 基于FPGA技術實現FFShark方案
基于FPGA技術實現FFShark方案
三端口可編程NIC設備,以其與生俱來的結構優勢在各種場景下都可以大顯身手,尤其是在網絡測量和網絡監控領域。在FCCM2020會議上,一篇100G開源的類似于本公眾號之前介紹的1G“網絡監兵”的研究文章(實驗室自研產品介紹:一種多功能的三端口T型轉發器):FFShark: A 100G FPGA Implementation of BPF Filtering for Wireshark,介紹了100G速率下Wireshark的快速FPGA實現FFShark。這種設備對于網絡測量、網絡管理等很多具體的應用具有非常重要的意義,但文中對添加上NIC設備之后對整個網絡造成影響的討論稍顯粗糙。我們結合最近的一些熱點話題可以分析一下。
最近幾天,老美又加大了對華為的約束,幾乎將華為逼上絕路。老美之所以費盡心機的制裁華為,最重要的原因就是以5G為代表的網絡戰略地位的搶奪。網絡,已不僅僅是數據通道,而是能夠傳輸互聯網時代生命之水的渠道。對數據而言,網絡就是上帝。誰主宰了網絡,誰就能夠掌控未來!而華為現在就是能夠修這條新水渠的中國企業,而以前的舊水渠是美國人修的,并且讓特朗普惱火的是,華為修這條新的水渠比他們修的快,還修的好。
網絡的重要,體現在當代生活中的方方面面。比如筆者所在實驗室做的適用于封閉空間的時間觸發以太網TTE網絡就是如此。誰掌握了TTE網絡的規劃,誰就掌管了話語權。網絡在傳遞數據信息之前,需要對整個網絡提前規劃,對整個網絡中的關鍵業務規劃調度表,另外還要求各個網絡節點之間能夠時間同步等等。網絡規劃者必須對整個系統里所有傳感器的每種業務都熟悉。所以,誰規劃了整個網絡,誰就是總管,當然就可以對所有網絡設備以及在網絡通道上的所有信息進行“理所應當”的監控。本文介紹的FFshark就可以做這件事情。
Mellanox Spectrum 4000以太網交換機,每個端口支持400Gbps帶寬,交換容量高達25.4Tbps。首先數據緩沖架構可以測量交換機的整體帶寬,進而可以給每個端口分配一個均衡且可預測的帶寬:其次,無與倫比的虛擬化技術,實現跨超大規模數據中心的VXLAN路由虛擬化;第三,你可以通過全新的WJH(What Just Happened)技術準確掌握最新狀況。
可編程智能NIC,NVIDIA Mellanox Bluefield 2,世界上最先進的可編程智能NIC,以最高200Gbps的線速度加速安全和數據包處理,網絡、存儲和安全協議棧現在被完全分離,運行在這些可編程的智能NIC上,它將成為一個重要的基本數據處理單元。成為未來計算發展的三大支柱之一,CPU負責通用計算,GPU負責加速計算,DPU負責數據中心的數據傳輸和處理。
看完整個演講,筆者認為,其實,基于FPGA的NIC才是最重要的。因為,不管是什么PU,都是先在FPGA上RUN起來之后再去ASIC化的。硬件加速的極限效果,或許是人類下一個PK的目標。用硬件去實現軟件算法,幾塊FPGA板卡的運算能力秒殺傳統的基于CPU軟件的超算或傳統數據中心已經不再是夢。
因此,掌握采用HDL語言來實現交換機和端節點可編程NIC核心功能將成為未來決勝的最核心技術。而老黃手里的NIC設備,如果再增加上第三個端口,則立即可以實現本文所介紹的FFShark。下面我們就一起看一下FFShark這篇文章。
基于Wireshark的調試可以在普通桌面計算機上以1G的速度進行,但只有功能強大的計算機才能跟上10G的速度,在100G時,這種調試幾乎不可能在一臺計算機上進行。
本文介紹了Wireshark的快速FPGA實現FFShark。其結果是一個緊湊的、相對便宜的直通設備,可以插入任何正在運行的100G網絡中。數據包將在FFShark中傳輸,不會中斷,并且附加的延遲最小。開發人員可以隨時向FFShark設備發送標準的Wireshark過濾程序;滿足過濾條件的數據包將被復制并通過單獨的連接發送回開發人員的工作站。
我們展示了我們的開源直通設備比商用100G交換機具有更低的延遲,并且我們的設計已經能夠處理400G的速度。
1. 引言
Wireshark[1]是一個軟件工具,允許網絡開發人員和管理員在不中斷通信的情況下檢查實時網絡數據包。此檢查要求捕獲指定的數據包子集,然后可以分析數據包的相關字段。這種能力對于網絡分析和調試是非常寶貴的。Wireshark的一個主要優點是它使用了BSD包過濾器(BPF),大多數操作系統內核都支持BPF。BPF技術減少了內存復制,并帶來了顯著的性能改進。
高性能處理器可以在10G時進行數據包過濾。當我們移動到100G或更高級別時,使用Wireshark就變得不可能了。例如,第9代Intel i99900KS處理器配備16個PCIe3.0[2]通道,每個通道的最大帶寬為8 Gbps[3]。假設沒有開銷,從NIC到CPU的100 Gbps通信需要16個可用PCIe通道中13個的帶寬。除此之外,如果時鐘速度為5ghz[2],CPU將必須通過PCIe接收數據包,根據用戶的規范對其進行過濾,并且可能以每32位字1.6個或更少的時鐘周期復制數據包。即使CPU以其他方式被卸載并且從未遭受緩存未命中,仍然不可能以這些速度執行必要的篩選。在非常樂觀的假設下,積極的多線程處理可能會使CPU上的100G過濾成為可能,但這是不切實際的,而且無法擴展到更快的速度。

