 Join在Spark中是如何組織運行的
Join在Spark中是如何組織運行的
Join作為SQL中一個重要語法特性,幾乎所有稍微復雜一點的數據分析場景都離不開Join,如今Spark SQL(Dataset/DataFrame)已經成為Spark應用程序開發的主流,作為開發者,我們有必要了解Join在Spark中是如何組織運行的。
SparkSQL總體流程介紹
在闡述Join實現之前,我們首先簡單介紹SparkSQL的總體流程,一般地,我們有兩種方式使用SparkSQL,一種是直接寫sql語句,這個需要有元數據庫支持,例如Hive等,另一種是通過Dataset/DataFrame編寫Spark應用程序。如下圖所示,sql語句被語法解析(SQL AST)成查詢計劃,或者我們通過Dataset/DataFrame提供的APIs組織成查詢計劃,查詢計劃分為兩大類:邏輯計劃和物理計劃,這個階段通常叫做邏輯計劃,經過語法分析(Analyzer)、一系列查詢優化(Optimizer)后得到優化后的邏輯計劃,最后被映射成物理計劃,轉換成RDD執行。
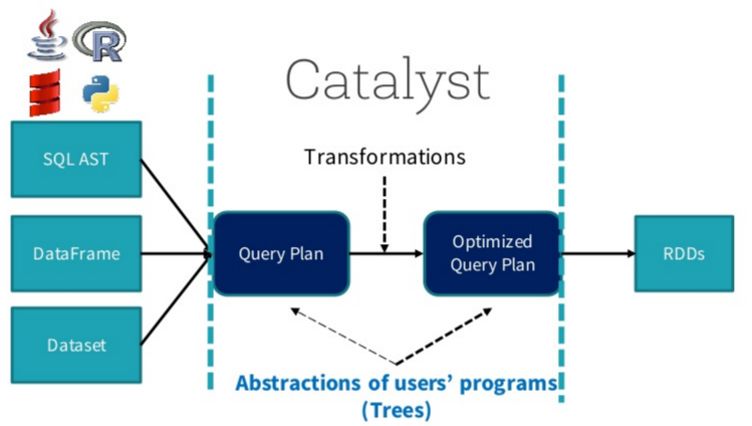
對于語法解析、語法分析以及查詢優化,本文不做詳細闡述,本文重點介紹Join的物理執行過程。
Join基本要素
如下圖所示,Join大致包括三個要素:Join方式、Join條件以及過濾條件。其中過濾條件也可以通過AND語句放在Join條件中。
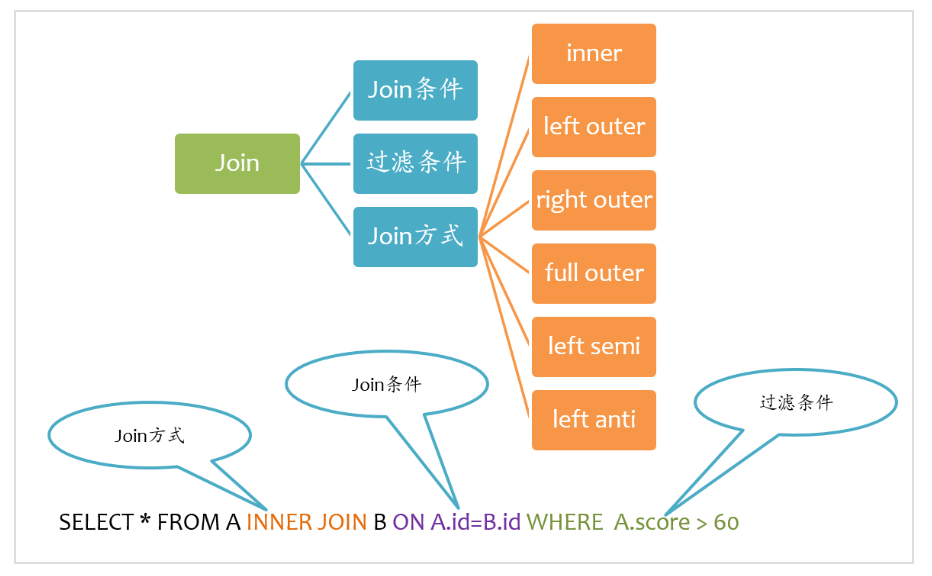
Spark支持所有類型的Join,包括:
inner join
left outer join
right outer join
full outer join
left semi join
left anti join
下面分別闡述這幾種Join的實現。
Join基本實現流程
