 面向未來的AI加速, ACAP可編程器件具有突破性意義
面向未來的AI加速, ACAP可編程器件具有突破性意義
作者:Mike Thompson,賽靈思 Virtex UltraScale+ FPGA 與 Versal Premium ACAP 高級產品線經理
AI 無處不在、隨時在線和以數據為中心的時代,正催升對更高帶寬的需求,而這已經超出了當今技術和產品尺寸的能力范疇,世界需要一種當前 CPU 和 GPU 技術所無法企及的更高效、更普及、普適的計算,自適應計算應運而生。
AI無處不在,隨時在線和以數據為中心
金錢算什么,數據才是推動當今世界的運轉的王者。從遠程物聯網終端為城市規劃、健康跟蹤、環境保護、業務改進等多樣化用途采集數據,到我們熱衷的視頻流內容和在線分享生活,數據的遷移、管理和分析,正處于所有功能的核心,也促使消費者更廣泛地使用隨時在線的個人物聯網設備,并讓企業和科研越來越依賴以 AI 為中心的應用。
數字化的生活方式和新興的物聯網與云端計算及數據服務的快速增長密不可分。云是全新的生活與工作方式的中心。它存儲著海量的個人內容,供人們隨時隨地進行訪問;它托管點播音樂和視頻流服務;它采集和分析工業數據或企業數據;它將功能強大的軟件應用以按次計費的方式低成本地提供給金融分析、數據庫搜索或基因組測序等工作使用。
此外,5G New Radio( NR )引入了對海量機器通信( MMTC )和超低時延通信( ULLC )的支持,能實現全新的實時蜂窩通信服務。而這將給回傳網、城域網以及核心網的容量和性能帶來巨大壓力。
核心基礎設施面臨越來越大的壓力
如今,提高數據帶寬和計算吞吐量是所有的云數據中心、電信網絡和蜂窩通信回程網共同面臨的強勁需求。涉及的主要基礎設施組成部分包括進出數據中心的鏈路、連接地域分散型數據中心站點的數據中心互聯( DCI )、基礎設施接口卡和加速器卡。事實上,核心基礎設施對數據帶寬的需求名義上是以 51% 的年均復合增長率( GAGR )增長,然而,單是 5G 的推出便可推動區域流量容量需求增長 100 倍。
利用協議處理芯片和接口芯片等分立組件打造新的、更高性能的設備來滿足這些需求,不僅復雜費時,而且越來越難以按照性能需求進行擴展。此外,采用這種方式設計出的系統體積龐大、功耗驚人,無法滿足數據中心和基礎設施設備對空間占用、功耗和熱管理的限制性要求。新一代設備必須在現有的物理、電氣和熱約束條件范圍內大幅提升性能。
除此之外,設計工作需要在最終規格商定之前采用最先進的協議和標準,才能率先投放市場,盡早抓住機遇。對于想要率先將產品投放市場的設備提供商而言,等待標準成熟之后再部署肯定是無法實現領先的預期, 只有擁有能夠隨著項目的進展在硬件層面靈活地適應變化的能力,才能與時俱進領先同行。
具有突破性意義的可編程加速器
對于一些使用傳統 CPU 或 GPU 架構無法快速執行或功耗約束得不到滿足的工作負載,高密度 FPGA 和異構的可編程片上系統 IC( MPSoC )等可編程邏輯器件已成為理所當然的加速器選擇。這些器件不僅可以通過高度并行的處理模式以極為高效的方式解決特定計算難題(例如信號處理和近期的神經網絡),而且還提供了可編程器件固有的靈活應變能力。
現在,為了滿足近來日益嚴苛的性能、帶寬、功耗和集成目標,被稱為自適應計算加速平臺 ( ACAP )的新型可編程器件已經問世。賽靈思 Versal? ACAP 內置一系列智能 AI 和 DSP 計算引擎、等效于 FPGA 邏輯架構的自適應引擎,以及應用處理和實時標量引擎,并通過片上可編程網絡( NoC )互聯緊密耦合。它還集成了軟件控制平臺管理功能和眾多先進的接口,包括 DDR4、100G 以太網、PCIe? Gen 5 和數千兆位光通信接口。