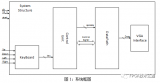
圖1 FFShark的體系結構 圖4中詳細說明了通過部分,圖5中詳細說明了過濾部分
為了使用Wireshark超過10 Gbps的速度,我們建議使用FFShark。 FFShark是一種開源[4],低延遲直通設備,可以放置在網絡中的任意兩個點之間。它支持以PCAP過濾器語法1 [5]編寫的任意過濾器。在調試中,它可用于對100G流量進行全網分析,例如監視兩個交換機之間或數據中心與廣域網之間的所有流量。FFShark的額外延遲成本與交換機相當,從而可以進行實時系統測試。
FFShark使用FPGA技術實現,其中并行的過濾器陣列將監聽數據包數據(圖1)。過濾器被實現為FPGA架構內的CPU,并本地模擬BSD數據包過濾器虛擬機[6]。附加電路將傳入的高速網絡線路分配到多個較低速度的流中,每個過濾CPU一個。FFShark目前可以在真實的100G網絡中執行Wireshark過濾,但是我們將證明FFShark可以以高達400G的速度正確運行(第IV-C節),并且一旦收發器可用就可以立即使用。
本文的其余部分安排如下:第二節提供了Wireshark和BSD包過濾方法的背景討論。第三節介紹了相關工作。第四節詳細介紹了FFShark的設計,包括高速技術和濾波CPU的設計。第五節介紹了實施結果。最后,第六節討論了今后的工作,第七節對論文進行了總結。
2. 背景
在典型的桌面計算機上,所有傳入的數據包都由操作系統內核處理,并復制到正確用戶應用程序的內存中。對于實時網絡調試,用戶應用程序(如Wireshark)請求將數據包也復制到自己的內存中。本節說明Wireshark用于有效復制感興趣數據包的方法;此方法依賴于BSD數據包過濾技術,本節也將對此進行說明。
2.1 Wireshark體系結構
Wireshark允許開發人員從操作系統請求數據包的副本。此外,開發人員可能不希望看到所有數據包,因此Wireshark還允許隱藏不需要的數據包。最簡單的實現是將每個數據包復制到Wireshark的內存中,Wireshark僅顯示感興趣的數據包。一個更有效的解決方案是首先避免復制不需要的數據包。

圖2 標準Wireshark操作
圖2說明Wireshark如何在標準操作系統環境中操作。開發人員以PCAP語法[5]輸入過濾器規范。例如,表達式tcp src port 100僅選擇源自端口100的tcp包。Wireshark將此表達式編譯為BPF機器代碼(在下一小節中描述),并使用內核系統調用安裝篩選器代碼。到達網卡的數據包由內核數據包處理通過套接字定向到相關的用戶應用程序。此外,所有數據包都被復制到BPF過濾器,與過濾器代碼描述的過濾器匹配的任何數據包都被復制到Wireshark的用戶內存中。
2.2 BSD包過濾器(BPF)
BPF方法源自以下觀察結果:“盡早就地過濾數據包會得到回報” [6]。使用這種方法,用戶提交一個BPF程序,內核將在每個傳入的數據包上執行該程序。這些程序是由OS內核中的仿真器執行的一系列機器代碼指令。任何與Wireshark兼容的操作系統都有責任正確模擬BPF計算機。內核只會根據BPF程序的返回值將數據包復制回用戶。
BPF機器的簡要概述如下。有兩個32位寄存器:累加器(A)和輔助(X)。該處理器對整個數據包(包括標頭)具有字節可尋址的只讀訪問權限,對小型暫存存儲器具有讀/寫訪問權限。一條指令由其類(表I),尋址模式,跳轉偏移和立即值定義。BPF指令布局如圖3所示。
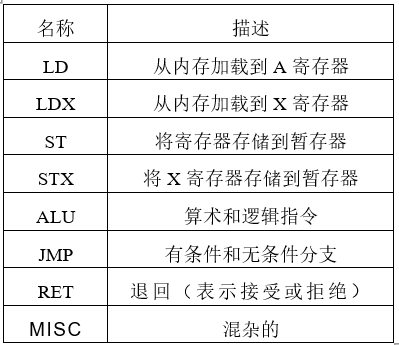
表1 BPF指令類

