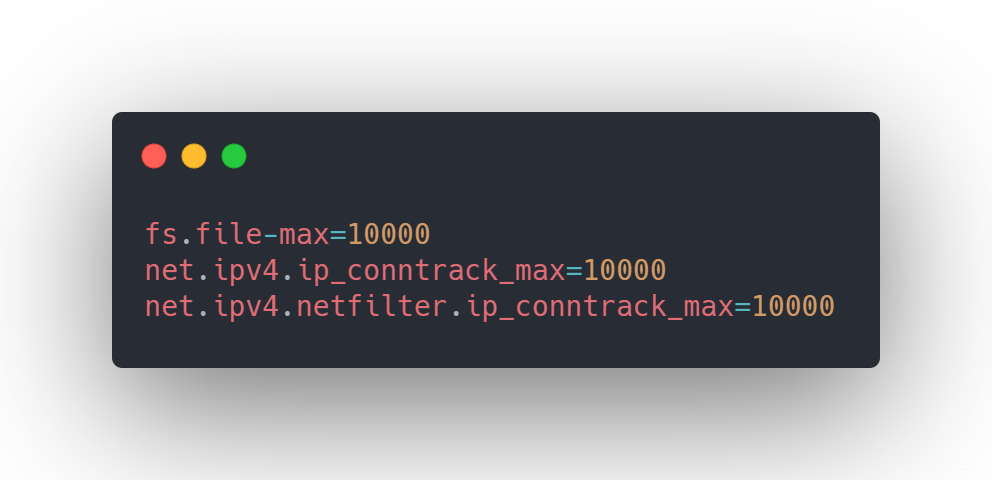
文件句柄
系統內存
每個連接不是只占用鏈接套接字那么簡單,每個鏈接都需要占用發送緩沖區和接收緩沖區,不信我們看看
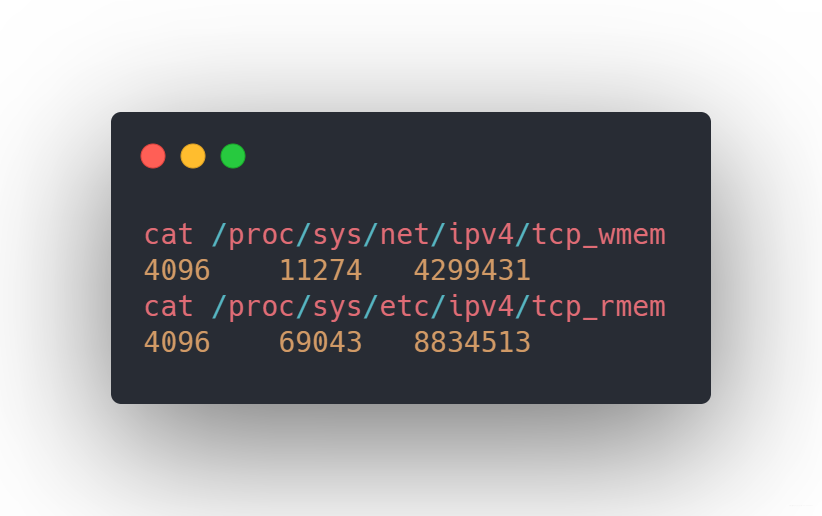
系統內存
上面三個值分別代表的是最小分配值、默認分配至和最大分配至,這樣如果1w個連接需要消耗
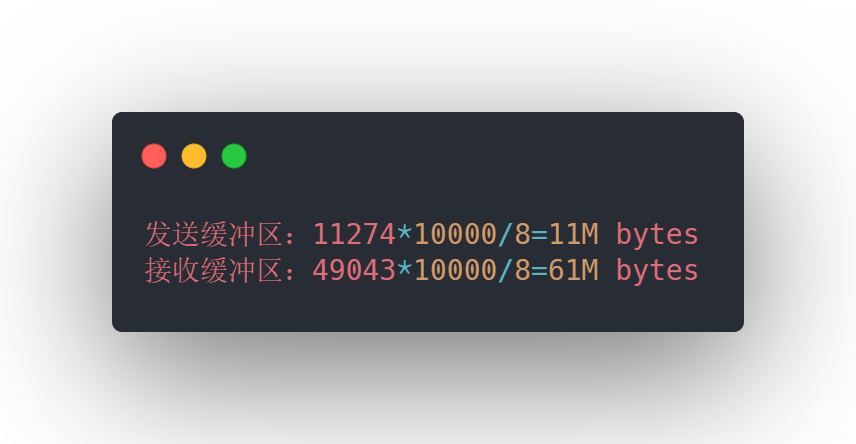
發送接收緩沖區
此時假設一個連接需要128K緩沖區,那么 1w 個連接大約需要 1.2G 應用層緩沖,所以支持w的連接不是內存的問題。
網絡帶寬
假設當前10個連接,其中每個鏈接傳輸大約1KB的數據,那么帶寬需要10 * 10000 * 1KB/s * 8=80MBPS。在現在看來也是很一般了
那么如何解決C10K問題?
一方面需要考慮到IO,也就是上面說的阻塞IO和非阻塞IO
如何分配進程,線程的資源服務上w的連接
阻塞IO與進程
這個好理解,來個連接我就分配個進程(fork)去處理,這個進程處理此鏈接的所有IO,不管是阻塞還是非阻塞IO,多個連接也不會產生影響,畢竟進程之間有著各自的進程空間
進程是程序執行的最小單位,一個進程有著完整的地址空間,程序計數器,想要創建一個進程,使用fork即可,fork后會在父子進程中各返回一次,如果返回值為0則是子進程,隨后父子進程處理各自的邏輯

fork
創建完進程執行了任務,當要離開的時候需要清理干凈資源,如果退出了還將進程的相關信息留下,不回收就會變為僵尸進程。這些僵尸進程不是沒人管了,會交給一個叫做init的進程,如果僵尸進程太多,勢必會占用太多的內存空間甚至耗盡我們的系統資源。
那如果想主動的回收這些資源,怎么辦呢?