Versal DSP 引擎采用經過改進的 DSP 塊,為 INT8、32 位浮點等操作數提供本機支持,從而提升了多種應用的速度和效率,不僅包括數字信號處理,而且也包括寬動態總線移位器、存儲器地址生成器、寬總線多路復用器以及存儲器映射 I/O 寄存器。標量引擎由一個雙核 Arm? Cortex?-A72 應用處理器和一個雙核 Arm? Cortex?-R5F 實時處理單元構成。ACAP 的異構引擎能夠實現重新編程,以適應隨時間推移而變化的工作負載,或是隨著算法實現或神經網絡模型演進而變化的工作負載。
優化 ACAP 連接性
依托于這種新型可編程器件助力實現的創新,Versal Premium 系列現已能夠應對當今核心基礎設施面臨的壓力。這些高帶寬器件將高計算密度與附加的專用高速加密( HSC )引擎以及先進的網絡接口融為一體。
高密度網絡連接功能包括:提供總雙向帶寬高達 9Tb/s 的可擴展光纖收發器(支持最新的以太網和 Interlaken 速率與協議)、112Gb/s PAM4 收發器、加密處理能力高達 400Gb/s 的高速加密引擎,以及靈活應變的硬件(圖 1)。

圖 1:配備有 112Gb/s PAM4、600G 以太網、600G Interlaken 和 400G HSC 的 Versal Premium ACAP
與現有的 58Gb/s PAM4 技術相比,在核心網、城域網和 DCI 基礎設施中采用 112G PAM4 收發器能夠使每端口帶寬密度翻倍,從而緩解前面板機柜空間的壓力,并為電信和數據中心應用加倍提供單位體積帶寬。與此同時,給定的數據有效載荷的傳輸時延降低 50%,提高了應用的響應能力,有助于降低時延對地域分散型數據中心互聯的影響。
較之賽靈思 16nm Virtex? UltraScale+? FPGA ,片上集成資源提供了高達三倍的帶寬和兩倍的計算密度。另一方面,與專用的特定應用光傳輸網絡( OTN )處理器相比,應用吞吐量提高了三到五倍。
提升計算密度
為了滿足超大規模云服務提供商的當前及未來需求,Versal ACAP 架構將極高的片上存儲器帶寬與高性能異構計算引擎緊密耦合,并通過動態功能交換( DFX )實現靈活的工作負載配置。與之前的 16nm FPGA 相比,DFX 交換內核的速度加快了八倍,支持加速器的動態配置,從而最高效地將器件資源用于隨時間推移而變化的計算工作負載,如數據分析、機器學習視覺處理、基因組學、視頻轉碼、加密處理等。
憑借多種類型的分布式片上 RAM,高達 1Gb 的緊密耦合存儲器可供使用,進而提供了最高 123TByte/s 的等效片上存儲器帶寬。該帶寬能實現各種處理引擎與存儲器之間的高速交互,其速度比如今最優秀的 GPU 快九倍。此外,可編程 NoC 互聯支持與片外 DDR4 存儲器進行高速交互。
Versal Premium ACAP 能夠滿足 DCI 設備的需求,兼容服務器側和傳輸側的多種光通信接口與協議,同時以安全、低成本的平臺靈活適應新興的且不斷演進的標準。1RU 系統或單卡就能提供 3.2Tb/s 的容量,支持多種多樣的標準化和新興協議以及光通信接口(圖 2)。憑借其先進的連接和加密核心,單個 Versal Premium ACAP 器件就能為服務器側的光通信接口提供 4x25G NRZ 連接的多條 100G FlexE 以太網通道、為線路側提供 4x112G PAM4 連接的 400G 以太網通道、線路速率為 1.6Tb/s 的 AES256 加密、控制和端口管理功能。
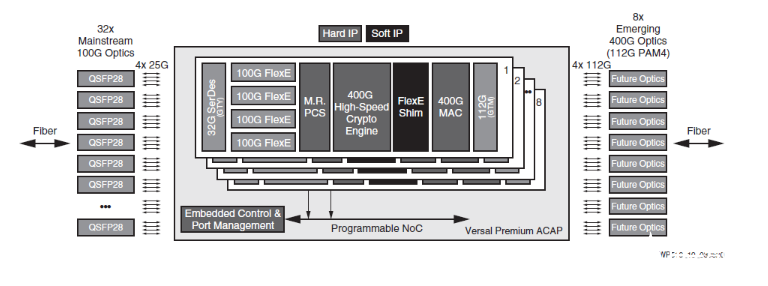
圖 2:采用 Versal Premium ACAP 的 3.2Tb/s DCI