圖3 BPF指令布局。數字是位索引
3. 相關工作
Campbell和Lee[7]實現了一個僅使用普通硬件的100G入侵檢測系統(IDS)。使用100G路由器將數據包均勻地分發給多臺工作機[8]。為了進一步減少單個機器上的負載,中央管理節點可以允許某些類型的流量在確定安全后繞過IDS。這個IDS的體系結構需要一個100G負載均衡器和幾個高性能CPU機器的操作。這樣做的優點是使用立即可用的零件,但不具有成本效益。
有許多商用100G網卡和交換機實現了對硬件包過濾的支持,每個網卡和交換機都提供自己的專有API。nBPF[9][10]可以將簡單的PCAP表達式轉換為這些特定于供應商的格式,但根據特定NIC支持的操作,只能翻譯有限的表達式子集。在nBPF利用商用100G硬件的過濾能力的地方,FFShark本機實現完整的BPF標準,作為一個單獨的設備,可以插入到任何位置的網絡中。這滿足了我們保持與Wireshark完全兼容的目標。
另一種類型的100G數據包過濾涉及根據高層過濾器描述自動生成FPGA設計。這種方法利用了FPGA的高性能和可重新配置性,但是旨在滿足希望使用簡單數據包過濾規范的系統管理員的需求。Xilinx netCope [11]根據P4過濾器規范[12]生成VHDL。此外,更高級的綜合技術可以使開發人員編寫自己的數據包過濾算法并在FPGA上實現。這些方法幾乎沒有支持交互地更改過濾器規格的方法。FFshark是符合標準BPF接口的FPGA覆蓋層,在更改過濾器時不需要生成新的FPGA配置。
FMAD Engineering提供了一種持續的100G數據包捕獲解決方案[13]。該產品是具有兩個QSFP28輸入端口和十個SSD的陣列的機架式盒子。設備接受BPF過濾器并保存接受的數據包以供以后查看。FMAD是一種商業產品,支持與FFShark相同的過濾功能,并且可以以高達100G的速度運行。但是,FFShark是開源的,可供社區自定義和用于實驗。FFShark還顯示可在400G網絡中使用。
Bittware生產具有包過濾功能的封閉源10/25/40/100G包代理設備[14]。這是具有四個QSFP28端口的PCIe擴展卡。對于過濾,它支持10G速度和過濾器參數的運行時配置,這些參數可以從PCAP過濾器表達式合成。通過更改FPGA映像,可以將解決方案升級為支持100G過濾,而無需其他硬件。該Bittware產品的說明說,它支持“一組行業標準的PCAP ASCII表達式”,這意味著它不具備BPF引擎的全部靈活性,例如FFShark。同樣,就像剛剛描述的FMAD產品一樣,Bittware產品是一種商業產品,而FFShark則具有開源和為400G速度做好準備的優勢。
4. 設計
圖1顯示了FFShark的概述。該設計包括一個直通扇區(圖4)和一個過濾扇區(圖5)。使用Xilinx Zynq Ultrascale + XCZU19EG-FFVC1760-2I(MPSoC)來實現FPGA和ARM組件[15]。篩選扇區本身分為三個子組件:斬波器,多個BPF核心和轉發器。斬波器將高速輸入數據分為幾個以較低速度運行的隊列。每個隊列都饋入一個BPF Core,后者執行一個BPF過濾程序。最后,如果數據包被接受,則轉發器將其發送出過濾器。這些子組件中的每一個都在下面的單獨小節中詳細介紹。
4.1 直通扇區

圖4 直通扇區的設計
直通扇區如圖4所示。Ultrascale+器件中經過100G加固的CMAC提供了稱為LBUS的本地總線接口。由于所有其他Xilinx內核都使用AXI,因此LBUS到AXIS轉換器電路[16]將PHY層的原始信號轉換為標準AXI流消息,反之亦然。AXI Streaming通道連接在一起,允許所有消息直接轉發到相對的端口。