處理子進程退出一般是注冊一個信號處理函數,然后捕捉信號SIGCHILD信號,在信號處理函數中調用waitpid函數完成資源的回收即可。
假設此時服務端開始監聽,兩個客戶端AB分別連接服務端,客戶端A發起請求后,連接成立返回新的套接字叫做連接套接字,此時父進程派生子進程,在子進程中使用連接套接字和客戶端通信,所以這個時候子進程不關心監聽套接字。父進程則相反,服務交給子進程后,不再關心連接套接字,而是關心監聽套接字,如下圖所示

客戶端A發起連接
缺點:效率不高,擴展性較差且資源占用率高
此時客戶端B發來新的請求,accept返回新的已連接套接字,父進程又派生子進程
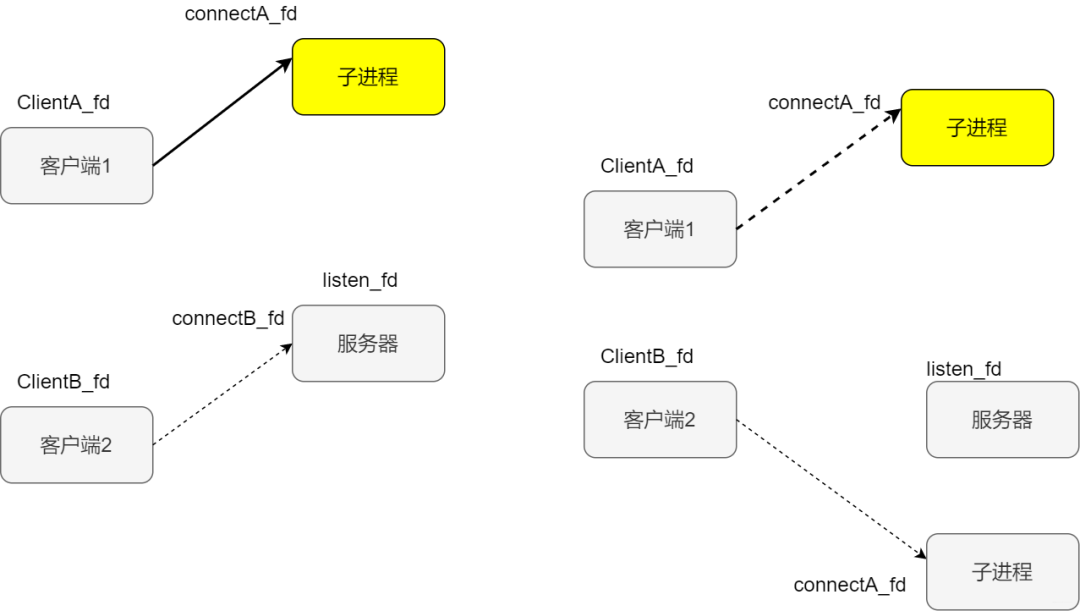
客戶端B發起請求
部分實現
while(1) { if((conn=accept(listenfd,(structsockaddr*)&peeraddr,&peerlen))
缺點:效率不高,擴展性較差且資源占用率高,注意事項
對套接字的關閉
子進程的回收
阻塞IO+線程
剛才不是說進程占用資源多么,那么就是用線程唄。單進程中可以有多個線程,每個線程都有自己的上下文,包括唯一標識的線程ID 程序計數器等,同一個進程的多個線程共享整個虛擬地址空間,其中包含了代碼、數據、堆。
為什么線程的上下文的開銷比進程少呢
我們的代碼是交給CPU執行的,程序計數器會告訴CPU代碼執行到哪兒了,寄存器呢會存儲當前計算的中間值,內存存放當前使用的變量,當切換到另外的計算場景的時候,需要重新載入新的值,這個時候就出現了上下文的切換
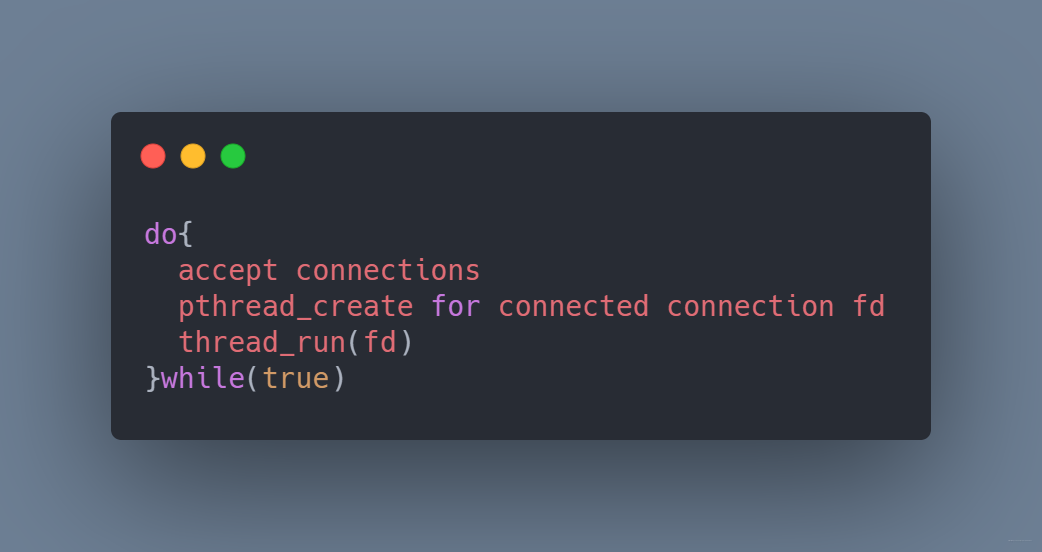
現在每個連接由一個線程處理
do{ acceptconnections pthread_createforconnecedconnectionfd thread_run(fd) }while(true)
主線程負責監聽連接請求
while(1) { //服務一直在運行,直到被某個操作或命令終止該進程 intrecvbytes; socklen_tlength=sizeof(cliaddr); //accept()函數讓服務器接收客戶的連接請求 intclientfd=accept(servfd,(structsockaddr*)&cliaddr,&length); if(clientfd
每個客戶連接的線程函數
void*recv_msg_from_client(void*arg) { //分離線程,使主線程不必等待此線程 pthread_detach(pthread_self()); intclientfd=*(int*)arg; intrecvBytes=0; char*recvBuf=newchar[BUFFER_SIZE]; memset(recvBuf,0,BUFFER_SIZE); while(1) { if((recvBytes=recv(clientfd,recvBuf,BUFFER_SIZE,0))<=?0)? ????????{ ????????????perror("recv出錯! "); ????????????return?NULL; ????????} ????????recvBuf[recvBytes]=''; ????????printf("recvBuf:%s ",?recvBuf); ????} ????close(clientfd); ????return?NULL; }
可是頻繁的創建線程也還是比較耗資源,這樣子是不是可以使用線程池提前創建一波線程,多個連接復用它即可

線程池
上面程序雖然可以較好地處理連接,但是如果并發較多,就會引起線程的頻繁切換和銷毀,怎們優化?
