") OpenAI重磅推出語(yǔ)言模型DALL·E和圖像識(shí)別系統(tǒng)CLIP
OpenAI重磅推出語(yǔ)言模型DALL·E和圖像識(shí)別系統(tǒng)CLIP
人工智能(AI)研究組織OpenAI重磅推出了最新的語(yǔ)言模型DALL·E和圖像識(shí)別系統(tǒng)CLIP。
這兩個(gè)模型是OpenAI第三代語(yǔ)言生成器的一個(gè)分支。兩種神經(jīng)網(wǎng)絡(luò)都旨在生成能夠理解圖像和相關(guān)文本的模型。OpenAI希望這些升級(jí)后的語(yǔ)言模型能夠以接近人類解釋世界的方式來(lái)解讀圖像。
2020年5月,OpenAI發(fā)布了迄今為止全球規(guī)模最大的預(yù)訓(xùn)練語(yǔ)言模型GPT-3。GPT-3具有1750億參數(shù),訓(xùn)練所用的數(shù)據(jù)量達(dá)到45TB。對(duì)于所有任務(wù),應(yīng)用GPT-3無(wú)需進(jìn)行任何梯度更新或微調(diào),僅需要與模型文本交互為其指定任務(wù)和展示少量演示即可使其完成任務(wù)。
GPT-3在許多自然語(yǔ)言處理數(shù)據(jù)集上均具有出色的性能,包括翻譯、問(wèn)答和文本填空任務(wù),還包括一些需要即時(shí)推理或領(lǐng)域適應(yīng)的任務(wù)等,已在很多實(shí)際任務(wù)上大幅接近人類水平。
新發(fā)布的語(yǔ)言模型DALL·E,是GPT-3的120億參數(shù)版本,可以按照自然語(yǔ)言文字描述直接生成對(duì)應(yīng)圖片!
這個(gè)新系統(tǒng)的名稱DALL·E,來(lái)源于藝術(shù)家薩爾瓦多·達(dá)利(Salvador Dali)和皮克斯的機(jī)器人英雄瓦力(WALL-E)的結(jié)合。新系統(tǒng)展示了“為一系列廣泛的概念”創(chuàng)造圖像的能力,可從文字標(biāo)題直接創(chuàng)建圖像以表達(dá)概念。通過(guò)從文本描述而不是標(biāo)簽數(shù)據(jù)生成圖像,可以為模型提供了更多有關(guān)含義的上下文。
開(kāi)發(fā)人員將DALL·E稱為“轉(zhuǎn)換語(yǔ)言模型”(transformer language model),能夠?qū)⑽谋竞蛨D像作為單個(gè)數(shù)據(jù)流接收。這種訓(xùn)練程序使得DALL·E不僅可以從零開(kāi)始生成圖像,而且還可以重新生成現(xiàn)有圖像的任何矩形區(qū)域……。以一種與文本提示一致的方式。
這種語(yǔ)言模型能夠反映人類語(yǔ)言的微妙之處,包括 “將不同的想法結(jié)合起來(lái)合成物體的能力”。例如,在DALL·E模型中輸入“牛油果形狀的扶手椅”,它就可以生成這樣的圖片:

DALL·E還擴(kuò)展了被稱為“零樣本推理”(zero-shotreasoning)的GPT-3功能,這是一種強(qiáng)大的常識(shí)性機(jī)器學(xué)習(xí)形式。DALL·E將這一功能擴(kuò)展到了視覺(jué)領(lǐng)域,并且在以正確的方式提示時(shí)能夠執(zhí)行多種圖像到圖像的翻譯任務(wù)。

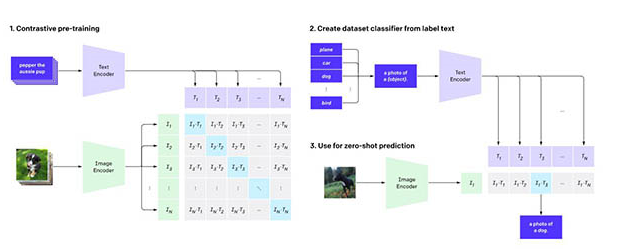
圖像識(shí)別系統(tǒng)CLIP的通用性比當(dāng)前針對(duì)單個(gè)任務(wù)的系統(tǒng)更好,可以用網(wǎng)上公開(kāi)的文字圖像配對(duì)數(shù)據(jù)集來(lái)訓(xùn)練。CLIP系統(tǒng)可用于對(duì)比語(yǔ)言-圖像預(yù)訓(xùn)練,通過(guò)從網(wǎng)絡(luò)圖像中收集的自然語(yǔ)言監(jiān)督學(xué)習(xí)視覺(jué)概念。OpenAI表示CLIP的工作方式是提供要識(shí)別的視覺(jué)類別的名稱。
當(dāng)將其應(yīng)用于圖像分類基準(zhǔn)時(shí),可以指示模型執(zhí)行一系列基準(zhǔn),而無(wú)需針對(duì)每個(gè)測(cè)試進(jìn)行優(yōu)化。OpenAI表示:“通過(guò)不直接針對(duì)基準(zhǔn)進(jìn)行優(yōu)化,我們證明它變得更具代表性。” CLIP方法可將“穩(wěn)健性差距”縮小多達(dá)75%。
OpenAI 聯(lián)合創(chuàng)始人、首席科學(xué)家 Ilya Sutskever認(rèn)為,人工智能的長(zhǎng)期目標(biāo)是構(gòu)建多模態(tài)神經(jīng)網(wǎng)絡(luò),即AI能夠?qū)W習(xí)不同模態(tài)之間的概念(文本和視覺(jué)領(lǐng)域?yàn)橹鳎瑥亩玫乩斫馐澜纾?DALL·E 和 CLIP 使我們更接近“多模態(tài) AI 系統(tǒng)”這一目標(biāo)。
未來(lái),我們將擁有同時(shí)理解文本和圖像的模型。人工智能將能夠更好地理解語(yǔ)言,因?yàn)樗梢钥吹絾卧~和句子的含義。
編輯:hfy
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4774瀏覽量
100898 -
圖像識(shí)別
+關(guān)注
關(guān)注
9文章
520瀏覽量
38290 -
人工智能
+關(guān)注
關(guān)注
1792文章
47425瀏覽量
238963 -
Clip
+關(guān)注
關(guān)注
0文章
31瀏覽量
6673 -
OpenAI
+關(guān)注
關(guān)注
9文章
1100瀏覽量
6576
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
AI圖像識(shí)別攝像機(jī)

AI大模型在圖像識(shí)別中的優(yōu)勢(shì)
圖像識(shí)別算法都有哪些方法
圖像識(shí)別算法的提升有哪些
圖像識(shí)別算法的優(yōu)缺點(diǎn)有哪些
圖像識(shí)別技術(shù)包括自然語(yǔ)言處理嗎
圖像識(shí)別技術(shù)的原理是什么
圖像識(shí)別屬于人工智能嗎
如何利用CNN實(shí)現(xiàn)圖像識(shí)別
愛(ài)芯元智推出邊端側(cè)智能SoCAX650N,讓視覺(jué)更智能
OpenAI推出專用的AI檢測(cè)工具
微軟封禁員工討論OpenAI DALL-E 3模型漏洞
圖像識(shí)別技術(shù)原理 圖像識(shí)別技術(shù)的應(yīng)用領(lǐng)域
基于TensorFlow和Keras的圖像識(shí)別






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論