總體上來說,Join的基本實現流程如下圖所示,Spark將參與Join的兩張表抽象為流式遍歷表(streamIter)和查找表(buildIter),通常streamIter為大表,buildIter為小表,我們不用擔心哪個表為streamIter,哪個表為buildIter,這個spark會根據join語句自動幫我們完成。
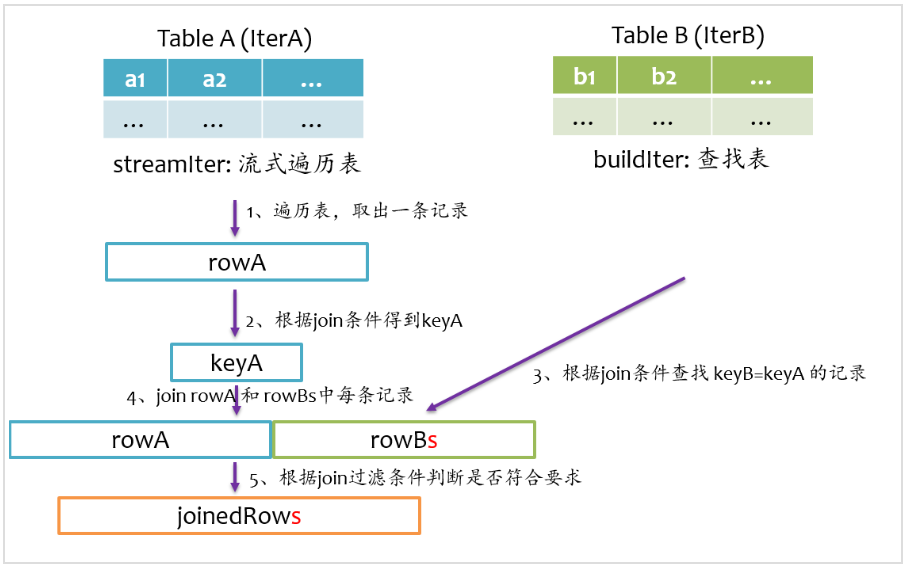
在實際計算時,spark會基于streamIter來遍歷,每次取出streamIter中的一條記錄rowA,根據Join條件計算keyA,然后根據該keyA去buildIter中查找所有滿足Join條件(keyB==keyA)的記錄rowBs,并將rowBs中每條記錄分別與rowAjoin得到join后的記錄,最后根據過濾條件得到最終join的記錄。
從上述計算過程中不難發現,對于每條來自streamIter的記錄,都要去buildIter中查找匹配的記錄,所以buildIter一定要是查找性能較優的數據結構。spark提供了三種join實現:sort merge join、broadcast join以及hash join。
sort merge join實現
要讓兩條記錄能join到一起,首先需要將具有相同key的記錄在同一個分區,所以通常來說,需要做一次shuffle,map階段根據join條件確定每條記錄的key,基于該key做shuffle write,將可能join到一起的記錄分到同一個分區中,這樣在shuffle read階段就可以將兩個表中具有相同key的記錄拉到同一個分區處理。前面我們也提到,對于buildIter一定要是查找性能較優的數據結構,通常我們能想到hash表,但是對于一張較大的表來說,不可能將所有記錄全部放到hash表中,另外也可以對buildIter先排序,查找時按順序查找,查找代價也是可以接受的,我們知道,spark shuffle階段天然就支持排序,這個是非常好實現的,下面是sort merge join示意圖。