圖5 過濾部分的設計
兩個QSFP28收發器的時鐘速度約為323 MHz,但由兩個獨立的時鐘驅動。因此,需要其他邏輯將消息從一個時鐘域轉換到另一個時鐘域。盡管使用的時鐘略有不同,但兩個收發器的額定工作頻率均為100G,并且在業務突發之間存在間隙的情況下,可以維持此數據速率。添加了FIFO緩沖以允許這些隨機的短期突發。
直通流量通過AXI流通道發送。構成此通道的連線也直接送入斬波器,從而使其能夠觀察到任何通過的通訊。
4.2 斬波器
過濾扇區旨在允許用戶指定任何過濾器(即BPF程序)。由于指令的數量(因此,程序運行時間的長度)事先未知,因此我們允許用戶在多個并行BPF內核之間分配任務,如圖5所示。為此,我們實現了一個帶有一個Chopper的Chopper。每個數據包過濾器一個輸出隊列。這也使我們能夠以較低的頻率為BPF CPU提供時鐘,從而大大減輕了復雜結構的FPGA編譯負擔[17]。
這種架構為我們提供了向上擴展的巨大余地。BPF內核具有最大可操作比特率;即使如此,當到400G速度時,斬波器也可以很容易地重新配置,以將輸入比特率分配到大量的較慢輸出隊列中。
斬波器在HLS中實現如下。單個AXI流輸入接收數據包。該輸入的時鐘頻率最高可達475 MHz,并且對輸入通道的數據寬度沒有限制。一個仲裁器,基于檢測到前向擁塞和緩沖區使用情況的探測器,并根據其最近的歷史上發送的前幾個數據包的位置,為每個數據包選擇一個輸出流,使每條輸出線的平均比特率保持在指定的量以下。決策邏輯與交叉開關分開,讓斬波器有一個較小的關鍵路徑。輸出決策基于四個周期的信息。但是,由于我們有足夠的輸出緩沖來容納至少一個數據包加四個濾波器,因此不會影響可靠性。數據包被認為是不可分割的;來自輸入流的整個數據包被發送到相同的輸出流,其中數據被緩存在FIFO存儲器中。第二條電路從該FIFO存儲器中讀取數據,并將其作為具有適當時鐘速度和通道寬度的AXI流信號輸出,以支持BPF Core的最大比特率。
斬波器的仲裁部分將每條輸出線上的平均比特率設置為50 Gbps。但是,數據包的不可分割性要求斬波器使用165 Gbps的間歇性突發(在322MHz時為512位寬的信號)來完成此任務。出于這個原因,數據需要進行緩沖,因為BPF內核無法支持超過51.2Gbps的突發。為防止該FIFO緩沖區溢出,將容量設置為足夠大以緩沖兩個最大數據包(3kB或18kB,啟用巨型數據包)。即使尚未完全讀取數據包,緩沖區也可以接受整個新數據包。使用大小范圍從64B到9kB的隨機分組進行的測試表明,當平均輸入比特率保持在100 Gbps時,不會丟失任何分組。
仲裁器能夠不考慮網絡流量的組成(即,大小分組的分布)而工作。然而,并行方法可能會導致數據包被記錄得不整齊。為了解決這個問題,每個傳入的包都會記錄一個時間戳(基于全局FPGA時鐘計數器),并將其添加到報頭。目前,軟件可以執行包的重新排序任務,但是,在硬件中進行包的重新排序更為可取。一種選擇是完全刪除時間戳,而改為修改斬波器和轉發器,使數據包從不出差錯;這將具有最低的額外FPGA資源成本,并且只會遭受最大吞吐量的小損失。或者,一個通用的重排序緩沖器將以顯著增加片上存儲器成本為代價來保持最大吞吐量。這些進展留作今后的工作。
4.3 時鐘
直通扇區在每個方向上使用一個時鐘為322 MHz的512位AXI流通道。每個通道支持的最大比特率為164 Gbps(322 MHz時為512b)。斬波器以全速監聽此通道,并輸出幾個流,這些流以100 MHz的時鐘速度運行,總線寬度為512位,比特率為51.2 Gbps,這是BPF內核可接受的速度。每個BPF內核都能夠以51.2 Gbps的相同速率輸出接受的數據包。
目前,我們沒有可用的400G硬件。但是,我們使用內部生成的隨機數據包信號進行了400G Chopper測試,該數據包的大小在40至9000字節之間,時鐘頻率為450MHz。總線寬度為1024位寬,最大位速率為460.8G。即使在這種比特率下,斬波器也能夠將輸入正確地分為51.2 Gbps的九個輸出信號(100 MHz的512位總線),而不會丟包。
4.4 BPF核心
當前,Wireshark依靠OS內核從網絡硬件接收數據包,并基于任意BPF程序執行過濾。如第一節所述,即使功能強大的CPU機器也無法在100G時執行這些任務之一。FFShark將過濾操作從OS內核轉移到100G網絡中嵌入的直通設備,并使用稱為BPF內核的并行處理器陣列執行過濾(圖5)。

圖6 BPF核心
每個BPF內核都配備了自己的指令存儲器和數據包存儲器,如圖6所示。來自斬波器的每個數據包都被復制到BPF內核的數據包存儲器中。每個內核的指令存儲器可以在運行時通過外部配置總線加載BPF程序,該BPF程序將針對接收到的每個數據包執行一次。程序使用RET指令使BPF內核發出接受或拒絕信號。接受后,轉發器(第IV-G節)會將數據包發送到外部存儲。
BPF CPU由一個數據路徑和一個控制器組成。圖7中詳細顯示了數據路徑。控制器通過三個階段進行流水線處理:獲取,執行和寫回。最后兩個階段通過控制信號線控制數據路徑,并支持除MUL,DIV和MOD(實際過濾應用中很少使用)之外的所有BPF操作。有四個未連接到數據路徑的控制信號:inst_rd_en和pack_rd_en信號直接連接到它們各自的存儲器,并且cpu_acc和cpu_rej用于向Ping-Pang-Pong互連發送信號,如第IV-F節所述。數據路徑通過其inst_rd_data線連接到指令存儲器,并通過其pack_rd_addr和pack_rd_data線連接到分組存儲器。圖7中的所有其他連線都是內部的,請勿離開模塊。
4.5 并行BPF核數的選擇
斬波器必須在具有最大可操作比特率的多個并行BPF內核之間分配輸入流。但是,如果BPF程序很長和/或BPF內核被過多的小數據包淹沒,則每個內核的有效比特率會降低,并且需要更多的比特率來支持100G帶寬。
本小節將提供一種用于估算所需并行核數的通用技術,以及一個正在運行的示例,如清單1所示。此清單顯示了tcp src端口100 PCAP過濾器表達式產生的BPF指令。對于我們正在運行的示例,我們假設20%的輸入數據包既不使用IPv4也不使用IPv6,30%的數據包使用IPV4和UDP,25%的數據包使用IPv4和TCP,但不是來自源端口100,而25%的數據包 使用IPv4和TCP,并且來自源端口100。對于我們的示例,平均數據包長度將為680B。
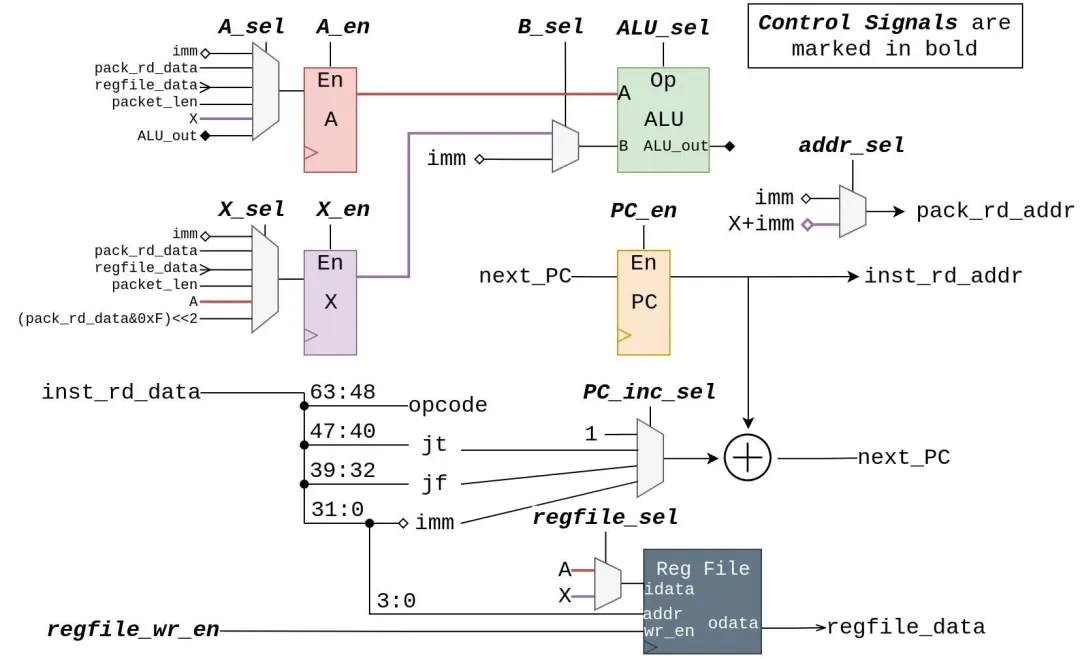
圖7 BPF CPU數據路徑

