") 通過光纖實現(xiàn)高速數(shù)據(jù)片外回環(huán)實驗案例
通過光纖實現(xiàn)高速數(shù)據(jù)片外回環(huán)實驗案例
10G以太網(wǎng)光口與高速串行接口的使用越來越普遍,本文擬通過一個簡單的回環(huán)實驗,來說明在常見的接口調(diào)試中需要注意的事項。各種Xilinx FPGA接口學習的秘訣:Example Design。歡迎探討。
一、實驗目的
為實現(xiàn)大容量交換機與高速率通信設備之間的高效數(shù)據(jù)傳輸,高速接口的理解與使用愈發(fā)顯現(xiàn)出其重要地位。本實驗設計中計劃使用四個GTH高速串行接口,分別采用了10G以太網(wǎng)接口協(xié)議以及Aurora64b66b接口協(xié)議,實現(xiàn)交換板到測試設備的連接并通過光纖實現(xiàn)高速數(shù)據(jù)片外回環(huán),以達到快速理解接口協(xié)議并能夠熟練使用該兩種高速接口實現(xiàn)數(shù)據(jù)收發(fā)的目的。
二、接口簡介
1、 GT接口簡介
應用在高速串行接口的數(shù)據(jù)收發(fā)。在A7系列芯片中叫GTP、在K7系列叫GTX、V7系列叫GTH,對于不同速度等級的高速通信的物理接口,原理基本一致。
1.1、收發(fā)器結(jié)構(gòu)
對于每一個串行高速收發(fā)器,其分為兩個子層:PCS(物理編碼子層)和 PMA(物理媒體連接子層)。PCS 層主要進行數(shù)據(jù)編解碼以及多通道的處理;PMA 層主要進行串并、并串轉(zhuǎn)換,預加重、去加重,串行數(shù)據(jù)的發(fā)送、數(shù)據(jù)時鐘的提取。可以使用ibert IP核對接口進行回環(huán)測試,確定該接口是否可以正常使用。
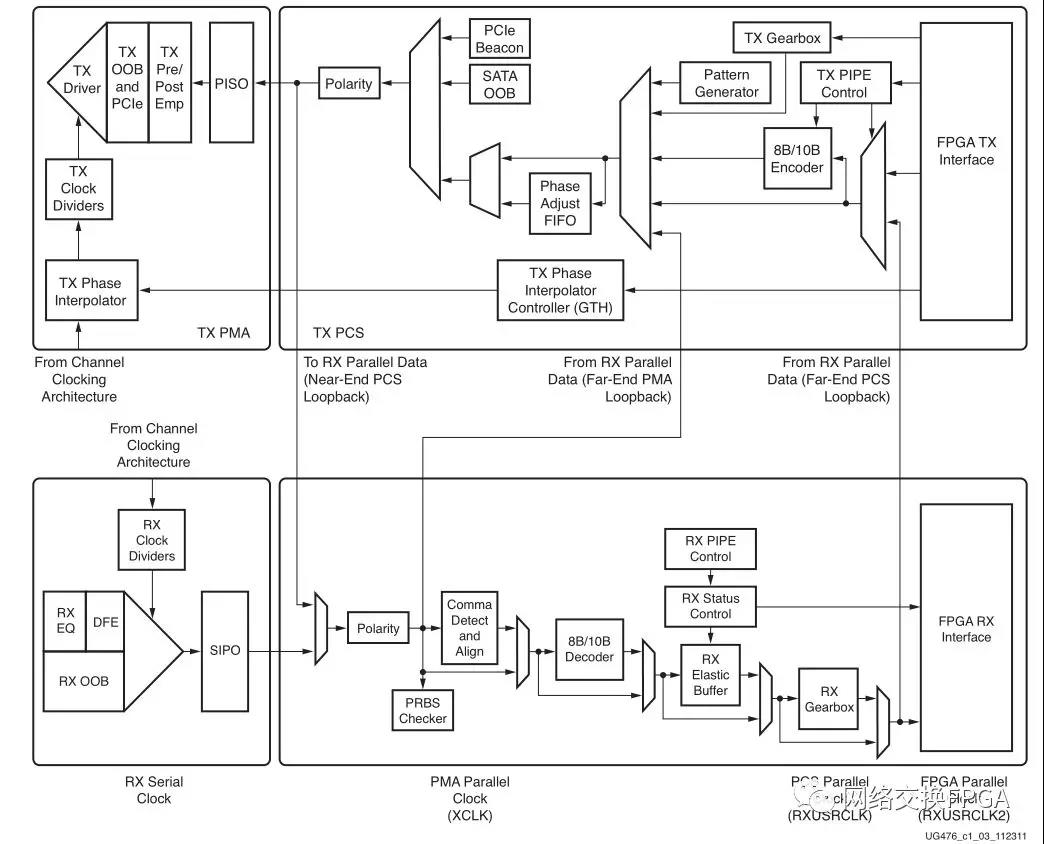
GT接口發(fā)送端處理流程:首先用戶邏輯數(shù)據(jù)經(jīng)過8b/10b編碼后,進入一個發(fā)送緩存區(qū),該緩沖區(qū)主要是PMA子層和PCS子層兩個時鐘域的時鐘隔離,解決兩者時鐘速率匹配和相位差異的問題,最后經(jīng)過高速Serdes進行并串轉(zhuǎn)換。接收端和發(fā)送端過程相反,具體實現(xiàn)可參考ug476_7Series_Transceivers進行學習。
1.2、GT時鐘使用說明
7系列FPGA通常按照bank來分,對于GTX/GTH的bank,一般稱為一個Quad,原因是Xilinx的7系列FPGA隨著集成度的提高,其高速串行收發(fā)器不再獨占一個單獨的參考時鐘,而是以Quad來對串行高速收發(fā)器進行分組,四個串行高速收發(fā)器和一個COMMON(QPLL)組成一個Quad,每一個串行高速收發(fā)器稱為一個Channel,其內(nèi)部結(jié)構(gòu)如圖2所示。
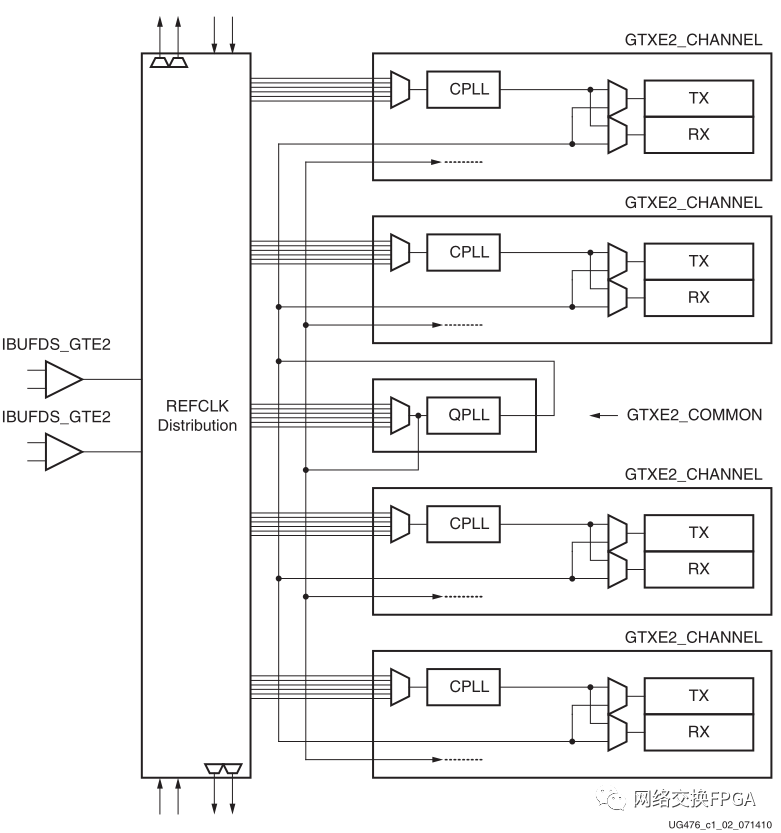