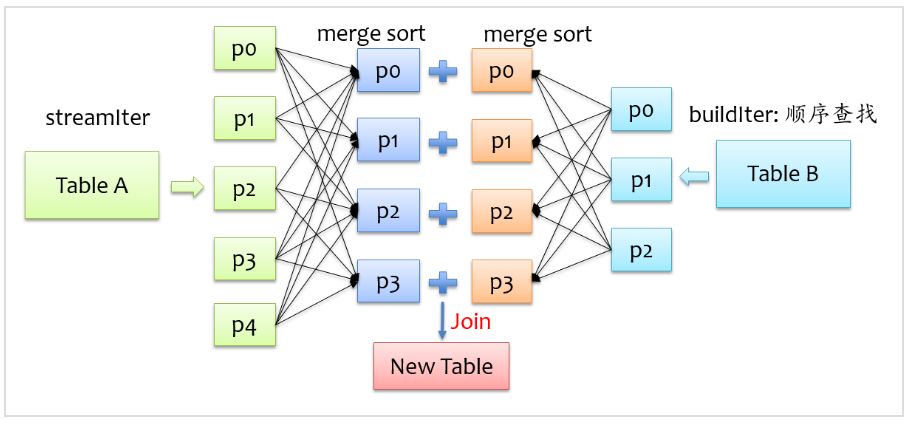
在shuffle read階段,分別對streamIter和buildIter進行merge sort,在遍歷streamIter時,對于每條記錄,都采用順序查找的方式從buildIter查找對應的記錄,由于兩個表都是排序的,每次處理完streamIter的一條記錄后,對于streamIter的下一條記錄,只需從buildIter中上一次查找結束的位置開始查找,所以說每次在buildIter中查找不必重頭開始,整體上來說,查找性能還是較優的。
broadcast join實現
為了能具有相同key的記錄分到同一個分區,我們通常是做shuffle,那么如果buildIter是一個非常小的表,那么其實就沒有必要大動干戈做shuffle了,直接將buildIter廣播到每個計算節點,然后將buildIter放到hash表中,如下圖所示。
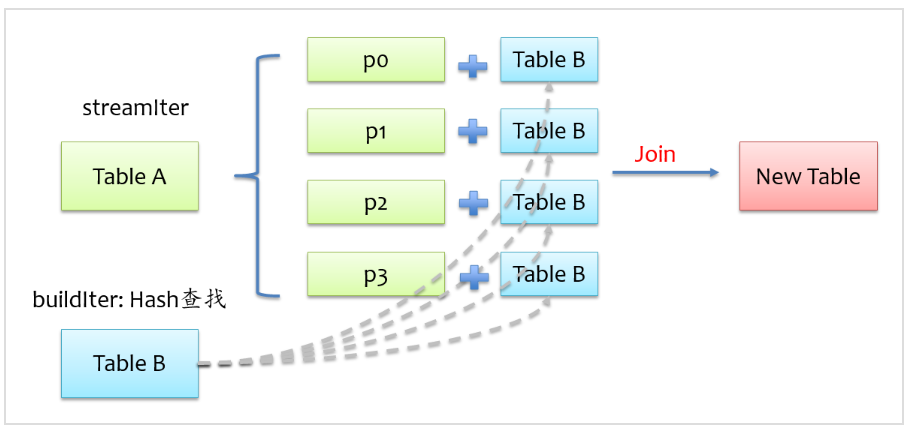
從上圖可以看到,不用做shuffle,可以直接在一個map中完成,通常這種join也稱之為map join。那么問題來了,什么時候會用broadcast join實現呢?這個不用我們擔心,spark sql自動幫我們完成,當buildIter的估計大小不超過參數spark.sql.autoBroadcastJoinThreshold設定的值(默認10M),那么就會自動采用broadcast join,否則采用sort merge join。
hash join實現
除了上面兩種join實現方式外,spark還提供了hash join實現方式,在shuffle read階段不對記錄排序,反正來自兩格表的具有相同key的記錄會在同一個分區,只是在分區內不排序,將來自buildIter的記錄放到hash表中,以便查找,如下圖所示。