這些器件也非常適合用于高速客戶端接口卡(圖 3),具體方式是利用 Versal Premium ACAP 將數據流量與服務橋接并封裝到行業標準的 OTN 封裝程序中。Versal Premium ACAP 內部集成通道化以太網、Interlaken、112G 和 58G PAM4 GTM 收發器與 32.75G GTYP 收發器,提供每秒多太位容量。這些資源以專用硬 IP 的形式集成,既能獲得 ASIC 級的功率效率,又能釋放 ACAP 邏輯架構用于映射、開銷和 SAR 功能。
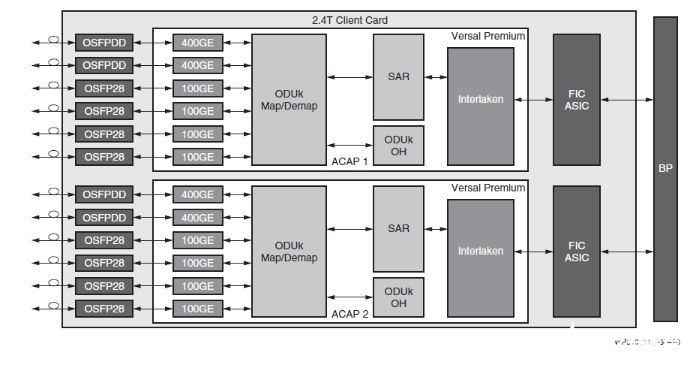
圖 3:2.4Tb/s 客戶端接口卡
面向未來的 AI 加速
通過將異構計算引擎與高存儲器帶寬相結合,Versal Premium ACAP 在處理高難度工作負載(如使用神經網絡開展圖像分類或對象檢測)時,性能顯著優于 GPU。圖 4 對比了Versal Premium 與領先 GPU 的性能,可以看到運行在 680x680 YOLOv2 模型上的對象檢測速度在 ACAP Premium 器件上能提速高達 7.7 倍。
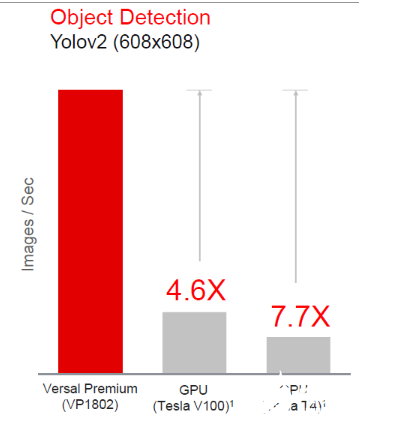
圖 4:與 GPU 進行對比的對象檢測性能
與 FPGA 和 MPSoC 架構相比,ACAP 另一個有助于簡化加速器開發的引人矚目的特性是預先構建的外殼程序,通過它能硬連接到片外接口,如以太網、PCIe Gen 5、DDR4 和光通信接口(圖 5)。這種高效的云連接基礎設施提供了多重優勢,包括允許在設備啟動時進行 CPU 主機和系統存儲器通信、簡化內核布局與時序收斂、簡化加速器虛擬化。外殼程序便于設計人員將器件的內部邏輯架構更多地用于定制功能,否則就需要實現必要的基礎設施,如存儲器和 DMA 控制器。
圖 5:預先構建的外殼程序基礎設施簡化了云連接,同時實現了速度與效率的雙重提升
外殼程序和角色架構可以幫助設計人員快速高效地在 Versal Premium ACAP 中實現先進的智能零售技術。ACAP 器件支持數據驅動的視頻內容分析,有助于降低損失以及提供自動、實時、可執行的庫存洞察,并提供可促進銷售最大化的客戶體驗定制能力。借助 Versal Premium ACAP 能夠在單個平臺上托管視頻分析解決方案,用于視頻元數據的識別、提取和分類(圖 6)。
圖 6:智能零售視頻分析加速器
外殼程序提供了現成的連接與加密功能,而器件的 DSP 引擎和軟件可編程計算內核則可處理對象檢測、圖像分類以及視頻編碼、解碼和縮放。而且能夠在緊鄰計算內核的地方提供最大 1Gb 的片上 SRAM,面向 AI 加速提供高達 123TB/s 的存儲器帶寬。通過消除 GPU 架構和基于 GPU 的架構所特有的存儲器瓶頸與批次大小限制,分析加速器能夠為 Resnet50 提供高達每秒 13,000 幅圖像/秒的處理速度。
結論
盡管消費者和企業界越來越重視數據的價值,客戶也越來越依賴于即時服務交付,但復雜性、計算強度和帶寬耗用正成為瓶頸。ACAP 將高效的分布式異構計算引擎與高速互聯融為一體,以滿足飛速增長的性能需求。通過綜合運用硬 IP、預先構建的創新型連接外殼程序、可編程邏輯架構和軟件可配置資源,ACAP 器件不僅能夠助力提升性能,還能簡化設計,同時提供面向未來的靈活性。
編輯:hfy
-
FPGA
+關注
關注
1630文章
21796瀏覽量
605570 -
神經網絡
+關注
關注
42文章
4779瀏覽量
101101 -
賽靈思
+關注
關注
32文章
1794瀏覽量
131469 -
gpu
+關注
關注
28文章
4768瀏覽量
129296 -
AI
+關注
關注
87文章
31493瀏覽量
270119
發布評論請先 登錄
相關推薦
可編程交流負載標準
使用AMD Versal AI引擎加速高性能DSP應用
可編程晶振的優點和缺點

用TMAG5328電阻器和電壓可編程霍爾效應開關實現可編程性和診斷







 工商網監
工商網監
評論