清單1 為PCAP篩選器tcp src端口100編譯的BPF機器代碼
通常,包的輸入流可以分為k個不同的類,其中每個類在過濾器代碼中觸發相同的執行路徑。在我們的運行示例中,k =4。類i中的每個數據包均具有長度為Ii的指令的代碼路徑,并且具有平均長度的中斷。最后,隨機選擇的輸入分組具有屬于類別i的概率Pi。表II中顯示了運行示例的Ii,li和Pi的值。
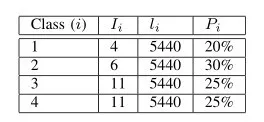
表2 i,li和Pi值,用于運行第IV -E節中的示例
對于這些計算,我們將假設BPF CPU每條指令需要四個周期,即CPI =4。如果CPU以時鐘周期T秒運行,那么BPF CPU(RCPU)的平均比特率為:

公式1中的分母表示CPU處理單個數據包所需的時間(以秒為單位)。
RCPU代表BPF CPU的比特率。但是,要選擇正確數量的BPF核心,請計算RCore,即BPF核心的比特率:

其中512位×100 MHz表示可用于填充BPF核心的分組存儲器的最大比特率(c.f.第IV-c節)。
因此,所需的并行BPF核心數是N =“100G/RCore”。在我們的示例中,RCPU=19.8G,因此RCore=19.8G,N=6。在實際應用程序中,FFShark用戶必須根據對正在調試的系統的了解,對k、Ii、li和pi進行有根據的猜測。
一般來說,我們已經發現六個并行核心足以用于常見的過濾器,例如選擇所有到/來自特定地址或端口范圍的數據包。更復雜的濾波器可能需要更多的BPF核,并且應該完成所描述的估計所需數量的過程。然而,即使當一個過濾器變得更復雜時,過濾器代碼也能夠在被拒絕的包上提前終止,而被接受的包的比例通常會降低。考慮表3所示的例子:這個例子為一個過濾器建模,其中有更多的條件應用于與我們前面的例子相同的流量模式。具體來說,過濾器檢查包含數據的任何HTTP包。類1和類2仍然被提前拒絕,類4在被拒絕之前需要另外兩條指令。然而,類3分為兩類:3a是通過新過濾器的某些條件但最終被拒絕的包,3b是通過所有條件的包。即使接受包的指令數要大得多,在本例中,所需的并行核心數仍然是6。

表3 Ii、li和PiVALUES用于過濾器TCP端口80和((IP[2:2]-((IP[0]&0XF)>2))!=0)
4.6 乒乓控制器
BPF內核是一個BPF CPU,配備了一個指令存儲器和一個數據包存儲器(圖6)。立即我們注意到,包內存在三個代理之間共享:斬波器,BPF CPU和轉發器。一個重要的性能優化是“乒乓球”緩沖區,如圖8所示。此方案使所有三個代理可以同時全速訪問內存。