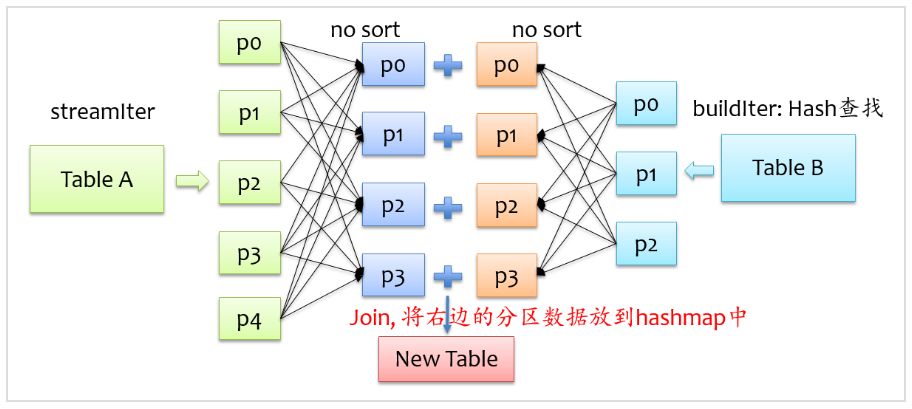
不難發現,要將來自buildIter的記錄放到hash表中,那么每個分區來自buildIter的記錄不能太大,否則就存不下,默認情況下hash join的實現是關閉狀態,如果要使用hash join,必須滿足以下四個條件:
buildIter總體估計大小超過spark.sql.autoBroadcastJoinThreshold設定的值,即不滿足broadcast join條件
開啟嘗試使用hash join的開關,spark.sql.join.preferSortMergeJoin=false
每個分區的平均大小不超過spark.sql.autoBroadcastJoinThreshold設定的值,即shuffle read階段每個分區來自buildIter的記錄要能放到內存中
streamIter的大小是buildIter三倍以上
所以說,使用hash join的條件其實是很苛刻的,在大多數實際場景中,即使能使用hash join,但是使用sort merge join也不會比hash join差很多,所以盡量使用hash
下面我們分別闡述不同Join方式的實現流程。
inner join
inner join是一定要找到左右表中滿足join條件的記錄,我們在寫sql語句或者使用DataFrame時,可以不用關心哪個是左表,哪個是右表,在spark sql查詢優化階段,spark會自動將大表設為左表,即streamIter,將小表設為右表,即buildIter。這樣對小表的查找相對更優。其基本實現流程如下圖所示,在查找階段,如果右表不存在滿足join條件的記錄,則跳過。
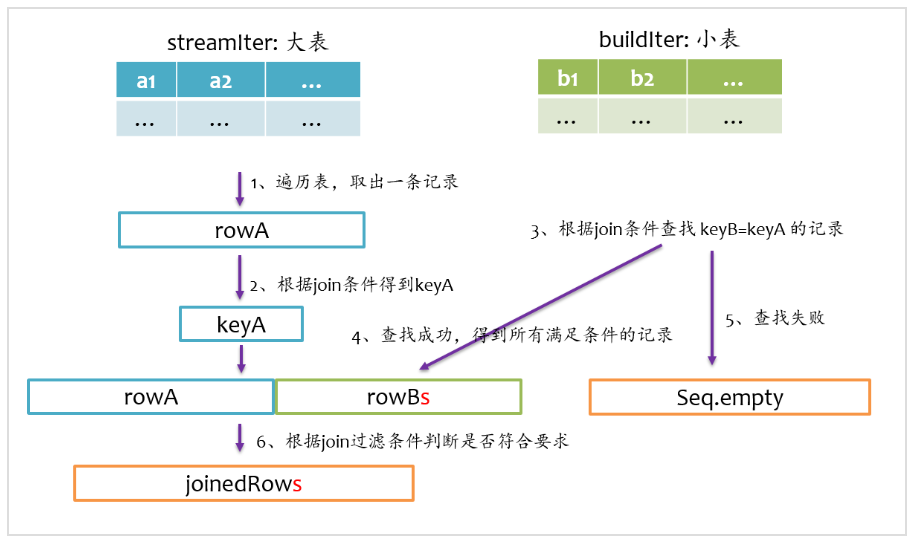
left outer join