從底層角度看,由于CPLL是每個Channel獨有的,所以CPLL的所有接口都在Channel這個底層模塊中。而QPLL是另外使用了一個叫common的底層模塊。GTX中QPLL和CPLL,除了數(shù)目(每個Quad有一個QPLL四個CPLL)和歸屬(QPLL屬于common,CPLL屬于Channel)不同之外,最大的不同在于支持的最高線速率頻率不同。CPLL最高只有6.xG,而QPLL可以超過10G(具體數(shù)值要根據(jù)器件的速度等級來查詢DataSheet)。
對于7系列的GTX來說,每個Quad有兩個外部差分參考時鐘源,每個外部參考時鐘的輸入必須經(jīng)過IBUFDS_GTE2原語之后才能使用。7系列FPGA支持使用南北相鄰Quad的參考時鐘作為當前Quad的參考時鐘,但是一個Quad的參考時鐘源不能驅(qū)動超過3個Quad上的收發(fā)器(只能驅(qū)動當前Quad和南北方相鄰兩個Quad)。對于一個GTX Channel來說,可以獨立選擇該收發(fā)器的參考時鐘,可以選擇QPLL,也可以選擇CPLL,需要注意的是,每一個Quad上只有一個QPLL資源,重復例化會導致布線報錯。
1.3、GT的主從概念
在我們使用GT 接口IP核時(Aurora和10GEthernet也適用),常提到的主核與從核的說法并不準確,這實際上只是我們在配置IP核時的一個共享邏輯的選項,如圖3所示:
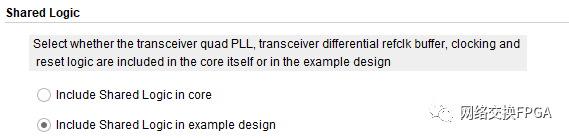
該說明中很清楚的表明,兩個選項分別表示了收發(fā)器的QPLL、時鐘和復位邏輯等是包含在內(nèi)核本身還是示例設計(example design)中,為簡單起見,我們常把共享邏輯包含在內(nèi)核本身的IP稱為主核,內(nèi)核中不包含共享邏輯的IP稱為從核,其結(jié)構(gòu)如下圖4和圖5所示。從核與主核的區(qū)別是:我們可以在Example Design中修改共享邏輯。在實際的設計中,可以使用主核也可以使用從核,但要注意的是,若設計中使用了一個主核后,則其內(nèi)部便使用了該Quad上的QPLL資源,在使用該Quad上的其他GTX接口時,不能再使用主核,也無需再給從核添加共享邏輯。
2、 Aurora接口簡介
2.1、 概述
Aurora 協(xié)議是由Xilinx公司提供的一個開放、免費的鏈路層協(xié)議,可以用來進行點到點的串行數(shù)據(jù)傳輸,具有實現(xiàn)高性能數(shù)據(jù)傳輸系統(tǒng)的高效率和簡單易用的特點。本設計中使用的Aurora 64b66b協(xié)議是一個可擴展的、輕量級的鏈路層協(xié)議,可以用于單路或者多路串行數(shù)據(jù)通信,單路可以實現(xiàn)總線位寬為64bit的數(shù)據(jù)與串行差分數(shù)據(jù)信號之間的轉(zhuǎn)換。
2.2、 信號的連接
上一節(jié)有提到對于高速串行收發(fā)器,每一個Quad里僅可以使用一個QPLL(GTE2_COMMON),在我們生成一個Aurora從核并打開其example design后,這部分共享邏輯就包含在其gt_common_support模塊中,該模塊會產(chǎn)生gt_qpllclk_quad2_out、gt_qpllrefclk_quad2_out等信號供IP核使用,當我們生成一個Aurora主核時,該部分邏輯則包含在IP核內(nèi)部,QPLL會作為輸出信號從IP核輸出。而當設計中需要2個及以上的GTX接口時,則需要將這一共享邏輯產(chǎn)生的信號輸出給所有需要使用的IP核。以主核+從核為例,下圖說明了其部分信號的連接方式:
當使用兩個從核時,上圖連線的這些信號均在example design的共享邏輯中產(chǎn)生,需要人為將其輸入到每一個接口IP中。
2.3、 時序邏輯
2.3.1、 鏈路建立
Aurora通道鏈路初始化完畢后會置位lane_up信號,表明接口可以接收數(shù)據(jù);channel_up拉高時標志接口可以發(fā)送數(shù)據(jù)。一般判斷這兩個信號均置位時認為接口已完成初始化,可以開始進行數(shù)據(jù)傳輸。
2.3.2、 數(shù)據(jù)傳輸
Aurora接口內(nèi)的數(shù)據(jù)傳輸格式如下圖所示:
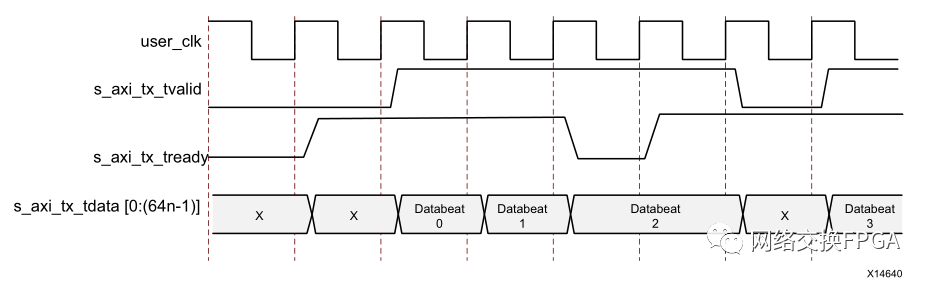
圖7中,s_axi_tx_tready信號拉高時表示已準備好傳輸數(shù)據(jù),該信號由鏈路內(nèi)部的時鐘補償機制決定,不受人為控制,僅當s_axi_tx_tvalid和s_axi_tx_tready兩個信號均被置為1時,才表明該時鐘周期內(nèi)總線數(shù)據(jù)被成功傳輸。
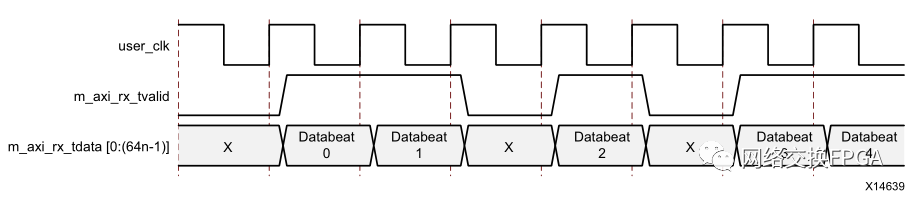
圖8中,m_axi_rx_tvalid表示當前總線上的數(shù)據(jù)有效。
2.4、 接口硬件實現(xiàn)
SERDES是SERializer(串行器)/DESerializer(解串器)。它是一種主流的時分多路復用(TDM)、點對點(P2P)的串行通信技術。即在發(fā)送端多路低速并行信號被轉(zhuǎn)換成高速串行信號,經(jīng)傳輸媒介(連接器、銅線或光纖),最后在接收端高速串行信號重新轉(zhuǎn)換成低速并行信號。這種點對點的串行通信技術充分利用傳輸媒體的信道容量,減少所需的傳輸信道和器件引腳數(shù)目,提升信號的傳輸速度,從而大大降低通信成本。
使用SERDES的好處除了可以最大程度上節(jié)省傳輸線的數(shù)量,還可以兼容板間傳輸和光纖傳輸。無論是通過何種方式連接,都需要使用XILINX的GTP/GTX高速串行傳輸接口。該接口的物理實現(xiàn)方式,是SERDERS,物理層的編碼方式可以選擇Aurora 8B10B或Aurora 64B66B,而應用層可以選擇不同的協(xié)議,也可以不使用。
3、 10G以太網(wǎng)接口
可參考本公眾號之前文章:10G 以太網(wǎng)接口的FPGA實現(xiàn),你需要的都在這里了。
3.1、 概述
10G 以太網(wǎng)包括10GBASE-X、10GBASE-R 和 10GBASE-W。10GBASE-X 使用一種特緊湊包裝,每一對發(fā)送器/接收器在 3.125Gbit/s 速度(數(shù)據(jù)流速度為 2.5Gbit/s)下工作。10GBASE-R 是一種使用 64B/66B 編碼(不再使用千兆以太網(wǎng)中所用的 8B/10B)的串行接口,數(shù)據(jù)流為 10.000Gbit/s。10GBASE-W 是廣域網(wǎng)接口,與 SONET OC-192 兼容,數(shù)據(jù)流為 9.585Gbit/s。本設計中使用的是Xilinx官方開源IP核10G Ethernet subsystem中10GBASE-R模式以太網(wǎng)光接口。