圖8 乒乓緩沖區
自定義互連維護三個fifo,表示每個代理的作業隊列。在任何給定時刻,多路復用器都會使用代理隊列頭部的令牌將代理與Ping、Pang或Pong緩沖區之一連接。
圖9展示了實際的技術。左上角的塊表示作業隊列的初始狀態,可以理解為“所有三個緩沖區都在等待斬波器讀取數據包,斬波器當前連接到Ping緩沖區”。當斬波器完成將數據包讀入Ping緩沖區時,Ping令牌將從斬波器隊列中彈出并添加到CPU隊列(右上角塊)。此時,斬波器現在連接到Pang緩沖區,CPU開始在Ping緩沖區中處理數據包。左下角的塊顯示了如果斬波器在CPU完成其程序執行之前讀取完數據包會發生什么情況:Pang令牌從斬波器隊列中彈出并添加到CPU隊列中。右下角的圖顯示了CPU接受數據包的結果:Ping令牌從CPU隊列中彈出并添加到轉發器隊列中。

圖9 乒乓球互連中的作業隊列
4.7代理
接收到數據包后,BPF核心將Ping,Pang或Pong緩沖區之一放在轉發器的工作隊列上。然后,轉發器從緩沖區讀取并在512位寬的AXI流(以100 MHz輸出)上輸出數據包數據。
如果目標FPGA器件配備了三個(或更多)QSFP28端口,則可以重新組合接受的數據包流并以全100G速率發送出去。這項工作中使用的FPGA只有兩個QSFP28端口,但是具有到連接的ARM CPU的高帶寬通道。
從Vega等人的工作中借鑒[18],擴展了它們的協議,實現了FPGA與ARM處理器之間的雙向消息傳輸。使用該方案,我們能夠連接來自BPF核心的已接受數據包并將其轉發到ARM核心。還添加了一個頭,以允許一些元數據隨數據包一起傳輸。一旦進入ARM核心,就可以根據需要處理消息。出于功能目的,初始測試將過濾后的消息打印到ARM處理器的終端上。為了更實際的實現,單獨開發的存儲系統[19]允許我們可靠地、低開銷地將收集到的消息存儲到遠程存儲服務器。該系統可同時供FPGAs和cpu使用。然而,由于我們缺少第三個網絡端口,數據包被轉發到ARM以使用ARM的網絡端口。
為了將這個通道用于接收的數據包流,我們為轉發器構建了一個自定義數據寬度轉換器,該轉換器將時鐘保持在100MHz,但將總線寬度減小到64位(比特率為6.4 Gbps)。對于ARM處理器而言,這足夠慢以接收接受的數據包。如果接受的數據包的帶寬超過了此6.4 Gbps瓶頸的速度,則“過濾扇區”將丟棄數據包,但“直通扇區”不會受到影響。
5. 結果與討論
對于這些結果,FFShark系統在Zynq Ultrascale + XCZU19EG-FFVC1760-2-I上實現[15]。該芯片在同一硅芯片上包括FPGA和ARM CPU。兩者可以通過幾個高速AXI通道進行通信。FPGA具有110萬個邏輯元件和9.8 MB的片上存儲器。該處理器是64位ARM Cortex-A53。該芯片是Fidus Sidewinder 100 [15] FPGA板的一部分,該板將MPSoC連接到兩個QSFP28 4x25G端口,一個1G以太網端口以及許多其他外設。
為了表征FFShark的性能,我們收集了三種測量方法:增加的直通業務延遲、包丟棄率、濾波器和直通扇區的性能以及設計所需的FPGA資源數量。
5.1 插入延遲
此測試的目標是測量lP,即FFShark的passthrough扇區的插入延遲,定義為數據包在一個QSFP端口上進入另一個QSFP端口上離開所用的時間。圖10概述了測試設置。圖中的每個灰盒代表一個側板,每個連接都是2 m 100G電纜。UDP被選為具有一致延遲的輕量級可路由協議,可以從總延遲中減去。

圖10 延遲測量的測試設置
測量了直接連接的往返時間,如圖10a所示。此數量用LD表示,并表示數據包到達以下狀態所花費的時間:
1)100G UDP內核進行處理[16]
2)穿過2 m的電纜(lC)
3)進入和退出環回
4)傳遞通過2 m的電纜。
5)返回流量生成器后,由100G UDP核心進行處理。
當數據包發送到UDP核心時(步驟1),以及數據包返回后離開UDP核心時(步驟5),流量生成器板都會保存時間戳。
接下來,如圖10b所示,測量包括FFShark的往返時間。該數量用LP表示。

表4 直接連接和通過測試的往返時間
表IV列出了各種數據包大小(包括36字節UDP報頭)的LD和LP的測量值,連續100G傳輸中平均超過4000個數據包。給定通過銅電纜的傳播速度,發現2 m電纜的傳播延遲lC為0.009μs[20]。圖11示出了計算值lP =(LP-LD-2·lC)/ 2。用Dell Z9100-ON 100G交換機代替FFShark進行了類似的測試,如圖10c所示。在圖11中還示出了該交換機ls的測量的插入等待時間,以呈現FFShark和商品100G硬件之間的比較。請注意,該交換機不支持大于MTU限制1.5KB的數據包。