left outer join是以左表為準,在右表中查找匹配的記錄,如果查找失敗,則返回一個所有字段都為null的記錄。我們在寫sql語句或者使用DataFrmae時,一般讓大表在左邊,小表在右邊。其基本實現流程如下圖所示。
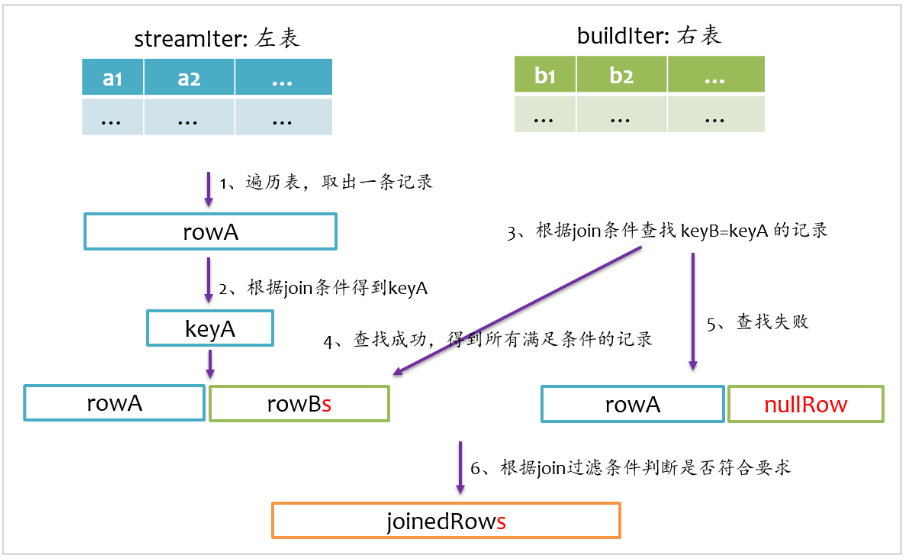
right outer join
right outer join是以右表為準,在左表中查找匹配的記錄,如果查找失敗,則返回一個所有字段都為null的記錄。所以說,右表是streamIter,左表是buildIter,我們在寫sql語句或者使用DataFrame時,一般讓大表在右邊,小表在左邊。其基本實現流程如下圖所示。
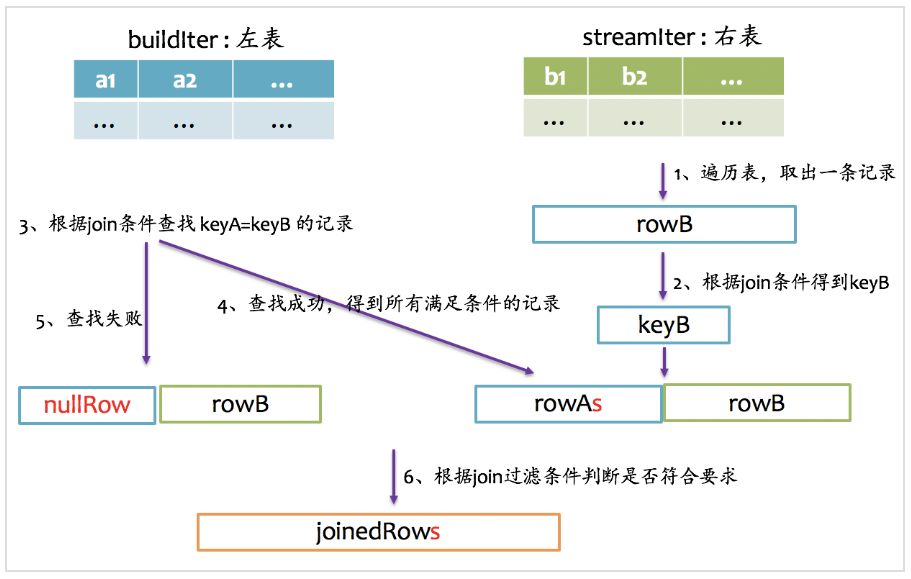
full outer join
full outer join相對來說要復雜一點,總體上來看既要做left outer join,又要做right outer join,但是又不能簡單地先left outer join,再right outer join,最后union得到最終結果,因為這樣最終結果中就存在兩份inner join的結果了。因為既然完成left outer join又要完成right outer join,所以full outer join僅采用sort merge join實現,左邊和右表既要作為streamIter,又要作為buildIter,其基本實現流程如下圖所示。
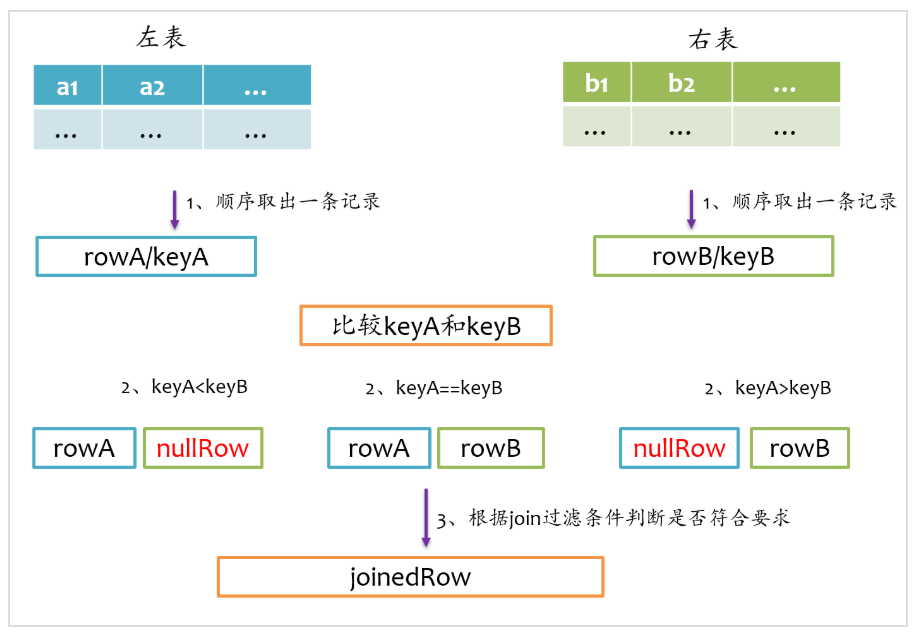
由于左表和右表已經排好序,首先分別順序取出左表和右表中的一條記錄,比較key,如果key相等,則joinrowA和rowB,并將rowA和rowB分別更新到左表和右表的下一條記錄;如果keyA
left semi join
left semi join是以左表為準,在右表中查找匹配的記錄,如果查找成功,則僅返回左邊的記錄,否則返回null,其基本實現流程如下圖所示。
