 卷積神經網絡能用INT4為啥要用INT8?
卷積神經網絡能用INT4為啥要用INT8?
1
性能挑戰
企業日益重視基于 AI 的系統在數據中心、汽車、工業和醫療等領域中的產品化。
這帶來了兩大挑戰:
AI 推斷需要完成的計算量成數量級增加,同時還要保持價格、功耗、時延和尺寸大小不變。 AI 科學家繼續日復一日地在算法和模型上開展創新,需要各種不同的硬件架構提供最佳性能。
2
方案概述
對于 AI 推斷,在提供與浮點媲美的精度的同時,int8 的性能優于浮點。然而在資源有限的前提下,int8 不能滿足性能要求,int4 優化是解決之道。通過 int4 優化,與現有的 int8 解決方案相比,賽靈思在實際硬件上可實現高達 77% 的性能提升。賽靈思4 位激活和 4 位權重 (4A4W) 全流程硬件友好型量化解決方案可實現更優異的精度/資源權衡取舍。
該白皮書介紹了在Zynq UltraScale+ MPSoC 和 Zynq-7000 SoC 系列(16nm和28nm)上面向CNN4位XDPU實現的低精度加速器。這種加速器通過高效地映射卷積計算,充分發揮其DSP功能。這種解決方案可提供優于XDPU兩倍的解決方案級性能。在ADAS系統中執行2D檢測任務時,這種實現方案能在ZynqUltraScale+MPSoCZCU102板上實現230fps的推斷速度,與8位XDPU相比性能提高1.52倍。
此外,在用于ADAS系統中的不同任務時,該解決方案可實現媲美全精度模型的結果。
3
技術導讀
對持續創新的強烈需求需要使用靈活應變的領域專用架構 (DSA)。優化 AI 推斷性能和降低功耗的主要趨勢之一是使用較低精度和混合精度。為降低硬件設計復雜性,模型量化被當作關鍵技術應用于各類硬件平臺。大量工作被投入用于最大限度地降低 CNN 運算量和存儲成本。這項研究充分地證明,對于大多數計算機視覺任務,在不嚴重犧牲精度的情況下,權重和激活可以用 int8 表達。
然而對于某些邊緣應用而言,硬件資源仍然不足。在對邊緣應用使用較低的位寬(如 1 位、2 位)時,一些常見的硬件設計解決方案使用簡化的乘法器。盡管這些解決方案時延低、吞吐量大,但它們與全精度模型相比,仍然存在較大的精度差距。因此,在模型精度和硬件性能之間尋求平衡變得至關重要。
賽靈思運用幾種常見的網絡結構(ResNet50V1、ResNet50V2 、MobilenetV1和MobilenetV2),在 ImageNet 分類任務上通過使用幾種不同的量化算法進行了實驗。結果顯示精度隨著位寬減少而下降。尤其是在位寬低于 4 時精度下降顯著。此外,賽靈思也使用 Williams 等介紹的 Roofline 模型,分析不同位寬下的硬件性能。
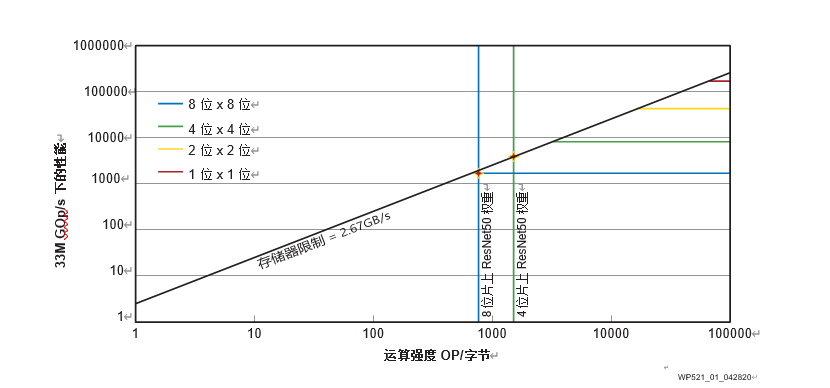
在ZCU102上以不同位寬運行Roofline模型
如圖 1 所示,以賽靈思 ZCU102 評估板為例,隨著 MAC 的精度降低,硬件成本降低,性能得到提高。此外,實驗結果還顯示,低比特量化可通過降低存儲器需求提高性能。這在 ResNet-50 神經網絡的卷積運算強度上得到證實。該網絡分別用 8 位精度和 4 位精度進行了運算。因此,int4 在模型精度和硬件性能之間實現了最佳權衡。
-
神經網絡
+關注
關注
42文章
4779瀏覽量
101126 -
AI
+關注
關注
87文章
31493瀏覽量
270182 -
adas
+關注
關注
309文章
2193瀏覽量
208824
原文標題:卷積神經網絡能用 INT4 為啥要用 INT8 ?- 最新白皮書下載
文章出處:【微信號:FPGA-EETrend,微信公眾號:FPGA開發圈】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論