圖11 FFShark(LP)與Dell Z9100-ON 100G交換機(LS)的插入等待時間
小于100字節的數據包記錄了更高的延遲。這是由于我們的測試超出了第V-D節中所述的小數據包的最大數據包速率。當比特率降低時,大小為100字節或更小的數據包的插入等待時間大約等于164字節大小的數據包的測試等待時間(約0.3μs)。此外,FFShark的延遲隨著數據包大小的增加而增加。目前,我們正在使用Xilinx CMAC控制器,這迫使我們存儲和轉發整個數據包,而不是使用直通方法。
5.2 最高性能
為了測試最高性能,通過FFShark以全100G比特率將32768個數據包(大小從16B到1500B)發送到回送設備,并在原始位置重新收集。原始設備驗證了數據包的完整性,并計算了丟失或損壞的數據包的數量。在此高度擁塞的應用程序中,正確返回了99.41%的數據包。沒有數據包被返回損壞。修改測試以測試大小在176B到1500B之間的數據包時,沒有數據包被丟棄。V-D節探討了這些數據包丟棄的來源。可以添加握手或流控制來減輕這些數據包丟失。
已顯示直通扇區和過濾扇區永遠不會丟失數據包4。通過多次運行測試來證明這一點,在該測試中,具有唯一標頭的單個數據包被隱藏在100G流量突發中的不同位置。對數據包過濾器進行編程以檢測簽名。在所有情況下,FFShark都能正確識別數據包并將其轉發給ARM,而忽略所有其他數據包。
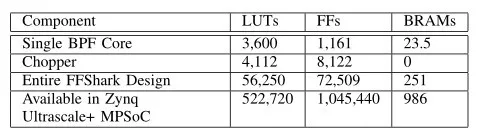
表5 FFSHARK和所選子組件的資源使用
5.3 資源使用
表5顯示了該項目的資源使用情況。前兩行顯示單個BPF Core和Chopper的資源使用情況。第三行顯示了最終FFShark設計的全部成本;該表包括六個BPF內核,一個斬波器,以及直通扇區以及將指令存儲器和轉發器與板載ARM CPU接口所需的額外邏輯。此設計中未使用DSP。由于此設計僅使用FPGA總容量的一小部分,因此剩余資源可用于添加更多的過濾核心,或將FFShark嵌入更大的設計中。或者,可以將FFShark放置在更小,更便宜的FPGA上。
5.4 討論
在包含小于176B的數據包(100G比特率)的測試中,發現了高延遲和偶爾的數據包丟棄。已經發現,FPGA上的100G CMAC和收發器具有每個數據包的開銷[21],除了最大比特率約束之外,還創建了最大數據包率約束。在使用小數據包的測試中,每秒的數據包數超過了此最大值,并且網絡硬件開始施加反壓。GULF流UDP內核具有內部緩沖區,可以暫時緩解此問題。然而,隨著這些緩沖區的填滿,數據包的積壓意味著等待時間線性增加,導致在較小的數據包大小下出現高等待時間,如第V-A節所示。最終,GULF流FIFO完全填滿,導致在V-B節中看到的基于擁塞的數據包丟失很少。對于較小的數據包大小,當降低比特率時,對于所有數據包大小,數據包丟棄都會停止,并且延遲遵循相同的趨勢。
除了基于硬件的限制之外,FFShark的性能達到了預期的目標,與高端100G交換機相比,它增加了更小的延遲,并且不影響數據包數據。當不超過轉發器的帶寬時,篩選器可以檢查100%的傳入數據包。
總體設計僅占用FPGA資源的不到四分之一,并且Chopper能夠以400G的速度正確分配輸入流。當MAC /收發器支持可用時,這會使FFShark立即擴展到400G。
6. 未來的工作
這項工作具有廣闊的發展前景,因為它可以擴展到各種速度,并且用途廣泛。雖然在這種情況下,它用于交互式分析網絡流量,但可以通過修改直通扇區來調試任何類型的數據通信。例如,PCIe信號也可以轉換為AXI流,并以類似方式進行[P1] 觀察。FFShark還可以用于監視和調試FPGA設計中的常規信號。
尋找和是否可以修改BPF語言以更好地用作交互式調試工具是一個研究問題。例如,eBPF[22]在Linux內核中用于跟蹤文件系統調用,創建I/O傳輸的直方圖以及其他高級調試任務。并非eBPF支持的所有功能都能很好地映射到FPGA實現中,但是共享內存模型對于以100G的速度收集全局統計信息至關重要。
BPF Core是可以接受任意程序的處理器。盡管通用統計信息易于收集,但我們希望為用戶創建一種方法,以編程新類型的測量并讓該系統報告實時值。然后,SDN應用程序可以使用這些自定義統計信息來改進路由和其他決策。
當前這項工作與Wireshark兼容,因為它使用相同的BPF機器代碼并返回相同的結果。但是,需要一些工作才能將其與Wireshark代碼庫集成在一起,以便可以使用熟悉的Wireshark GUI和實用程序。這可以通過創建一個自定義OS網絡驅動程序來完成,該驅動程序將篩選器程序傳輸到FFShark,而不是在內核中執行它們。
7. 結論
我們創建了一個工作在100G的直通設備,可以對其進行編程以標記和存儲觀察到的數據包的子集。該子集使用PCAP過濾語言指定,允許用戶繼續使用熟悉的語法。該器件還被證明可以在全100G的速度下運行而不會丟包,并且一旦收發器和FPGA網絡支持可用,它就可以立即擴展到400G。與商用100G交換機相比,該設備為網絡數據增加了400ns的延遲。由于網絡設計期望延遲在此范圍內,并且FFShark不會顯著改變環境,因此這證明它可用于實時環境中的調試。
8. 致謝
M.A.Merlini和J.C.V.ega是這項工作的同等貢獻者。作者們要感謝匿名評論者的深刻反饋。我們感謝Edward S.Rogers高級電氣和計算機工程系、安大略大學研究生獎學金、華為、Xilinx和NSERC的資助。最后,我們感謝Xilinx和Fidus系統捐贈芯片、工具和支持。
9. 參考文獻
[1] Wireshark, “Wireshark User’s Guide Version 3.3.0,” 2018, https://www. wireshark.org/docs/wsug html/.
[2] Intel, “Intel Core I9 9900KS processor speci?cations,” 2019, https://www.intel.ca/content/www/ca/en/products/processors/core/i9-proce....
[3] PCIe-Consortium, “PCI Express? Base Speci?cation Revision 3.0,” PCIe Group, pp. 1–860, 2010, http://www.lttconn.com/res/lttconn/pdres/ 201402/20140218105502619.pdf.
[4] M. Merlini and C. Vega, “A versatile Wireshark-compatible packet ?lter, capable of 100G speeds and higher,” 2020, https://github.com/ UofT-HPRC/fpga-bpf.
[5] V. Jacobson, C. Leres, and S. McCanne, pcap-?lter(7) - Linux man page, Lawrence Berkely National Laboratory.