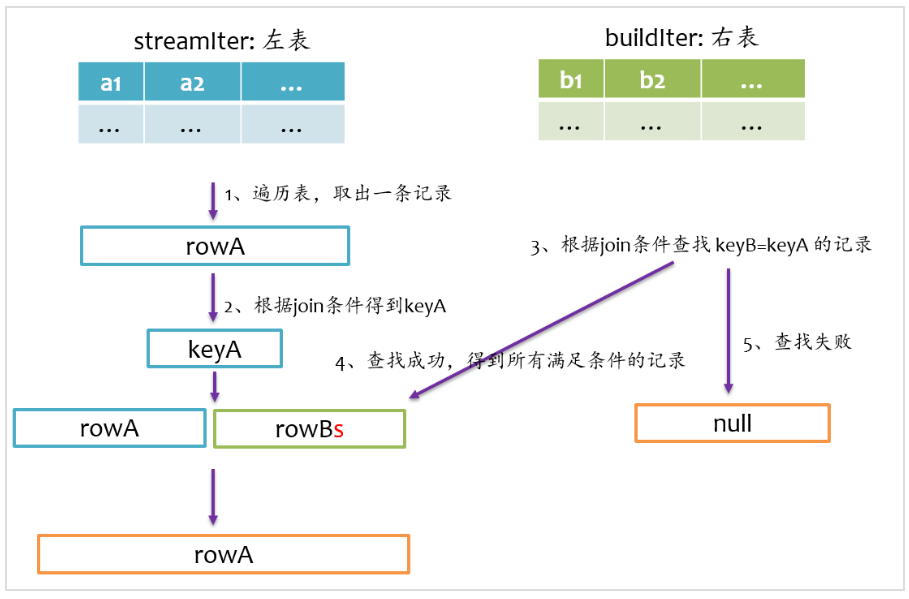
left anti join
left anti join與left semi join相反,是以左表為準,在右表中查找匹配的記錄,如果查找成功,則返回null,否則僅返回左邊的記錄,其基本實現流程如下圖所示。
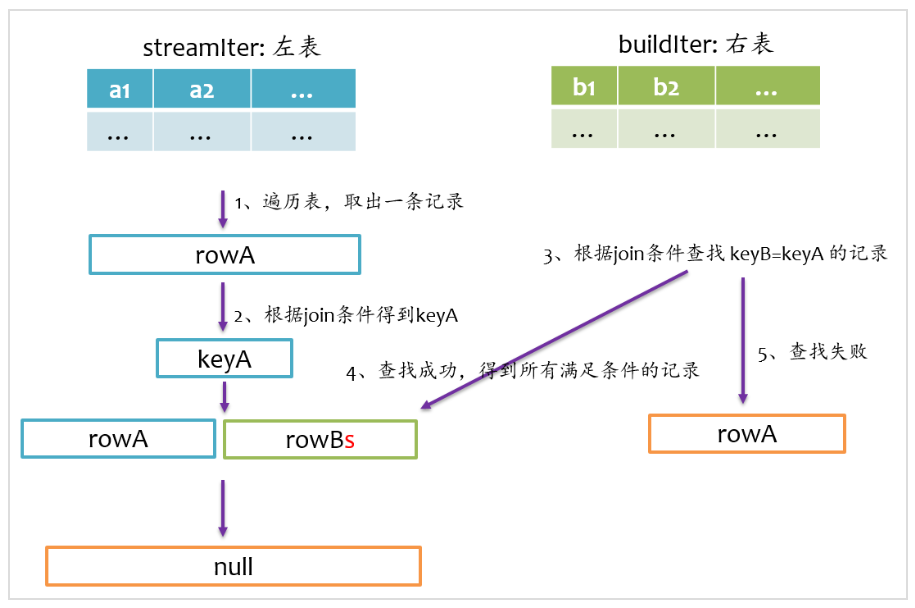
總結
Join是數據庫查詢中一個非常重要的語法特性,在數據庫領域可以說是“得join者得天下”,SparkSQL作為一種分布式數據倉庫系統,給我們提供了全面的join支持,并在內部實現上無聲無息地做了很多優化,了解join的實現將有助于我們更深刻的了解我們的應用程序的運行軌跡。
責任編輯:xj
原文標題:面試必知的 Spark SQL 幾種 Join 實現
文章出處:【微信公眾號:人工智能與大數據技術】歡迎添加關注!文章轉載請注明出處。
-
SQL
+關注
關注
1文章
768瀏覽量
44177 -
SPARK
+關注
關注
1文章
105瀏覽量
19929
原文標題:面試必知的 Spark SQL 幾種 Join 實現
文章出處:【微信號:TheBigData1024,微信公眾號:人工智能與大數據技術】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
spark為什么比mapreduce快?
spark運行的基本流程
Spark基于DPU的Native引擎算子卸載方案

關于Spark的從0實現30s內實時監控指標計算
“Spark+Hive”在DPU環境下的性能測評 | OLAP數據庫引擎選型白皮書(24版)DPU部分節選
移植Nucleo745ziq+cyw43439的wifi_join_wpa3時,得到Wifi_join 33555456錯誤信息如何解決?