3.2、 時鐘關系
對于FPGA內(nèi)部的時鐘布局主要分為以下4部分:
(a)輸入的差分參考時鐘經(jīng)過一個參考鐘專用緩存(IBUFDS_GTE2)變?yōu)閱味藭r鐘refclk,然后將refclk分為兩路,一路接到QPLL(QuadraturephasePhase Locking Loop),另一路時鐘經(jīng)過一個BUFG后轉(zhuǎn)變?yōu)槿謺r鐘coreclk,繼續(xù)將coreclk分為兩路,一路作為10G MAC核XGMII接口的收發(fā)時鐘(xgmii_rx_clk和xgmii_tx_clk),另一路用于驅(qū)動10G Ethernet PCS/PMA IP核內(nèi)部用戶側(cè)的邏輯。
(b)對于QPLL輸出的兩路時鐘qplloutclk和qplloutrefclk,主要是用于IP核內(nèi)GTH收發(fā)器使用的高性能時鐘,其中qplloutclk直接用于驅(qū)動GTH內(nèi)發(fā)送端的串行信號,其頻率為5.15625GHz。qplloutrefclk用于驅(qū)動GTH內(nèi)部部分邏輯模塊,頻率為156.25MHz。
(c) txoutclk是由10G Ethernet PCS/PMA IP產(chǎn)生的一個322.26MHz的時鐘,該時鐘經(jīng)過BUFG后分為兩路,其中txusrclk用于驅(qū)動IP核內(nèi)GTH的32bits總線數(shù)據(jù),txusrclk2用于驅(qū)動IP核內(nèi)PCS層部分模塊。
(d)在實驗室自研交換板(芯片型號xc7vx690tffg1761-2)上,25MHz的晶振產(chǎn)生系統(tǒng)時鐘輸入到FPGA內(nèi)的PLL(Phase LockingLoop)模塊,PLL模塊以25MHz時鐘為驅(qū)動時鐘生成156.25MHz用戶鐘發(fā)送給10G MAC核用戶側(cè)。
3.3、 IP核配置
Vivado中10G以太網(wǎng) IP核的配置界面如下圖,該 IP 核符合 IEEE802.3-2008標準,包含 MDIO(PHY 管理接口),F(xiàn)CS 處理機制可配置,流量控制等功能。MAC 與 PHY 的接口使用標準 XGMII 接口,其收發(fā)數(shù)據(jù)位寬均為64bit,頻率為 156.25MHz。MAC 核與用戶的接口為 AXI4_STREAM,其數(shù)據(jù)位寬為64bits,工作頻率也為156.25MHz。在shared logic選項卡中選擇了將共享邏輯包含在example design中,也即從核模式。
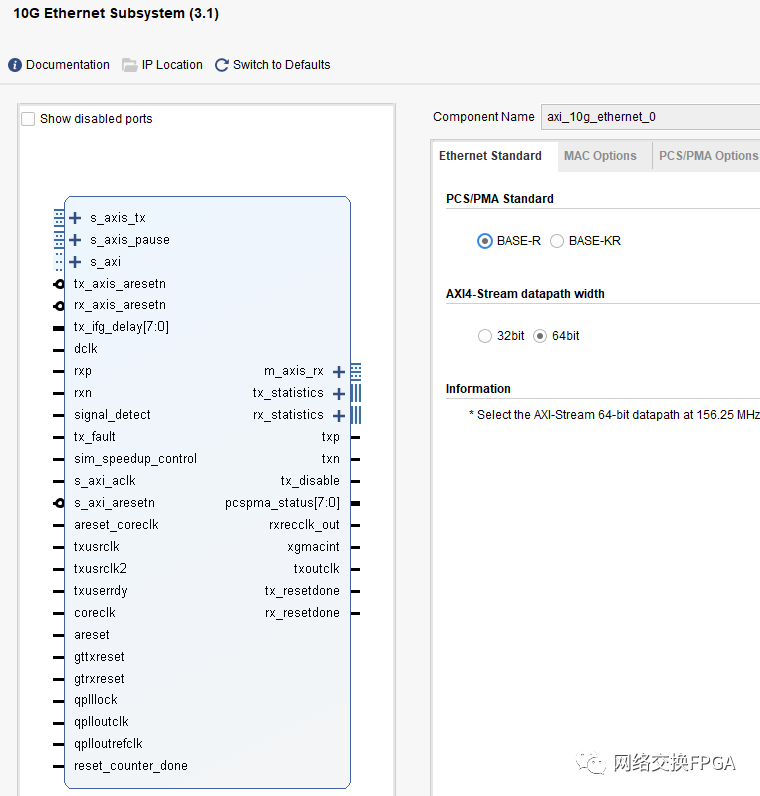
共享邏輯包含一個差分輸入時鐘緩沖器,該緩沖器連接到GT_COMMON塊,該Quad上最多可以有四個10G以太網(wǎng)子系統(tǒng)內(nèi)核共享此邏輯。