我們在服務端啟動的時候,預先分配固定大小的多個線程,當新連接建立的時候,從連接隊列中取出這個連接描述字進程處理
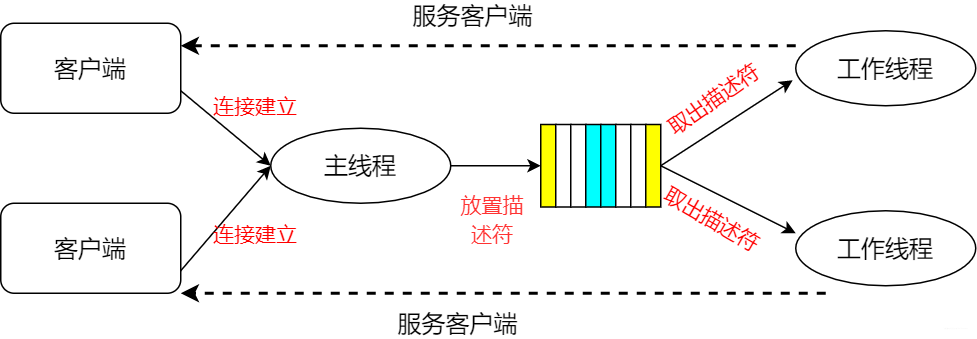
主線程與工作線程
細心地同學可能發現,既要從隊列取數據,也會從隊列寫數據,會不會有混亂。是的,所以通常還會使用mutex和條件變量進行加持。
但是不是每個鏈接都是需要時刻服務,每次創建線程還是比較消耗資源,那就提前創建一批線程,所謂線程池,復用線程池來獲取某種效率的提升
線程池
非阻塞 I/O + readiness notification + 單線程
我們的程序可以通過輪詢的方式對套接字進行挨個訪問,從而找出進行IO處理的套接字。

在這里插入圖片描述
描述符少還行,如果太多,每次的循環將消耗大量的CPU時間,而且可能循環完了都沒發現一個套接字可以讀寫。既然這樣,我們直接交給操作系統,讓它告訴我們哪些套接字可以讀寫。程序就變為這樣
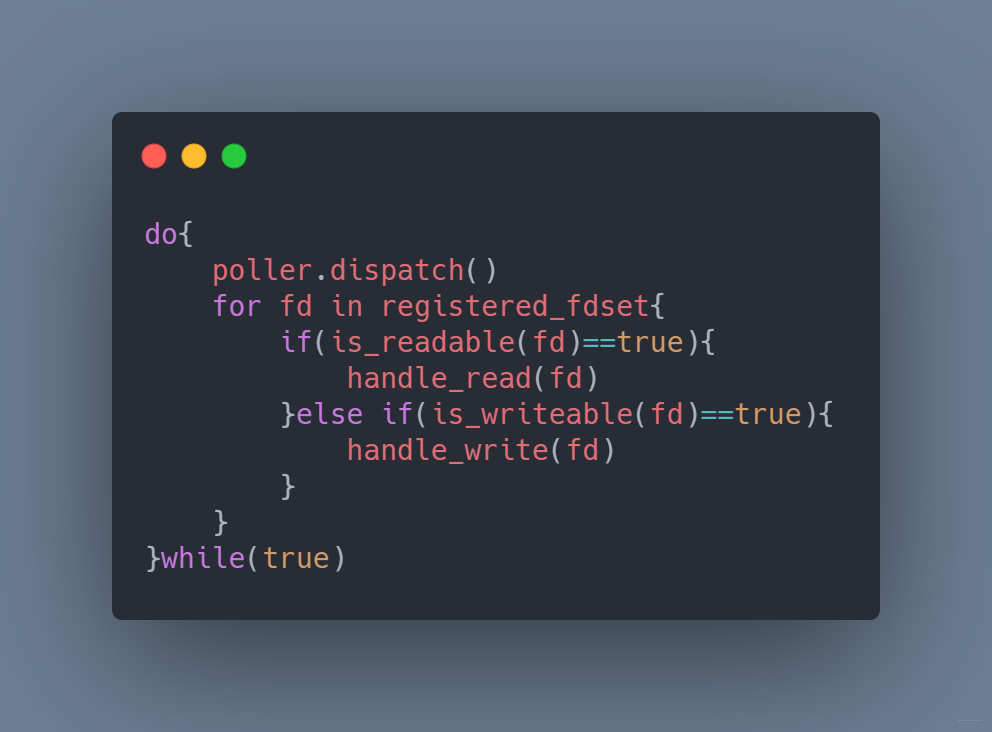
poll
我們每次dispatch就相當于對所有的套接字進行排查,這樣顯然效率不是很高。如果dispatch之后只提供有IO事件或者IO變化的套接字就好了,這就是epoll的設計