STM8在RAM中運行遇到的疑問求解
淺談變電所運行平臺在安全管理中的應用
在stm32的運行程序中,初始函數明明沒有在while函數里面,為什么能反復運行?
如何利用DPU加速Spark大數據處理? | 總結篇
STM32H在IAR中如何實現從FLASH加載到SRAM中運行程序?
Spark基于DPU Snappy壓縮算法的異構加速方案
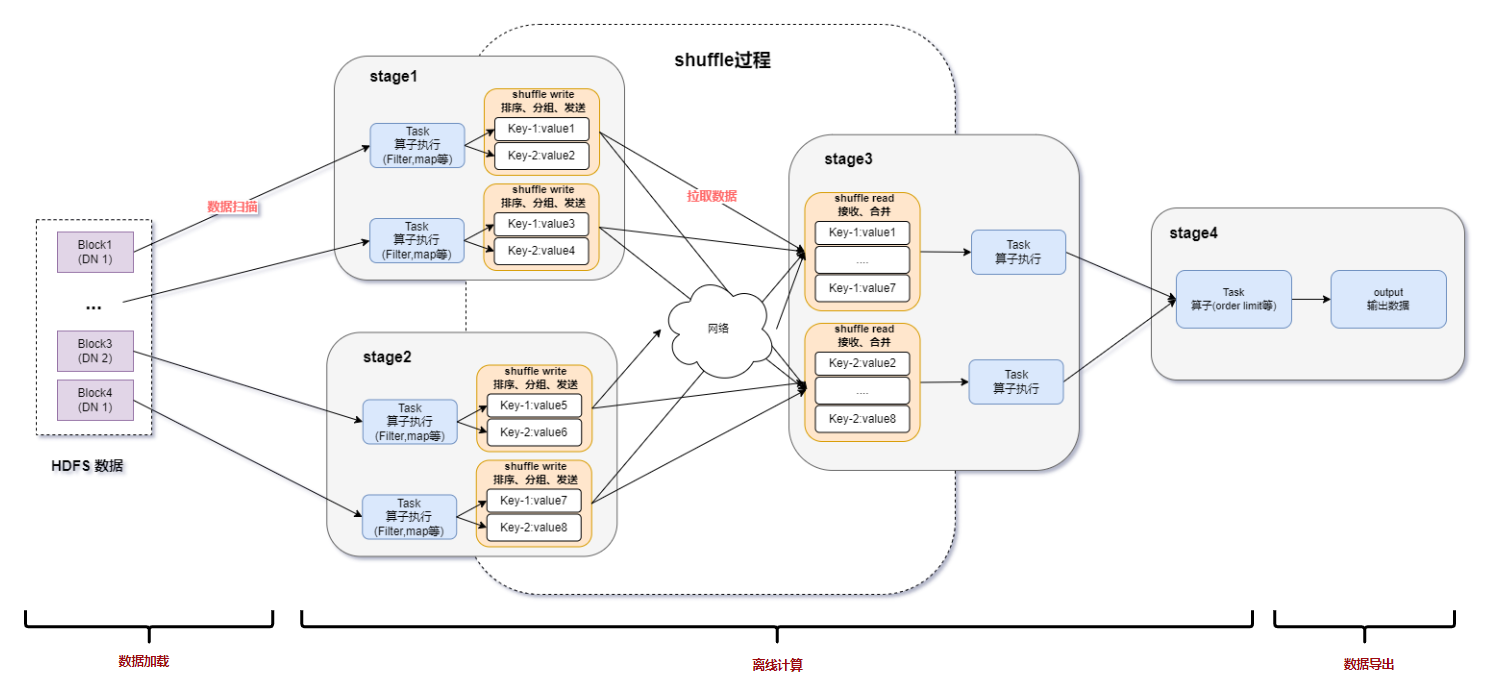