使用時鐘緩沖器(BUFG_GT)從收發(fā)器差分參考時鐘創(chuàng)建coreclk / coreclk_out。coreclk / coreclk_out的頻率與差分時鐘源的頻率相同。共享邏輯中的最終BUFG_GT來自GT_CHANNEL的TXOUTCLK,然后又連接到GT_CHANNEL,以提供收發(fā)器TX用戶時鐘(TXUSRCLK和TXUSERCLK2)。使用64位數(shù)據(jù)路徑時,此時鐘的頻率為156.25 MHz;使用32位數(shù)據(jù)路徑時,此時鐘的頻率為312.5MHz。需要注意的是,與IP核直接相連的用戶數(shù)據(jù)應與coreclk對齊,即使本地的用戶時鐘頻率與coreclk頻率相同均為156.25MHz時,也可能因為非同源而導致相位偏差,因此也應采用異步FIFO進行跨時鐘域處理。
3.4、 信號連接
以1個主核+2個從核為例,下圖說明了其部分信號的連接方式:
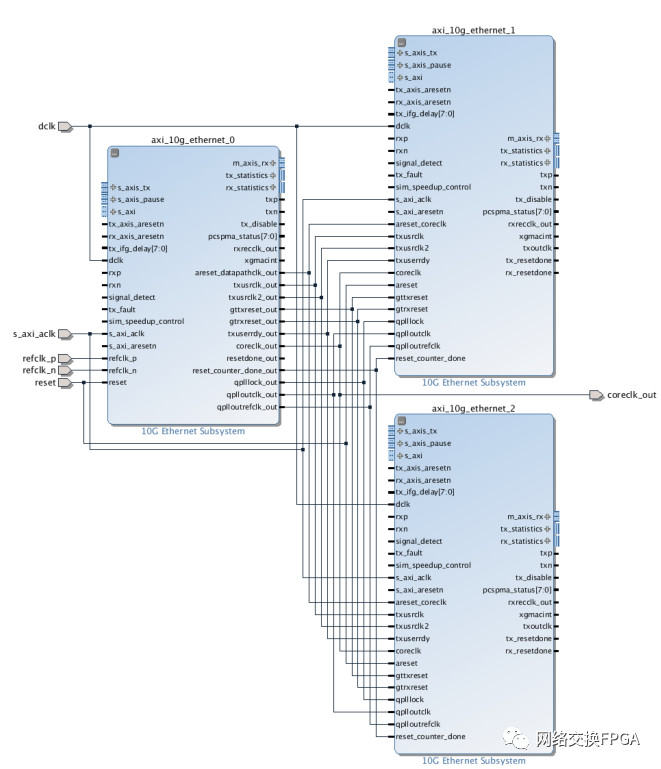
當使用兩個從核時,上圖連線的這些信號均在example design的共享邏輯中產(chǎn)生,需要人為將其輸入到每一個接口IP中。
3.5、 數(shù)據(jù)傳輸
3.5.1、 鏈路建立
10G以太網(wǎng)通道鏈路初始化完畢后會置位core_ready信號,表明接口接口已完成初始化,可以開始進行數(shù)據(jù)傳輸。
3.5.2、 數(shù)據(jù)格式
10G以太網(wǎng)接口用戶側(cè)采用的AXI-Stream總線數(shù)據(jù)格式如下圖所示:
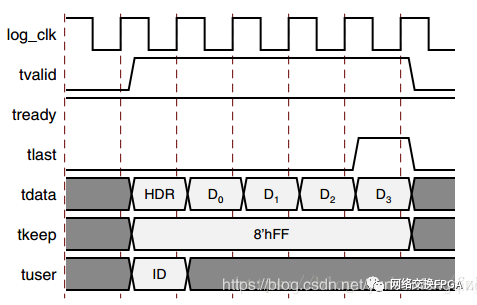
3.6、 接口硬件實現(xiàn)
在遠距離連接的場景中,銅導線已經(jīng)不能滿足如此長距離,大數(shù)據(jù)量的通信,因此必須要采用光纖通信的方案。實現(xiàn)該方案需要使用光模塊。
光模塊是進行光電和電光轉(zhuǎn)換的光電子器件。光模塊的發(fā)送端把電信號轉(zhuǎn)換為光信號,接收端把光信號轉(zhuǎn)換為電信號。光模塊按照封裝形式分類,常見的有SFP,SFP+,XFP等。光模塊的接口是完全兼容XILINX的GTP/GTX IO,接口電路如圖所示:
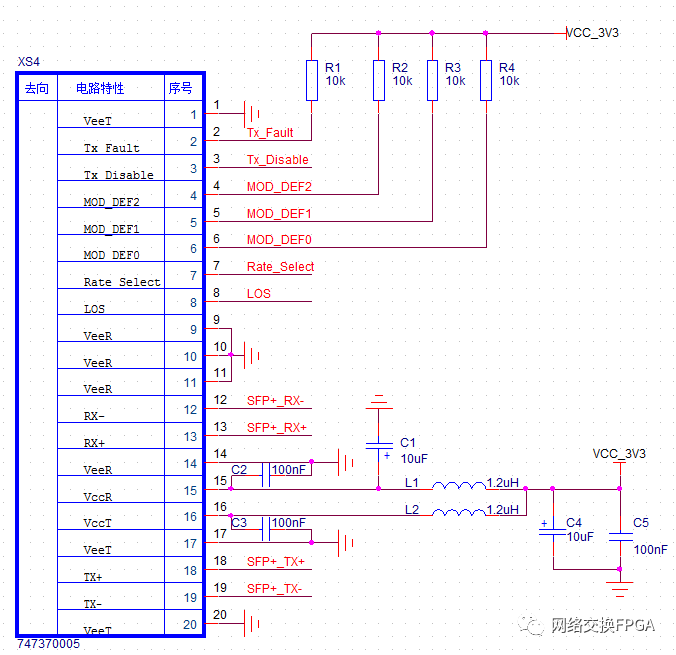
光模塊的種類有很多,下面只針對項目中常見的三種光模塊作介紹。
1)SFP光模塊
SFP光模塊是一種小型可插拔光模塊,目前最高速率可達10.3G(市面上基本為1.25G),通常與LC跳線連接。SFP光模塊主要由激光器構(gòu)成。SFP分類可分為速率分類、波長分類、模式分類。SFP光模塊又包含了百兆SFP、千兆SFP、BIDI SFP、CWDM SFP和DWDM SFP。
2)SFP+光模塊
SFP+光模塊的外形和SFP光模塊是一樣的,傳輸速率可以達到10G,常用于中短距離傳輸。SFP+光模塊是一種可熱插拔的,獨立于通信協(xié)議的光學收發(fā)器。
3)XFP光模塊
XFP光模塊是一種可熱插拔的,獨立于通信協(xié)議的光學收發(fā)器。速率同樣可以達到10G,但是體積比SFP/SFP+光模塊要大。
通過比對分析,SFP+光模塊具有比XFP更緊湊的外形尺寸,比SFP更高的速率,因此在遠距離光纖傳輸中是一種較為優(yōu)秀的方案。