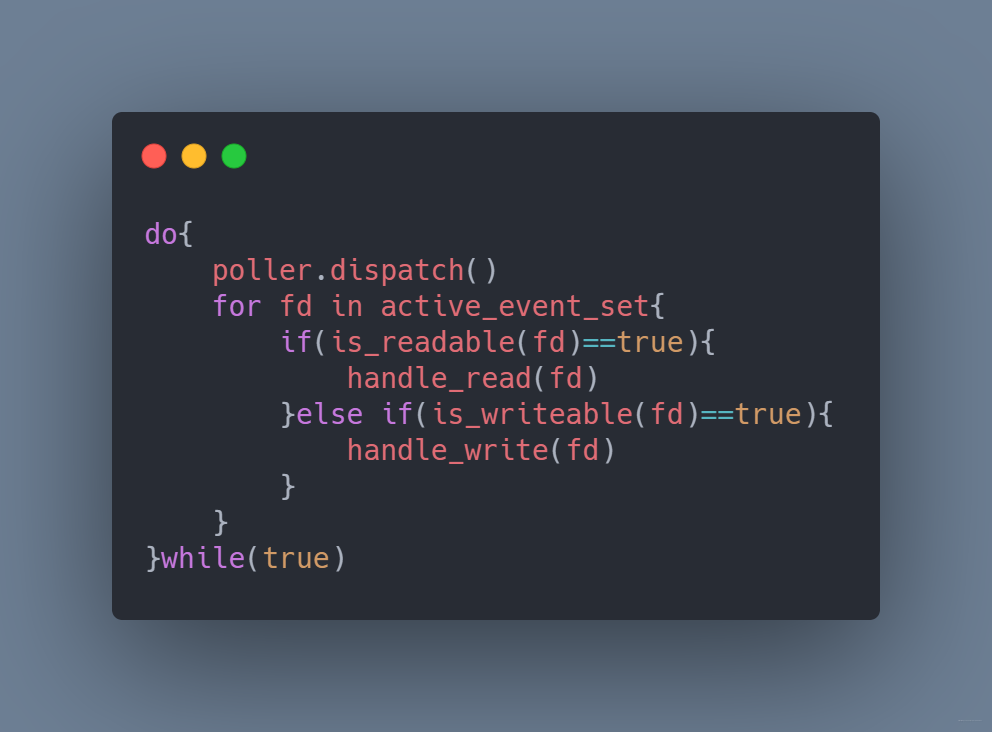
epoll
非阻塞 I/O + readiness notification + 多線程
上述幾種方案都是在一個線程分發,顯然沒有利用當今的多核技術,我們完全可以讓每個核作為一個IO分發器進行事件的分發,這其實就是reactor模式,也是后續將談到的事件驅動。
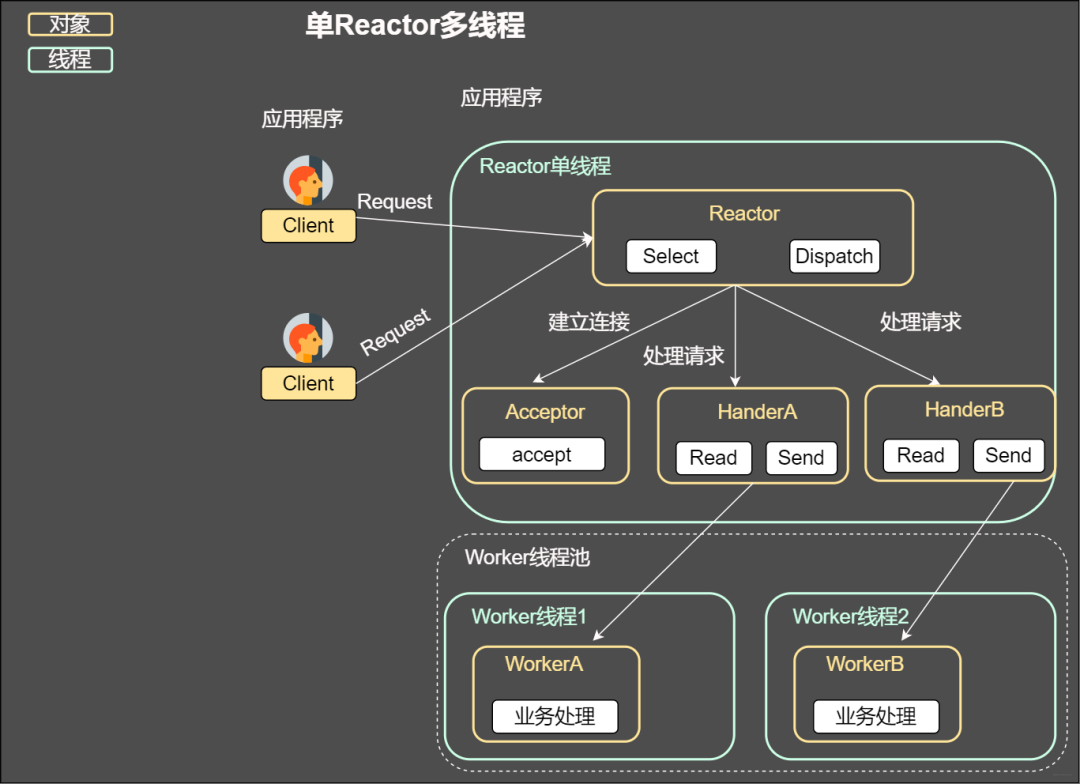
單Reactor多線程
8 事件驅動
事件驅動也叫做反應堆模型或者Event loop模型,重要的是兩點
通過poll、epoll等IO分發技術實現一個無限循環的事件分發線程
將所有的IO事件抽象為事件,每個事件設置回調函數
在處理大部分網絡程序的時候,無外乎處理一下幾個事兒
從套接字讀取數據
對收到的數據進行解析
根據解析的內容進行計算處理
處理后的結果按照約定的格式編碼
通過套接字發送出去
那么之前我們說了使用fork子進程的方式實現通信,隨著客戶端的增多,處理效率不高,因為fork的開銷太大
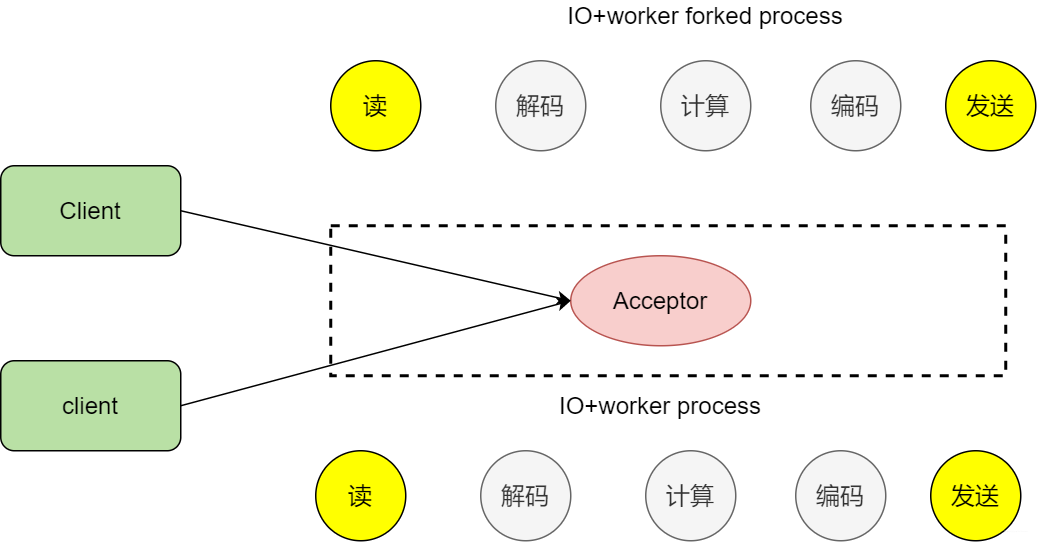
fork
為什么說事件驅動是一種高性能,高并發的模式?