[6] S. McCanne and V. Jacobson, “The BSD Packet Filter: A New Archi- tecture for User-level Packet Capture.” in USENIX winter, vol. 46, 1993.
[7] S. Campbell and J. Lee, “Prototyping a 100G monitoring system,” in 2012 20th Euromicro International Conference on Parallel, Distributed and Network-based Processing.IEEE,2012,pp.293–297.
[8] V. Paxson, “Bro: a system for detecting network intruders in real-time,”Computer networks, vol. 31, no. 23-24, pp. 2435–2463, 1999.
[9] A.Cardigliano,“PF-RING-nBPF,”92019,https://github.com/ntop/PFRING/tree/dev/userland/nbpf.
[10] D. Luca, “nBPF,” Sharkfest Europe, pp. 26–37, 2016, https:// sharkfesteurope.wireshark.org/assets/presentations16eu/02.pdf.
[11] “NetcopeP4,”productBrief.[Online].Available:https://www.xilinx. com/products/intellectual-property/1-pcz517.html
[12] “P4 Language Speci?cation,” 2019. [Online]. Available: https://p4.org/ p4-spec/docs/P4-16-v1.2.0.pdf
[13] “Full Line Rate Sustained 100Gbit Packet Capture,” product Brief. [On- line]. Available: https://www.fmad.io/products-100G-packet-capture. html
[14] “10/25/40/100G Packet Broker with PCAP Filtering,” product Brief. [Online]. Available: https://www.bittware.com/ 102540100g-packet-broker-with-pcap-?ltering/
[15] Fidus, “Sidewinder-100 Datasheet,” 2018, https://?dus.com/wp-content/ uploads/2019/01/Sidewinder Data Sheet.pdf.
[16] Q. Shen, “100G UDP Link for FPGAs though AXI STREAM (GULF STREAM),” 2019, https://github.com/UofT-HPRC/GULF-Stream.
[17] R. Fung, V. Betz, and W. Chow, “Simultaneous Short-Path and Long- Path Timing Optimization for FPGAs,” IEEE/ACM International Confer- ence on Computer Aided Design, pp. 838–845, 2004, https://ieeexplore. ieee.org/document/1382691.
[18] J. Vega, Q. Shen, A. Leon-Garcia, and P. Chow, “Introducing ReCPRI: A Field Re-con?gurable Protocol for Backhaul Communication in a Radio Access Network,” IEEE/IFIP International Symposium on Integrated Network Management, pp. 329–336, 2019, https://ieeexplore.ieee.org/ document/8717902.
[19] J. Vega, “SHIP: A Storage System for Hybrid Interconnected Proces- sors,” Master’s thesis, University of Toronto, Department of Electrical and Computer Engineering, Apr. 2020.
[20] Mellanox, “100Gb/s QSFP28 Direct Attach Copper Cable,” 2018, https://www.mellanox.com/related-docs/prod cables/PB MCP1600-Exxx 100Gbps QSFP28 DAC.pdf.
[21] Xilinx, “UltraScale Devices Integrated 100G Ethernet Subsystem v2.5,” 2019, https://www.xilinx.com/support/documentation/ip documentation/ cmac/v2 5/pg165-cmac.pdf.
[22] B. Gregg, BPF Performance Tools. Addison-Wesley Professional, 2019.
編輯:hfy
-
FPGA
+關注
關注
1630文章
21759瀏覽量
604344 -
斬波器
+關注
關注
0文章
63瀏覽量
9168 -
以太網交換機
+關注
關注
0文章
124瀏覽量
14259 -
PCAP
+關注
關注
0文章
12瀏覽量
12620
發布評論請先 登錄
相關推薦
基于FPGA實現圖像直方圖設計
如何實現FPGA的IO輸出脈沖信號放大?
FPGA技術的主要應用
基于FPGA的人臉識別技術
FPGA無芯片HDMI接入方案及源碼
FPGA實現LeNet-5卷積神經網絡
如何在FPGA上實現神經網絡
采用創新的FPGA 器件來實現更經濟且更高能效的大模型推理解決方案
珠海鏨芯實現28納米FPGA流片
基于FPGA設計頻率計方案介紹分享
FPGA實現的“俄羅斯方塊”游戲系統設計






 工商網監
工商網監
評論