本設計中10G以太網(wǎng)接口在硬件上采用SFP+光模塊實現(xiàn)光電轉(zhuǎn)換。
三、幀結(jié)構(gòu)分析
1、 以太網(wǎng)幀結(jié)構(gòu)
該部分內(nèi)容也可參看本公眾號之前文章:你見過物理層的以太網(wǎng)幀長什么樣子嗎?
目前主要有兩種格式的以太網(wǎng)幀:Ethernet II(DIX 2.0)和IEEE 802.3。本設計使用Ethernet II幀結(jié)構(gòu),其幀格式如圖13所示:

各字段具體說明如下:
⑴ 前導碼(Preamble):由0、1間隔代碼組成,用來通知目標站作好接收準備。
⑵ 目標地址和源地址(Destination Address & Source Address):表示發(fā)送和接收幀的工作站的地址,各占據(jù)6個字節(jié)。其中,目標地址可以是單址,也可以是多點傳送或廣播地址。
⑶ 類型(Type)或長度(Length):這兩個字節(jié)在Ethernet II幀中表示類型(Type),指定接收數(shù)據(jù)的高層協(xié)議類型。
⑷ 數(shù)據(jù)(Data):在經(jīng)過物理層和邏輯鏈路層的處理之后,包含在幀中的數(shù)據(jù)將被傳遞給在類型段中指定的高層協(xié)議。該數(shù)據(jù)段的長度最小應當不低于46個字節(jié),最大應不超過1500字節(jié)。如果數(shù)據(jù)段長度過小,那么將會在數(shù)據(jù)段后自動填充(Trailer)字符。相反,如果數(shù)據(jù)段長度過大,那么將會把數(shù)據(jù)段分段后傳輸。
⑸ 幀校驗序列(FSC):包含長度為4個字節(jié)的循環(huán)冗余校驗值(CRC),由發(fā)送設備計算產(chǎn)生,在接收方被重新計算以確定幀在傳送過程中是否被損壞。
2、Spirent Testcenter業(yè)務流格式
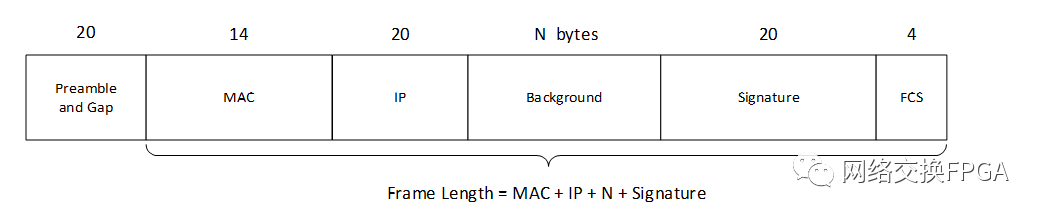
當使用Testcenter配置以太網(wǎng)數(shù)據(jù)幀時,Testcenter會在以太網(wǎng)幀的數(shù)據(jù)字段自動添加20個字節(jié)的開銷,即上圖中的Signature字段,該字段的各部分功能如下:
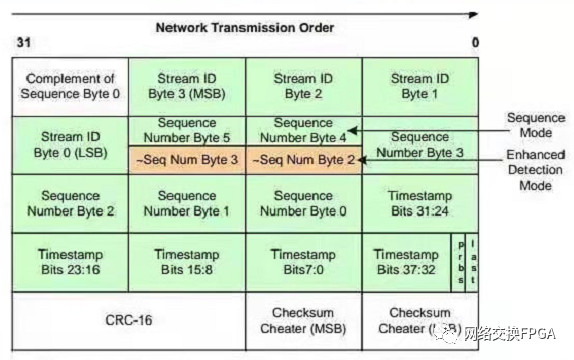
該字段包含32bit(4個字節(jié))的流ID,支持40億個測試流。
該字段具有10納秒的時間戳分辨率
當Spirent Testcenter在有效負載中插入PRBS23碼型時,PRBS位置1
Last位會告訴接收方時間戳所在字節(jié)
該字段具有一個內(nèi)置的UDP / TCP Checksum Cheater字段(用于在有效載荷中放置修飾符時使用)
由于該Signature字段是SpirentTestcenter業(yè)務流的唯一標識,Testcenter通過識別接收到的數(shù)據(jù)流的Signature字段來計算鏈路時延并判斷是否有丟幀的情況,此外,該字段在Testcenter軟件中不對用戶可見,也即我們無法人為的去配置這個字段,因此建議在處理數(shù)據(jù)幀時,不要刪改該字段信息。當然,也可以選擇讓Testcenter不添加這一字段,但是這樣Testcenter在接收到以太網(wǎng)幀之后無法與已發(fā)送的數(shù)據(jù)幀進行比較。本設計選擇的方案是默認在Testcenter業(yè)務流后自動添加Signature字段。
