 近五年來中文電子病歷的命名實體識別研究進展
近五年來中文電子病歷的命名實體識別研究進展
閱讀綜述性論文是一種能夠快速了解某一領域的方法,接下來通過今年的一篇綜述性論文來了解一下近五年來中文電子病歷的命名實體識別研究進展。
基本的,我們應該先來了解一下兩個概念:電子病歷和命名實體識別。
電子病歷(Electronic Medical Record,EMR)是指醫務人員在醫療活動過程中,使用醫療機構信息系統生成的數字化信息, 并能實現存儲、管理、傳輸和重現的醫療記錄。電子病歷中的文本內容是醫務人員按照《病歷書寫基本規范》和《電子病歷基本規范(試行)》中相關書寫規定,圍繞患者醫療需求與服務活動而記錄的描述性文本內容。
命名實體識別(Named Entity Recognition,NER)是指識別自由文本中具有特定意義的實體,如人名、地名、專有名詞等。與通用領域的命名實體不同,電子病歷中的命名實體通常有疾病、癥狀、治療等實體。
有了上述兩個概念的了解后,接下來我們就可以來了解中文電子病歷命名實體識別的任務,它包括:
①電子病歷數據的獲取與匿名化處理;
②明確命名實體種類,進行語料標注;
③構建模型進行實體識別;
④結果評價及優化。
以電子病歷中現病史章節為例,中文電子病歷命名實體識別研究任務流程如圖1所示:
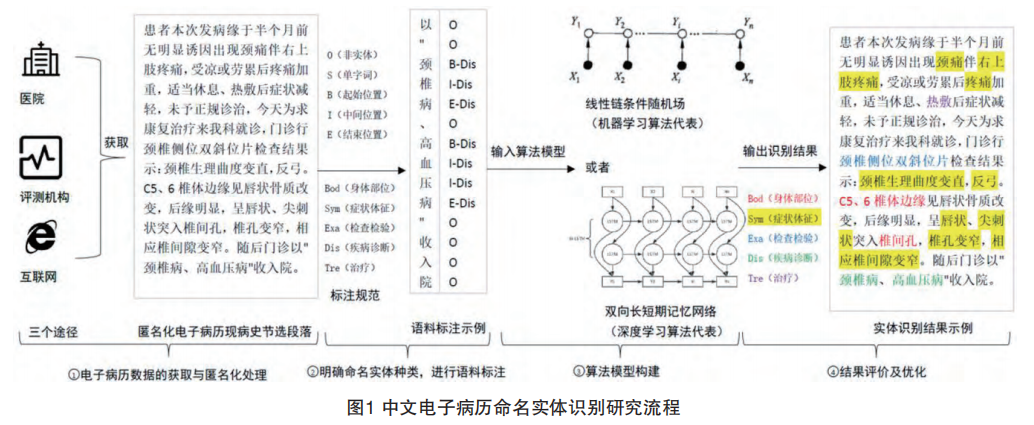
從上述四個任務出發,我們繼續進行探討。
1
電子病歷數據集的獲取
中文電子病歷數據的獲取途徑通常包括:
①與醫院建立合作關系,如曲春燕等通過與某醫科大學附屬醫院建立合作關系獲取到該院35個大科室、87個小科室的992份電子病歷。同時,相關醫務人員也全程參與數據標注,為數據集的質量提供了保障。
②開放獲取的學術評測語料,如CCKS2020學術評測任務三開放了用于命名實體識別評測任務的已標注匿名化電子病歷1500份和未標注的電子病歷1000份,在電子病歷語料資源匱乏的現狀下,全國知識圖譜與語義計算大 會無疑為行業發展作出了巨大貢獻。 ③網絡發布的電子病歷資源。 當前,大多數研究采用第1種方式獲取電子病歷的研究數據,并邀請醫務人員參與語料數據的標注工作;而第2、3種獲取方式具有很大的不確定性,并且電子病歷的數據標注工作過程控制和質量控制均存在不確定性。
2
數據標注的相關工作