既然這么牛皮,當然有它的特點。舉個例子,來成都一個月,印象特別深刻卻是到處都是咖啡館,點一杯咖啡坐著一邊喝一邊看妹子,服務員小姐姐也不會找我,只有當我去續杯的時候,再找小姐姐勾搭(觸發事件了),小姐姐滿足了我的需求,我就接著邊喝咖啡邊看其他小姐姐,這就是事件驅動。看個圖
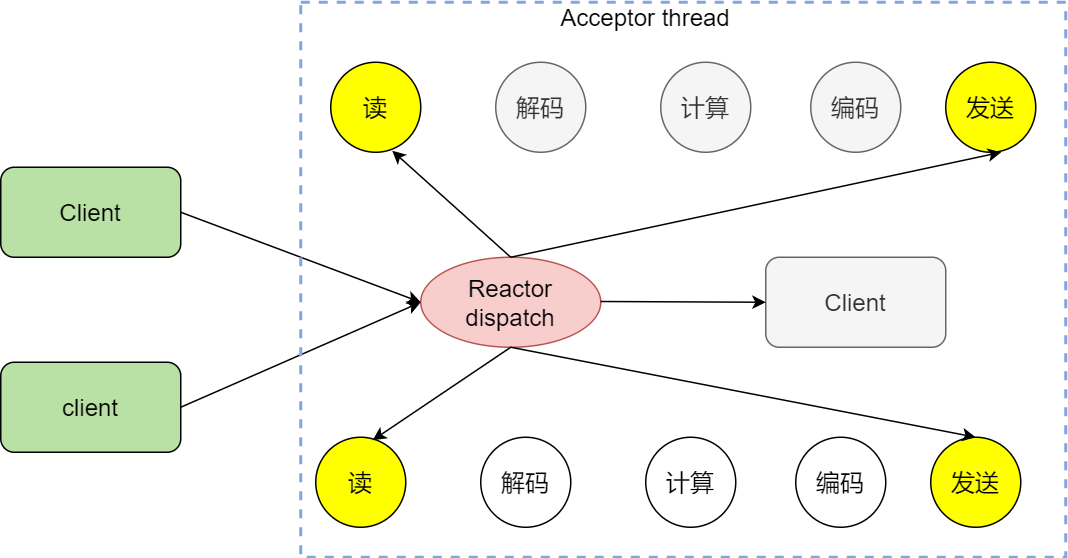
事件驅動
為了模式整體的效率,不能因為處理業務邏輯導致IO事件處理的效率下降,所以我們決定將注入XML文件的解析,數據庫的查找等工作放在其他線程中,所謂將這些工作和反應堆線程解耦。讓這個反應堆只處理IO相關任務,業務邏輯這些操作分成小任務放在線程池中讓其他空閑的線程處理。處理完后再交給反應堆,然后發送出去
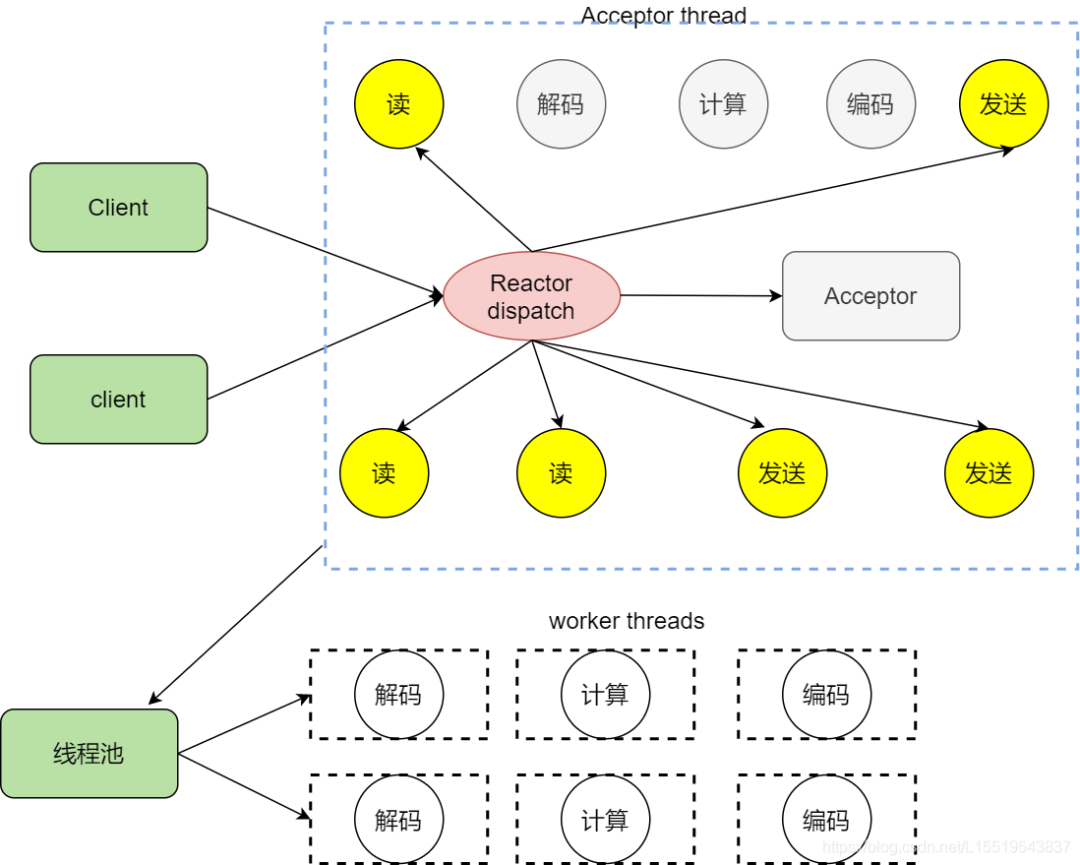
拆分業務邏輯
主從Reactor
ok,咱們已經知道使用Reactor反應堆的方式同時分發Acceptor上的連接建立事件,但是我們還是沒有完全實現解耦,這個Reactor線程既要分發連接建立,還要分發已經建立連接的IO,如果太多的客戶請求是不是會處理不過來,那么能不能讓其分離嘞
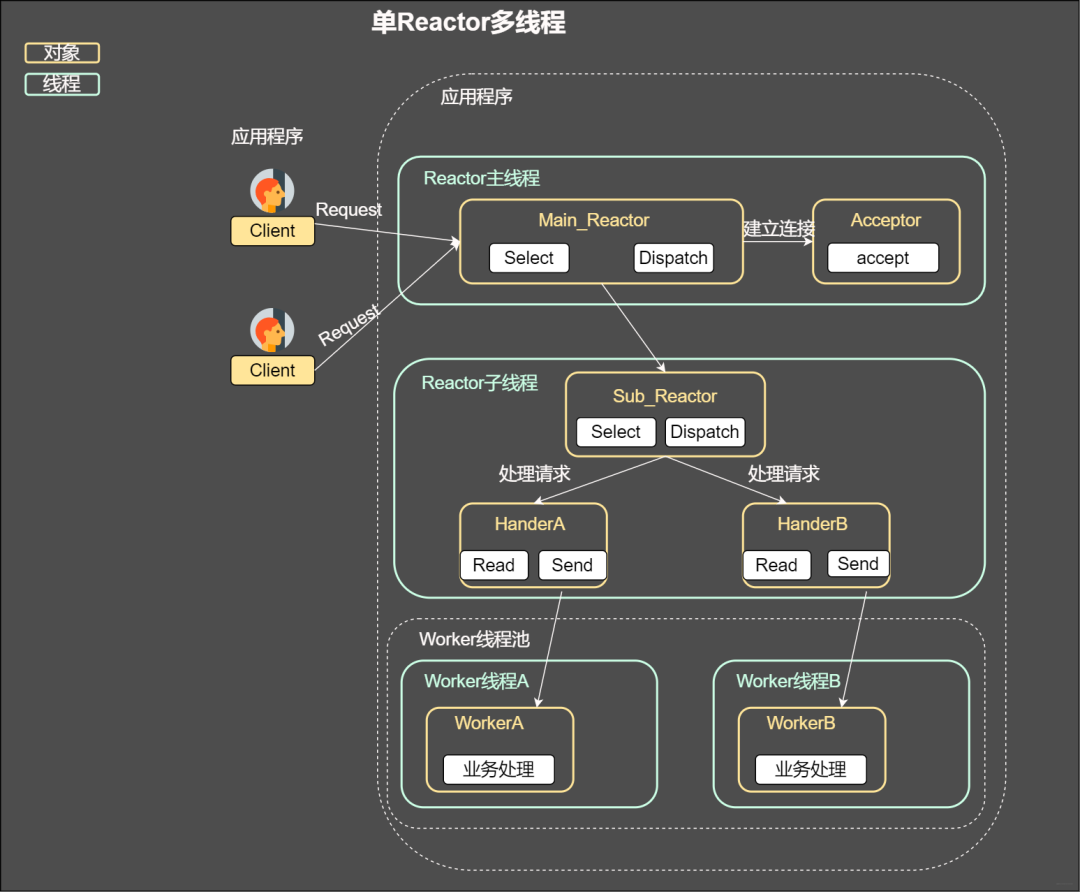
主從Reactor
我們看看主從reactor的方式,思路很清晰,主reactor主負責分發Acceptor連接建立,然后已經聯機的IO事件交給sub-reactor,這個sub-reactor的數量可以根據CPU的核數來定。