3、 自定義幀格式
本實驗在標準以太網(wǎng)EthernetII幀格式的基礎上重新定義了系統(tǒng)內(nèi)部幀格式,如下圖:
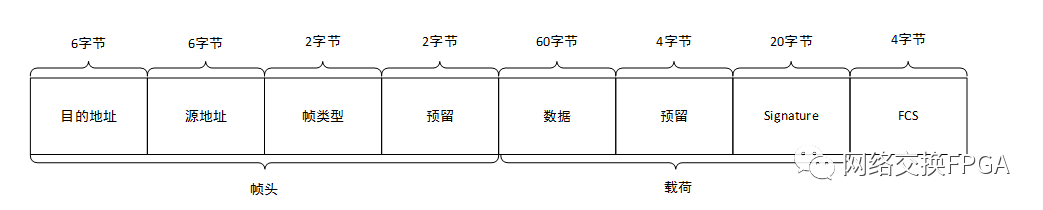
上圖中目的地址、源地址、幀類型和FCS字段均保留了EthernetII幀結(jié)構(gòu),而為了邏輯簡單起見,將數(shù)據(jù)字段重新拆分成四個字段,其中預留字段僅起占位功能,Signature字段為Testcenter自動填充的開銷字段。實驗中真正使用的也就是載荷部分的84字節(jié)。
四、數(shù)據(jù)處理流程
1、 實現(xiàn)方案
1.1整體架構(gòu)
10G以太網(wǎng)接口接收來自Testcenter測試設備發(fā)送過來的以太網(wǎng)幀,提取出關鍵字段將其拆分成并行的12路通道數(shù)據(jù),與clk時鐘同步,然后將這些數(shù)據(jù)進行組包,N個clk內(nèi)的數(shù)據(jù)組合成一幀,使用aurora64B66B將數(shù)據(jù)一幀一幀地發(fā)送出去,接收機對收到的幀數(shù)據(jù)進行解析,并還原成與內(nèi)部clk同步的12路通道數(shù)據(jù),在將12路數(shù)據(jù)合并成以太網(wǎng)幀格式,通過10G以太網(wǎng)接口發(fā)送回Testcenter。實現(xiàn)框圖如下:
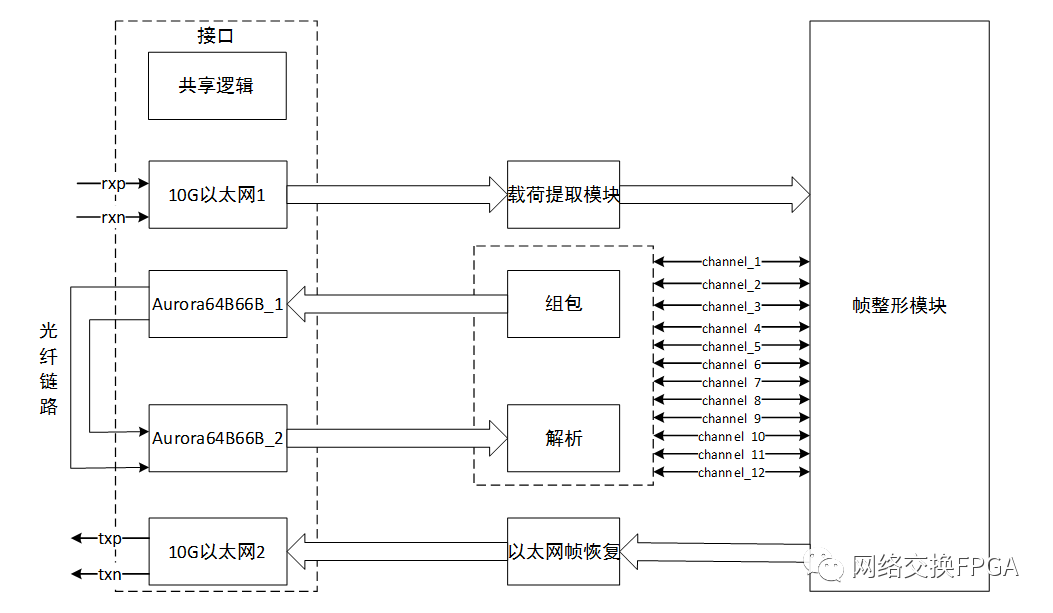
1.2、數(shù)據(jù)流程
根據(jù)上述設計架構(gòu),本設計的數(shù)據(jù)流程如下圖:
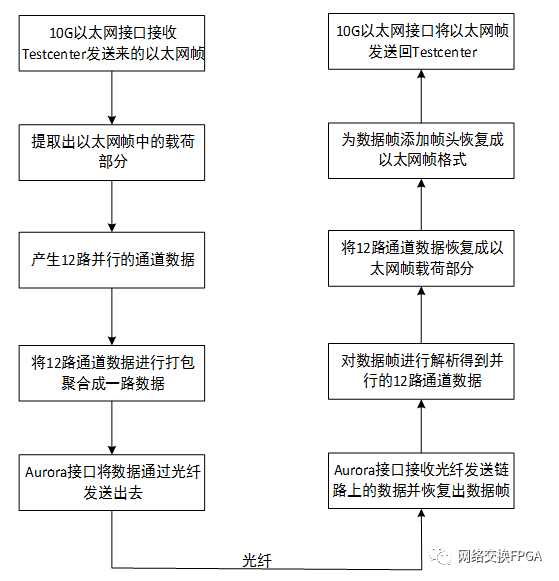
五、主要模塊仿真RTL級驗證
1、 10G以太網(wǎng)接口功能驗證
在10G以太網(wǎng)接口1發(fā)送端寫入64位固定幀,接口將其轉(zhuǎn)換成差分信號輸出,在差分端打環(huán),使接口1發(fā)送出的差分信號進入接口2的接收端,將接收端恢復出的并行數(shù)據(jù)與數(shù)據(jù)源數(shù)據(jù)進行比較。仿真結(jié)果如下圖:
在core_ready信號拉高后向接口1發(fā)送端pkt_tx_*寫入數(shù)據(jù),將接口1與接口2的差分端相連,監(jiān)測接口2接收端pkt_rx_*恢復出的以太網(wǎng)幀。
2、 Aurora64B66B接口功能驗證
在Aurora64B66B接口1發(fā)送端寫入64位固定幀,接口將其轉(zhuǎn)換成差分信號輸出,在差分端打環(huán),使接口1發(fā)送出的差分信號進入接口2的接收端,將接收端恢復出的并行數(shù)據(jù)與數(shù)據(jù)源數(shù)據(jù)進行比較。仿真結(jié)果如下圖:
六、板級驗證
1、 驗證環(huán)境
