 使用面陣相機進行傳送帶視頻流的拼接
使用面陣相機進行傳送帶視頻流的拼接
背景
在工業應用中,使用面陣相機識別傳送帶上的物體,當要識別的目標的最小包圍矩形(不是最小包圍旋轉矩形)小于相機視野時,可以進行后續處理。但是當要識別的目標很大,比如超長的物體,如果還使用面陣相機,有兩種辦法,一種是硬件改進,另一種是軟件改進。硬件改進就是在傳送帶運動方向均布多個面陣相機,通過同步觸發同時采集圖片,然后根據事先標定好的相機相對位置進行拼接。軟件改進需要對傳送帶上的視頻流進行處理,拼接出比較大的視野。
解決方法
一般在工業上會采用硬件改進的方法。當需要提高視覺識別的精度或者范圍時,會采用多個相機圖像進行拼接的辦法。但是在實驗室,我們可以嘗試使用軟件的方法來解決。
解決這個問題的關鍵是圖片的拼接,而圖像的拼接需要圖像中有明顯的特征點。而目標上是否有特征點我們不能控制,所以需要事先在傳送帶上布置特征點。
傳送帶上只有平移,所有對于圖像拼接的3個參數x,y和θ,只需要計算x,如果相機成像平面和傳送帶平面不平行,需要先做一個透視變換。
特征的設計及擺放考慮如下:容易識別,編碼容量不需太大,循環布置。
原始視頻
以下是在傳送帶運動時采集到的視頻:
拼接結果
算法原理
第一步:從視頻流中提取一幀圖像,作為關鍵幀,轉到第2步。
第二步:提取下一幀,根據識別到靶標計算該幀圖像和當前關鍵幀平移距離x1,如果x1約等于
0.4倍的視頻運動方向圖像像素,則把這一幀作為次關鍵幀,轉到第三步,否則重復第二步。
第三步:提取下一幀,根據識別到靶標計算該幀圖像和當前次關鍵幀平移距離x2,如果x1+x2 約等于
0.8倍的視頻運動方向圖像像素,則把當前幀作為新的關鍵幀,轉到第二步,否則重復第三步。
在23步循環的時候,把所有關鍵幀按照順序,根據當時的平移距離x1+x2進行拼接就得到一幅長圖。當然也可以實時輸出關鍵幀和對應的x1+x2。這樣,在高層算法開發時,可以認為這是一個幀觸發信號有點波動(由于幀率和傳送帶運動速度的不確定性,x1+x2不是固定值)的線陣相機。這也相當于做了一個中間層,屏蔽了底層的硬件細節,使得原本為線陣相機開發的算法也可以用在面陣相機上。
-
圖像
+關注
關注
2文章
1089瀏覽量
40553 -
視覺識別
+關注
關注
3文章
89瀏覽量
16782 -
工業應用
+關注
關注
0文章
53瀏覽量
15431
原文標題:使用面陣相機進行傳送帶視頻流的拼接
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
線陣ccd和面陣ccd區別
AMS-MC158:重塑LED視頻拼接新境界

AMS-SC159:開啟LED視頻處理與拼接的新篇章
仿真設計|基于51單片機的傳送帶計數器
教育場景中的自動化分揀系統!基于大象機器人UltraArm P340機械臂和傳送帶的實現


一文解析工業相機幀率與曝光時間的關系

思普泰克瓶蓋檢測設備解決方案

labview全景圖像拼接
面陣相機和線陣相機的區別
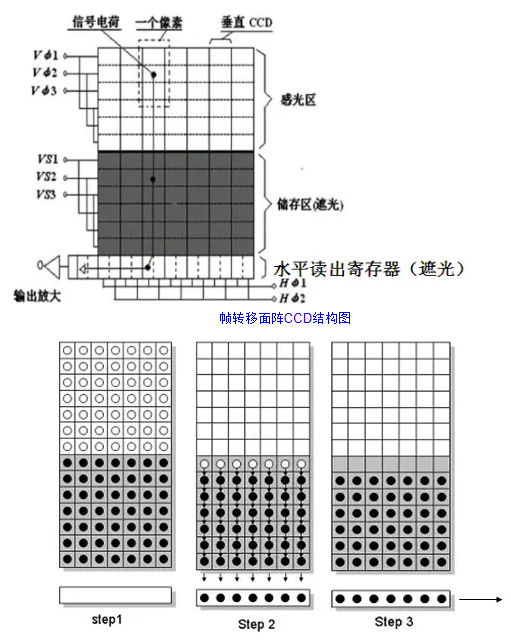
面陣CCD結構圖及工作過程分析





 工商網監
工商網監
評論