假設咱們是一個四核的CPU,設置sub-reactor為4.這個時候4個反應堆同時干活,是不是增強了IO分發處理的效率,因為多核操作,也大大的減少并發處理的鎖開銷。
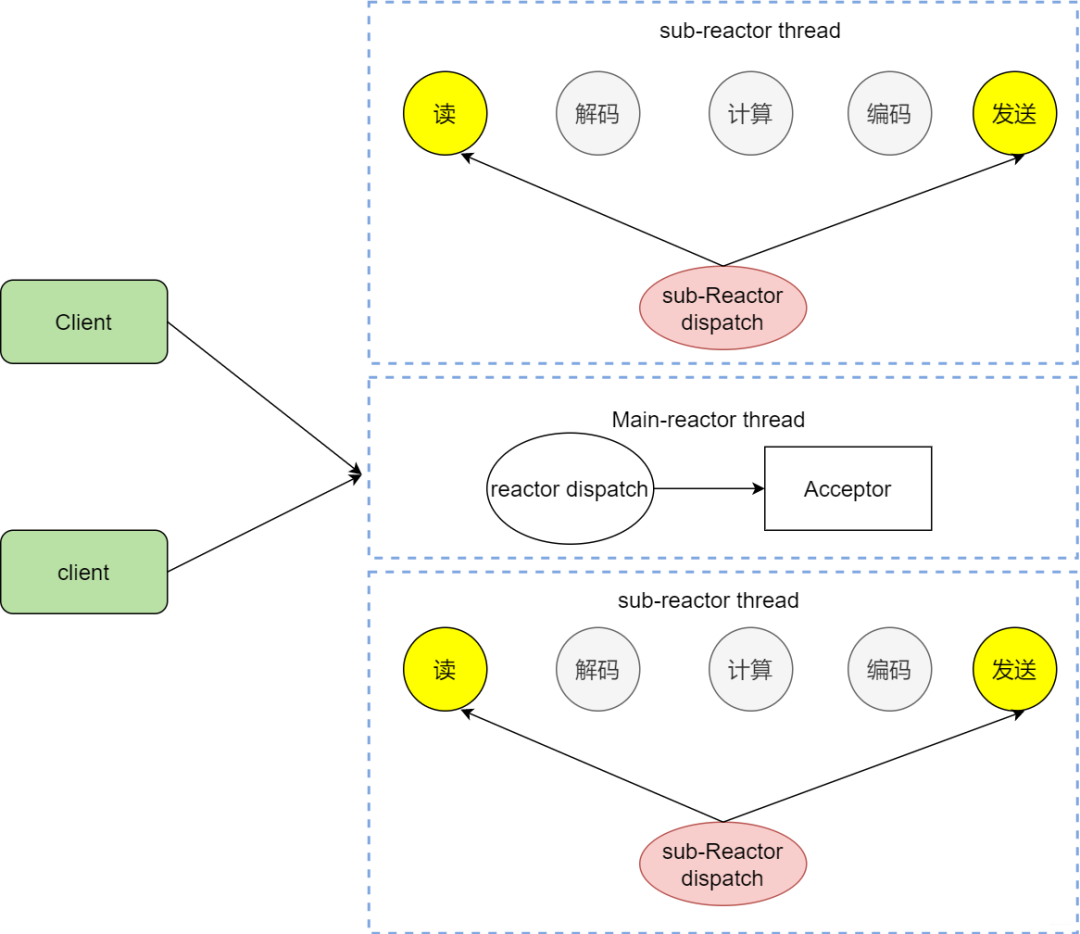
多Reactor
epoll
上面說了poll的reactor反應堆模式,和poll相比,epoll可謂更加高效的事件機制。
如何切換到epoll呢
在lib/event_loop.c中的event_loop_init_with_name中,可以發現通過宏EPOLL_ENABEL來決定使用哪一個
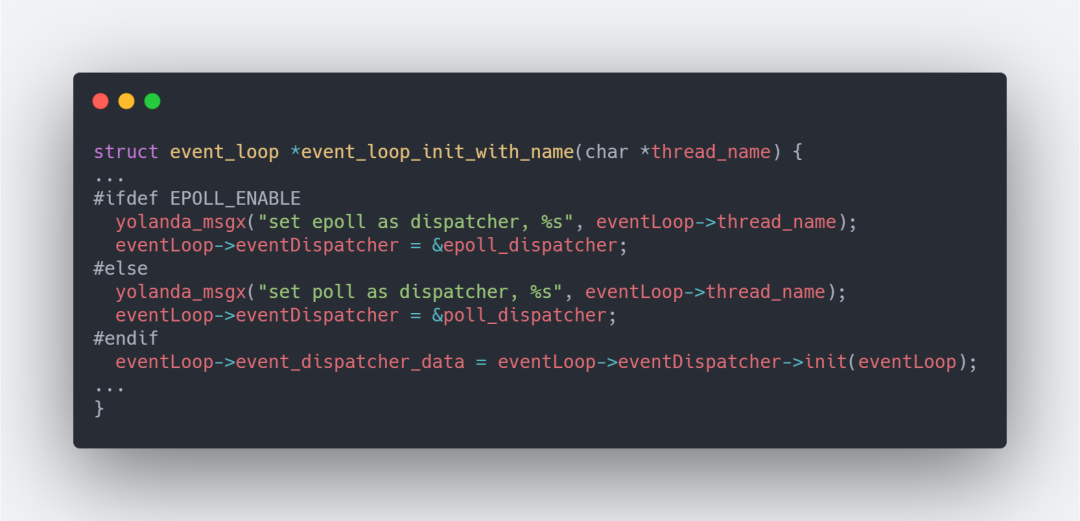
EPOLL_ENABEL
然后我們在根目錄中查看CMakeLists.txt文件,如果系統中有epoll_create就會自動開啟EPOLL_ENALE,如果沒有則采用默認的poll作為事件分發機制。
EPOLL_ENALE
這還沒完,我們需要讓編譯器知道這個宏,所以需要讓CMake往config.h文件寫入這個宏的最終值。
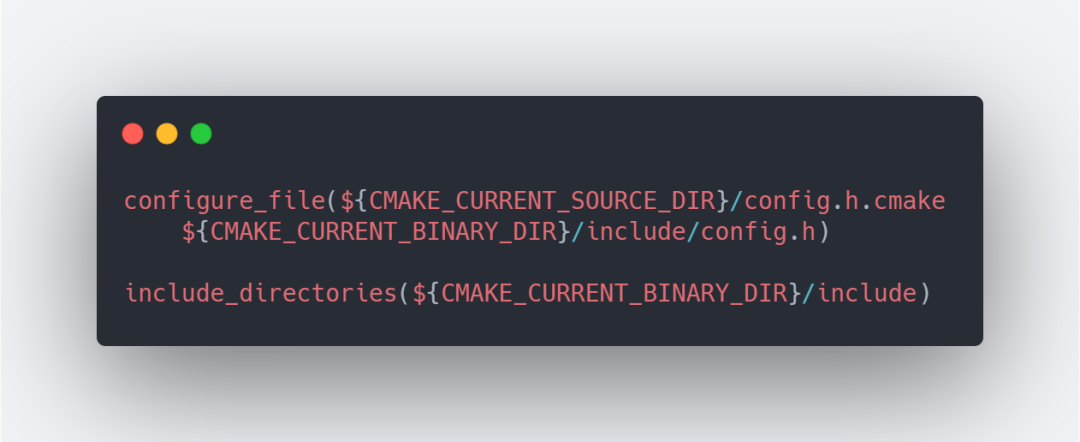
配置config.h
那么,為啥epoll的性能就比poll更好呢