曲春燕等參照i2b2 2010的標注規范制定了中文電子病歷的標注規范,進而在兩名臨床醫生的全程參與下,對病歷文本分為前后共計4輪標注,并進行了一致性檢驗。楊錦鋒等在曲春燕等人的工作基礎上,對相同的病歷文本資源,進行了命名實體和實體關系的標注語料構建工作。He等在曲春燕、楊錦鋒等人的工作基礎上,新增了電子病歷文本的分詞、詞性標注、斷言、關系抽取等自然語言處理常見任務的語料標注工作,并對標注結果進行了一致性檢驗。 上述學者的延續性標注工作,對今后研究的語料標注工作具有一定的指導意義。然而,與臨床醫生長期從事語料建設和維護的難以實現。一方面,臨床醫生用于語料標注的時間有限;另一方面,邀請臨床醫生標注語料成本更高。因此,醫學數據標注團隊建設和專業人員培養的可行性值得探討。
3
主要的命名實體識別算法模型
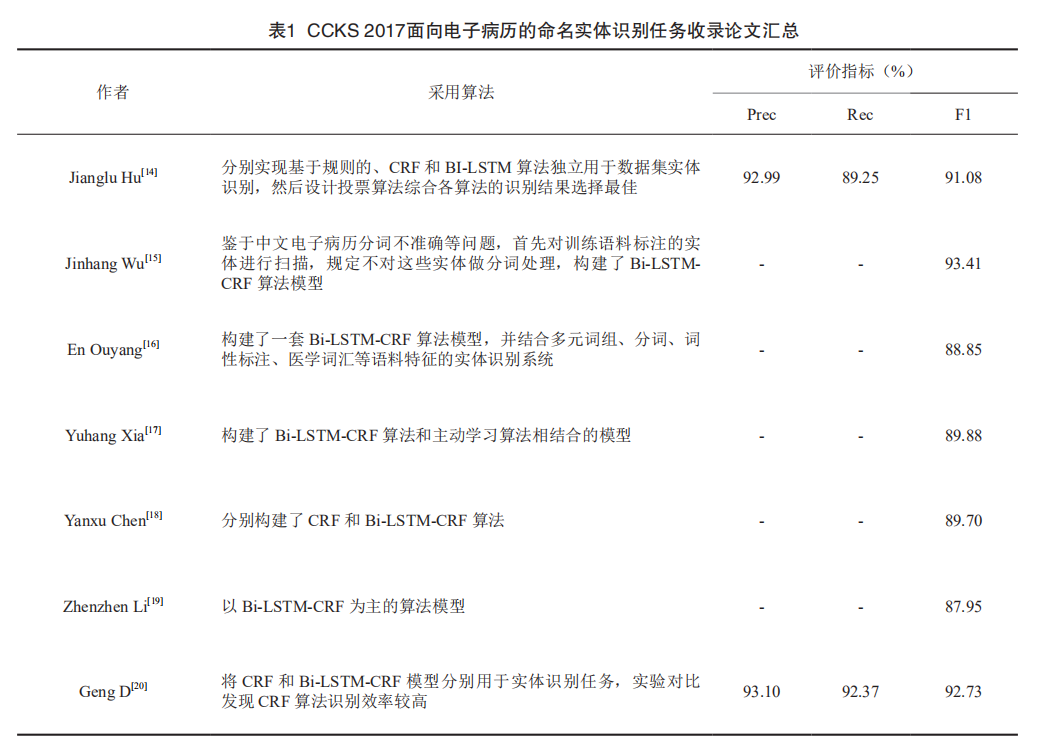
中文命名實體識別的主要研究算法為條件隨機場(CRF)和雙向長短期記憶網絡模型條件隨機場(Bi-LSTM-CRF)。 Liu等設計不同特征模板和上下文窗口進行條件隨機場的學習訓練,進行模型實體識別效率的比對分析,以尋找最佳的電子病歷特征模板和上下文窗口。Liu等在i2b2 2010,2012和2014語料上實驗對比了Bi-LSTM-CRF與傳統的CRF實體識別算法的性能,結果表明Bi-LSTM-CRF性能較好。CCKS 2017學術評測任務二:面向電子病歷的命名實體識別,共收錄了7篇論文,研究內容和測評結果等見表1。總體上看,7篇論文均有對Bi-LSTM-CRF(或Bi-LSTM)算法模型的實現;均采用“字粒度”模型使用word2vec工具將輸入文本特征向量化表示。Zhang等利用CCKS 2017開放的電子病歷語料,分別采用CRFs和Bi-LSTM-CRF兩種統計機器學習算法從電子病歷數據集中識別疾病、身體部位和治療等信息,并對兩種方法進行了對比分析,發現后者性能較好。Qiu等為提高循環神經網絡模型的訓練速度,提出了殘差卷積神經網絡條件隨機場模型(RD-CNN-CRF)在CCKS 2017開放測試語料上獲得了較Bi-LSTM-CRF更高的訓練速度和F1值。CCKS 2018學術評測任務一:面向中文電子病歷的命名實體識別,共收錄論文2篇,分別是Yang等將詞嵌套、詞性、偏旁部首、拼音、詞典和規則特征作為條件隨機場(CRFs)的學習特征,實驗F1值為89.26%;Luo等基于多特征(如標點符號、分詞和詞典等特征)融合,整合CNN-CRF, Bi-LSTM-CRF, Bi-LSTM-CNN-CRF, Bi-LSTM+CNN-CRF和Lattice LSTM五種神經網絡模型,實驗F1值最高達到了88.63%(表1)。
4
結果評價及優化
隨著中文電子病歷命名實體識別的研究逐步深入以及相關算法框架的逐漸成熟,基于中文電子病歷的命名實體識別算法構成了臨床電子病歷系統、專病科研數據提取、臨床輔助決策系統的重要組成部分。 電子病歷命名實體識別結果評價指標說明如下圖:

袁冬生為解決出院小結文檔中普遍存在的信息不準確、無效信息、信息缺失等問題,設計開發了一套基于命名實體識別的出院小結錯誤檢測系統。李山為提高住院病歷錄入的交互性和可操作性,降低書寫的繁雜度,減輕醫生負荷,提高工作效率,使用條件隨機場算法,進行電子病歷命名實體識別,提取病歷中重要的診療信息,并將其應用在住院病歷錄入輔助中,以優化和改善病歷錄入方式。Su等則基于中文電子病歷命名實體標注規范構建了一個可用于識別心血管疾病危險因素的語料庫。
展望
.....
針對電子病歷的語義特征的量化分析與研究,對于提升算法特征工程質量有積極意義;近兩年來,針對電子病歷語料標注的成本問題,很多研究聚焦于半監督和無監督的算法來實現基于少量標注語料或完全基于非標注原始語料進行實體識別,是一個重要的研究方向。
-
電子病歷
+關注
關注
1文章
61瀏覽量
20136 -
數字化
+關注
關注
8文章
8754瀏覽量
61819 -
識別
+關注
關注
3文章
173瀏覽量
31973
原文標題:【NER綜述】近五年中文電子病歷命名實體識別研究進展
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
高能點焊電源技術在現代工業制造中的應用與研究進展

上海光機所在多路超短脈沖時空同步測量方面取得研究進展
AI大模型的最新研究進展
導熱紙(膜)的研究進展 | 晟鵬技術突破導熱芳綸紙

量子計算+光伏!本源研究成果入選2023年度“中國地理科學十大研究進展”

銻化物超晶格紅外探測器研究進展與發展趨勢綜述
用于先進電生理記錄的有源微納協同生物電子器件研究進展綜述
綜述:高性能銻化物中紅外半導體激光器研究進展

先進封裝中銅-銅低溫鍵合技術研究進展

電子封裝用金屬基復合材料加工制造的研究進展
2023年度中國半導體十大研究進展出爐,一項傳感器技術入榜(附全名單)
2023年LLM大模型研究進展
增強光聲雙光梳光譜的研究進展

電動汽車功率電子封裝用耐高溫環氧塑封料的研究進展





 工商網監
工商網監
評論