 C語言結構體的詳細資料介紹
C語言結構體的詳細資料介紹
引言
不管什么樣的編程語言,數據類型的不斷衍生都是為了不同場合對其進行不同處理或管理。 比如單一的變量,我們可以定義成char, short,,int,float, double等;而如果需要管理多個同一類型的數據就可以使用數組來統一管理;那么如果是不同的數據類型,但是彼此是相關聯的呢? 此時就可以使用結構體來統一管理,這也是面對對象的基本思想。比如一個學生,他有如下信息: 名字(char *), 年齡(uint8), 成績(float)等。今天我們就來說說結構體的基本使用,后續再深入研究。
結構體的定義
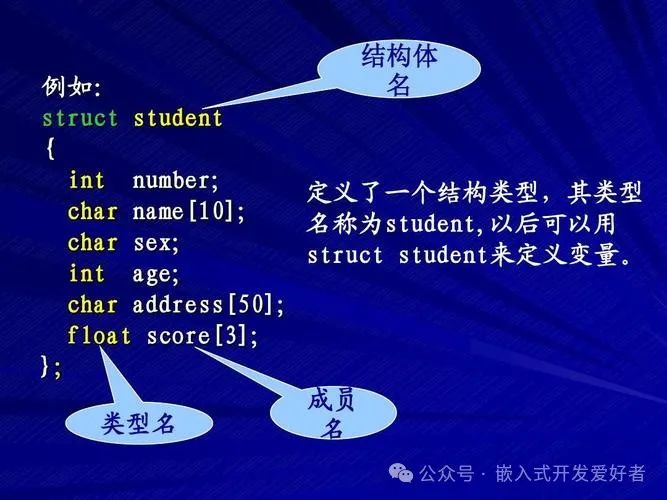
使用struct關鍵字定義原生結構體類型
struct people{ char name[20]; int age;};
使用typedef類型自定義結構體類型
typedef struct people1{ char name[20]; int age; }people1_t;
兩種方式的有何不同呢? 第一種屬于原生結構體類型,在定義變量之前,都需要加上struct people
struct people p1;
而第二種使用typedef關鍵字自定義了people_t類型(people1_t等同于struct people1), 即在定義變量時,只需要在變量之前寫上people_t即刻。
people1_t p2;
這兩種方式都可,用戶根據自己的習慣選擇其中一種即刻,個人推薦第二種,定義比較方便~
定義結構體變量和初始化
如上所述,使用第一種struct people定義結構體變量時,有如下方式:
struct people{ char name[20]; int age;};int main(void){ struct people p1; //使用struct people定義變量p1 return 0;}
或:
//定義類型的同時定義變量struct student{ char name[20]; int age;}std;int main(void){ std.age =23; //直接使用std結構體變量 return 0;}
使用typedef方式定義結構體變量
typedef struct people1{ char name[20]; int age; }people1_t;int main(void){ people1_t p2; return 0;}
接下來我們再介紹結構體的兩種方式初始化:
#include 《stdio.h》#include 《string.h》struct people{ char name[20]; int age;};typedef struct people1{ char name[20]; int age; }people1_t;int main(void){ //方式一:在定義的變量的同時初始化 struct people p1 ={ .name = “xiaoming”, .age = 23 }; people1_t p2; //方式二: 定義變量后,再對其初始化 strcpy(&p2.name[0], “xiaohong”); p2.age = 45; printf(“p1.name = %s, age = %d. ”, p1.name, p1.age); printf(“p2.name = %s, age = %d. ”, p2.name, p2.age); return 0;}
編譯運行:
結構體的元素訪問
在C語言中有兩種方式訪問,分別是“。”和“-》”, 具體參考如下代碼:
#include 《stdio.h》#include 《string.h》#include 《stdlib.h》struct people{ char name[20]; int age;};typedef struct people1{ char name[20]; int age; }people1_t;int main(void){ //定義結構體變量,并初始化 struct people p1 ={ .name = “xiaoming”, .age = 18 }; //定義結構體指針變量 people1_t *p2 = NULL; //申請people1_t結構體大小的堆內存空間,并將得到的起始地址賦予p2 p2 = (people1_t *)malloc(sizeof(people1_t)); if(NULL != p2) { //初始化 strcpy(&p2-》name[0], “xiaohong”); p2-》age = 26; } //結構體變量通過‘。’來訪問其元素 printf(“p1.name = %s, age = %d. ”, p1.name, p1.age); //結構體變量通過‘-》’來訪問其元素 printf(“p2.name = %s, age = %d. ”, p2-》name, p2-》age);}
編譯運行結果:
以上兩種方式都是使用下標式訪問結構體元素, 那么如何使用指針方式訪問呢?
#include 《stdio.h》#include 《string.h》#include 《stdlib.h》struct my_test{ int a; //4 double b; //8 char c; //1};int main(void){ struct my_test s1; s1.a = 12; s1.b = 3.4; s1.c = ‘a’; int *p1 = (int *)&s1; double *p2 = (double *)((long unsigned int)&s1 + 8); char *p3 = (char *)((long unsigned int)&s1 + 8 + 8); printf(“s1.a = %d. ”, s1.a); printf(“s1.b = %.1f. ”, s1.b); printf(“s1.c = %c. ”, s1.c); printf(“===================== ”); printf(“*p1 = %d. ”, *p1); printf(“*p2 = %.1f. ”, *p2); printf(“*p3 = %c. ”, *p3);}
分析:
int *p1 = (int *)&s1,其中&s1為結構體的起始地址,也是首元素a的地址,因此可以通過類型轉化后賦值給p1(int *類型,指向int類型的變量a)
double *p2 = (double *)((long unsigned int)&s1 + 8); 其中因為&s1是作為結構體地址,本身是帶有數據類型的,我們通過(long unsigned int)將其轉化成普通的長整型數值,然后再加上a(8字節)的長度,之后的地址就是結構體第二個元素b的地址了,于是乎將得到的地址轉化成double *類型賦值給p2,通過p2來訪問。
char *p3 = (char *)((long unsigned int)&s1 + 8 + 8); 與上步驟分析一致, 首先將&s1轉化成普通的普通的長整型數值,然后加上元素a 和 元素b的數據類型長度,就得到了元素c的地址,再賦值給p3,通過p3來訪問結構體元素c。
編譯運行結果:
總結
從數組到結構體的進步之處:數組有2個明顯的缺陷:第一個是定義時必須明確給出大小,且這個大小在以后不能再更改(這里不考慮可變數組);第二個是數組要求所有的元素的類型必須一致。
結構體就完美解決了數組的第二個缺陷的,可以將結構體理解為一個其中元素類型可以不相同的數組。結構體完全可以取代數組,只是在數組可用的范圍內數組比結構體更簡單,使用更方便。
-
C語言
+關注
關注
180文章
7608瀏覽量
137128 -
代碼
+關注
關注
30文章
4802瀏覽量
68743 -
變量
+關注
關注
0文章
613瀏覽量
28409
發布評論請先 登錄
相關推薦
深入理解C語言:循環語句的應用與優化技巧

結構體成員的順序會影響結構體的大小嗎
C語言與Java語言的對比
技術干貨驛站 ▏深入理解C語言:掌握程序結構知識
京準電鐘:GPS時鐘服務器(NTP授時服務器)資料詳細介紹書
C語言結構體史上最詳細的講解【軟件干貨】

plc編程語言與c語言的聯系 c語言和PLC有什么區別
如何解決C語言中的“訪問權限沖突”異常?C語言引發異常原因分析
經典 C 語言編程,結構體和聯合體如何共用?
結構體與指針的關系






 工商網監
工商網監
評論