實驗選取實驗室自研交換板(芯片型號xc7vx690tffg1761-2),該交換板具有6個GTH光口,本設計選取4個光口進行測試,左起1口、4口為10G以太網(wǎng)接口,通過光纖與Testcenter相連,如圖32所示。2口、3口為Aurora64B66B接口,通過光纖實現(xiàn)外環(huán)連接。
2、 測試流配置
在Testcenter配套軟件上配置業(yè)務流時,為直觀的驗證本設計功能,為以太網(wǎng)幀配置payload,即添加custom header,如圖33所示:
3、 驗證結(jié)果
通過Xilinx ila抓取部分信號,從圖34可以看到本設計可以成功的提取出以太網(wǎng)幀的載荷字段,并從中解析出并行的12路通道數(shù)據(jù),前60字節(jié)與6.2中配置字段相同,本設計功能實現(xiàn)良好。圖35中對Testcenter接收到的數(shù)據(jù)幀進行統(tǒng)計并與已發(fā)送的數(shù)據(jù)幀進行比較,表明本設計未出現(xiàn)丟幀、錯幀情況。
七、附錄
下面提供實現(xiàn)本設計的另一種思路:
在前幾章提及GT Quad中QPLL資源的問題,即一個Quad上僅能夠使用一個QPLL,因此本設計使用了四個GTH接口共同使用一個共享邏輯,其QPLL時鐘信號需要驅(qū)動2個10G以太網(wǎng)接口和2個Aurora64B66B接口。對初學者來說,梳理清楚GT時鐘并使用QPLL是具有一定困難的,最簡單的方法是,將4個接口分別放置在兩個Quad上,即每兩個GT接口共享一個QPLL資源,這樣可以直接使用Xilinx官方文檔中的1主帶1從的模式,盡可能的簡化了代碼并大大減少調(diào)試中的困難。
本實驗選擇的交換板上帶有標準FMC擴展口,其上具有豐富的GT資源,下圖展示了FMC擴展板與交換板的連接,以及通過同軸電纜將擴展板上的差分端口相連實現(xiàn)外環(huán)。
編輯:hfy
-
收發(fā)器
+關注
關注
10文章
3438瀏覽量
106076 -
以太網(wǎng)
+關注
關注
40文章
5441瀏覽量
172035 -
高速接口
+關注
關注
1文章
44瀏覽量
14785 -
AURORA
+關注
關注
0文章
25瀏覽量
5400
發(fā)布評論請先 登錄
相關推薦
ADC3561轉(zhuǎn)換成什么數(shù)據(jù)格式便于高速實時通過WIFI發(fā)送?
通過光纖通訊,PXIe可實現(xiàn)與臺式機/工控機的連接

DSP發(fā)送數(shù)據(jù)時通過外擴DA芯片產(chǎn)生4KHZ正弦波,接收時用DSP自帶的AD接收數(shù)據(jù),是不是沒法實現(xiàn)?
光纖器件與技術有關嗎
mpo高密度光纖配線架解析
高速脈沖數(shù)據(jù)采集如何實現(xiàn)

請問如何使用片外SRAM?
萬兆光纖跳線和千兆光纖跳線怎么區(qū)分
基于FPGA的AES256光纖加密設計
請問opencv組件.bss太大了怎么放到片外RAM?
基于 FPGA 的光纖混沌加密系統(tǒng)
mpo線纜就是光纖嗎?
mpo光纖連接器應用哪些方面
線路光纖差動保護的原理和光纖通道具體要求






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論