首先poll和select,在使用之前需要一個感興趣的事件集合,系統內核通過它構建相應的數據結構并注冊,epoll卻不是,它會維護一個全局的事件集合,通過epoll的句柄操作這個集合,操作系統內核不需要每次重新掃描整個集合
使用poll或者select的時候,應用程序需要掃描整個感興趣的事件集合并找出活動的事件,如果請求量過大,掃描一次花費的時間就太長。而epoll不是,epoll直接返回活動的事件,減少大量的掃描時間。
那么邊緣觸發與條件觸發到底是啥意思
如果某個套接字有1000個字節需要讀,兩個方案都會產生read ready notification,如果應用程序只讀了500字節,就會陷入等待,對于條件觸發就不一樣,它會因為還有500字節而不斷地產生read ready notification
異步IO
用程序告知內核啟動某個操作,并讓內核在整個操作(包括將數據從內核拷貝到應用程序的緩沖區)完成后通知應用程序。那么和信號驅動有啥不一樣?
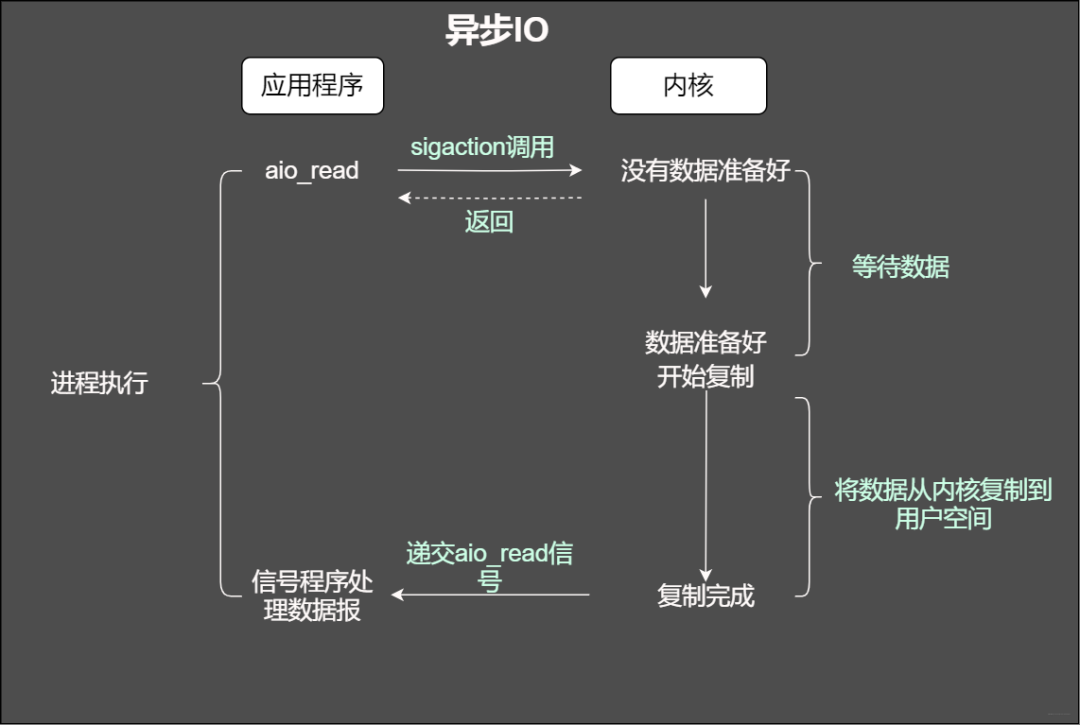
異步IO
信號驅動IO試內核通知應用程序什么時候啟動一個IO操作。而異步IO模型是由內核通知應用程序啥時候完成。
異步IO的主要優點是充分的利用DMA特性。缺點是,如果要完成真正的異步IO,對于操作系統的壓力較大,需要做大量的工作。
現在我們已經知道了阻塞IO 非阻塞IO,以及通過select epoll poll等IO多路復用并結合線程池的方案實現高性能的網絡框架。但是還有個與之相對應叫做proactor的網絡驅動模式,兩者有什么區別?