RDMA技術在Apache Spark中的應用

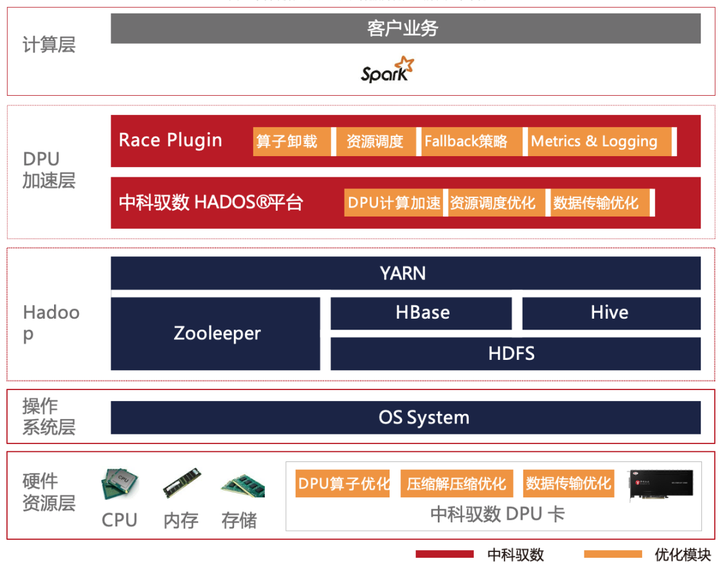
基于DPU和HADOS-RACE加速Spark 3.x
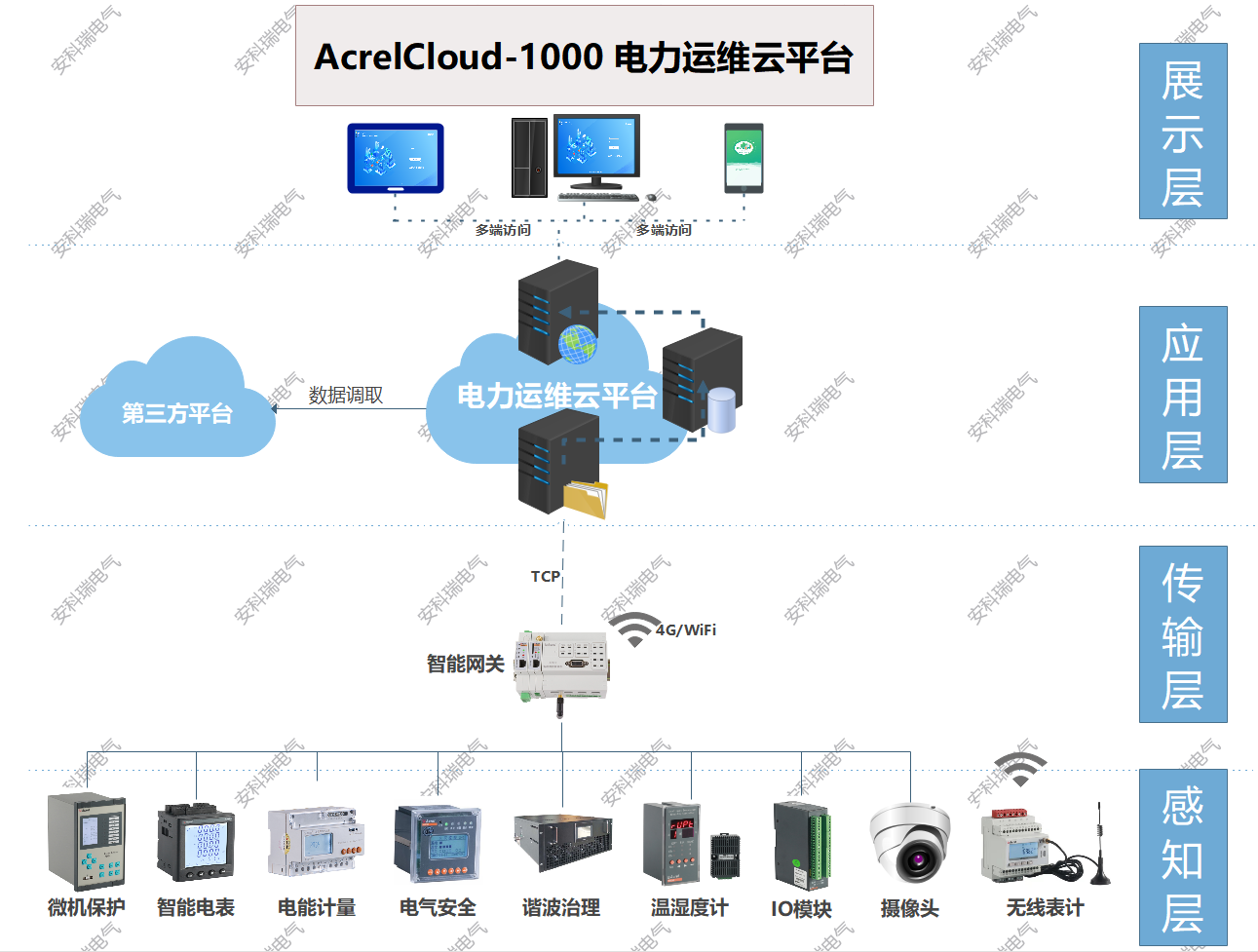
淺談變電所運行平臺在安全管理中的應用





 工商網監
工商網監
評論