在windows中這一套完整的支持套接字的異步編程接口叫做IOCP,和Reactor模式一樣之處在于,也存在一個無限循環的event loop線程的,但是不同于Reactor模式,這個線程不負責處理IO調用,只是負責在對應的read,write操作完成的情況下,分發完成事件道不同的處理函數。簡單的一句話總結即Reactor模式基于待完成的IO事件,而Proactor模式基于已完成的IO事件。
責任編輯:xj
原文標題:「網絡IO套路」當時就靠它追到女友
文章出處:【微信公眾號:Linux愛好者】歡迎添加關注!文章轉載請注明出處。
-
網絡
+關注
關注
14文章
7593瀏覽量
89072 -
編程
+關注
關注
88文章
3636瀏覽量
93892 -
異步
+關注
關注
0文章
62瀏覽量
18076 -
阻塞
+關注
關注
0文章
24瀏覽量
8134
原文標題:「網絡IO套路」當時就靠它追到女友
文章出處:【微信號:LinuxHub,微信公眾號:Linux愛好者】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
借助IO-Link收發器簡化微控制器設計
一體式遠程IO的Profinet通信協議模組-三格電子

λ-IO:存儲計算下的IO棧設計

本地IO與遠程IO:揭秘工業自動化中的兩大關鍵角色
FPGA-5G通信算法的基本套路

初識IO-Link及IO-Link設備軟件協議棧
什么是遠程IO模塊?它有哪些分類?
遠程IO與分布式IO的區別
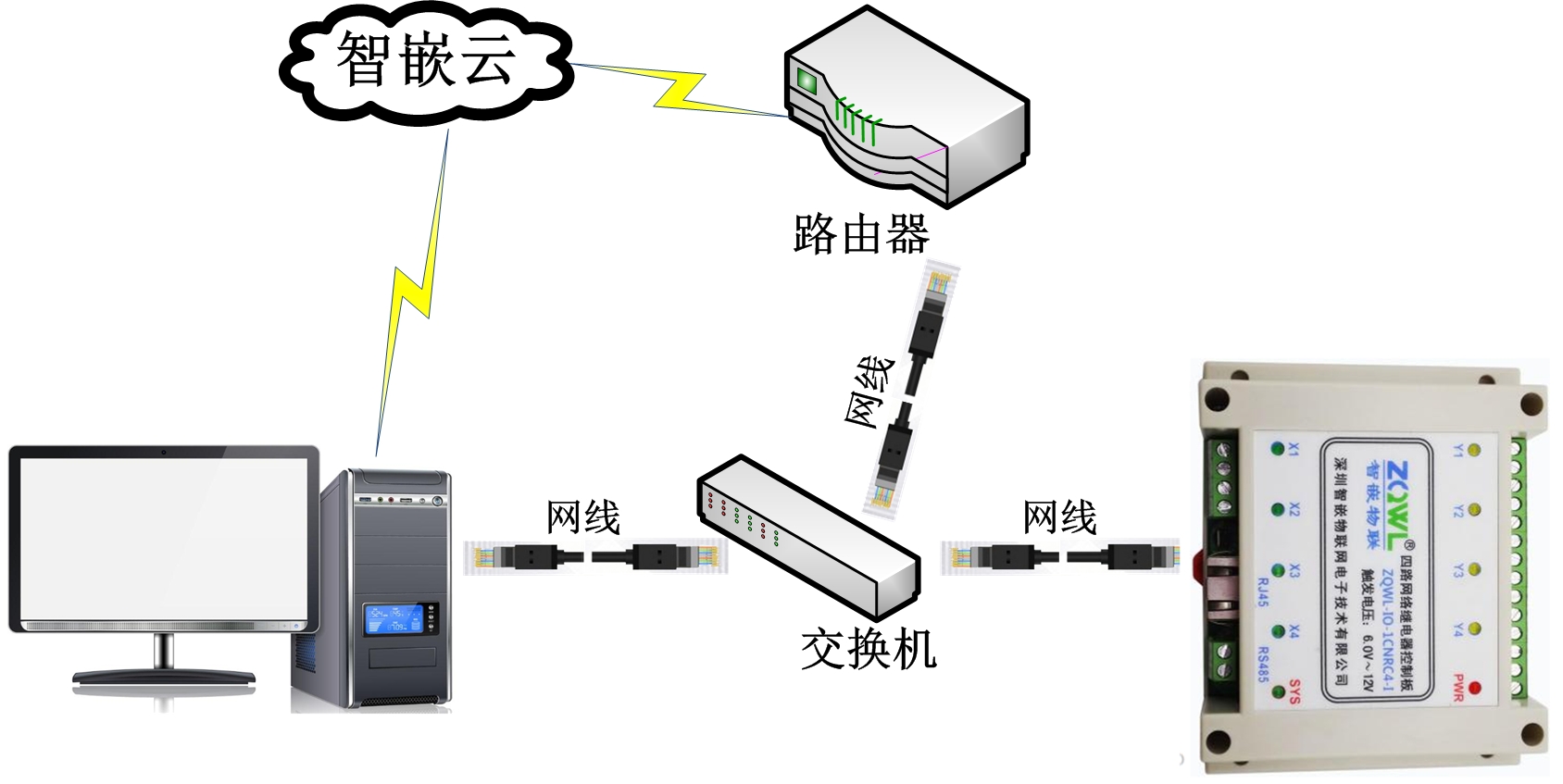
智嵌物聯網絡IO控制器接入智嵌云控演示





 工商網監
工商網監
評論