 華為提高人機自然對話的準確性專利
華為提高人機自然對話的準確性專利
華為的該項專利用于人機對話的方法,具體通過將自然語言問題和知識庫向量化,然后向量計算得到基于知識庫的回答,提高了人機對話中自然語言答案的準確性。
隨著互聯網和智能終端的快速發展,人機對話的應用越來越廣泛。現在,許多互聯網公司都各自的推出了智能助手,如Apple Siri、Google Now、微軟小娜(Microsoft Cortana)、Facebook M、百度度秘和微軟小冰等等,這些智能助手能夠與人進行簡單的對話,并且完成一些基本的任務,但是現有的智能助手存在只考慮自動問答,對話中問題的回復的準確率較低。因此,智能助手的相關技術還需要不斷發展和改進,朝著更加擬人化、博學化和智能化的方向發展。
華為在2015年底提供了一種用于人機對話的方法、神經網絡系統和用戶設備,這種方法可以將對話和基于知識庫的問答相結合,能夠與用戶進行自然語言交互,并且依據知識庫給出基于事實的正確的自然語言答案。
圖1
圖1為該專利提供的用于人機對話的方法,其中,
在步驟S310中,自然語言問題可以是用戶通過麥克風等進行語音輸入,也可以通過鍵盤、鼠標等進行文字或圖形的輸入,還可以是其它的一些輸入形式,系統根據用戶輸入的自然語言問題能夠轉化為序列即可。
步驟S320,將自然語言轉化為問題向量。可以將自然語言問題作為神經網絡系統的第一神經網絡模塊的輸入,計算獲得該自然語言問題對應的問題向量。
步驟S330的目的是獲取與前述自然語言問題相關的答案。以知識答案為三元組為例,則是獲得與自然語言問題相關的至少一個三元組,其中,至少一個三元組與至少一個三 元組向量對應。
步驟340的作用是計算問題向量與至少一個三元組中每個三元組的三元組向量表示的相似度,然后輸出以相似度作為元素的中間結果向量,以此來指示問題向量與答案向量的相似度。
步驟350的作用則是將問題向量和中間結果向量作為神經網絡系統的第三神經網絡模塊的輸入,將問題向量和中間結果向量進行綜合,計算獲得自然語言問題的自然語言答案。
下圖為該專利提供的具有人機對話功能的用戶設備的結構圖,包括處理器510、輸入設備520、存儲器530和輸出設備540,各組件通過總線系統550耦合在一起。
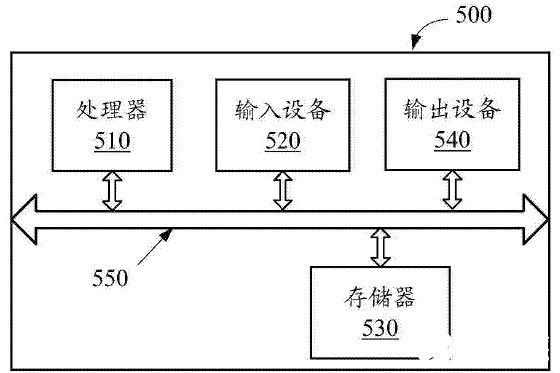
圖2
輸入設備520用于獲取用戶輸入的自然語言問題,存儲器530用于存儲由處理器510執行的指令。該處理器具有多種功能:
1.將問題向量和至少一個知識答案向量作為輸入,計算問題向量與每個知識答案向量的相似度;
2.知識答案向量為三元組向量時,將三元組的主語、謂語和賓語分別用第一獨熱向量、第二獨熱向量和第三獨熱向量表示;
3.將自然語言問題作為輸入,將自然語言問題的詞序列表示為低維向量序列;
將問題向量和中間結果向量作為輸入,計算以問題向量和中間結果向量作為條件的輸出序列的聯合概率,生成自然語言答案;
4.將問題向量和中間結果向量作為輸入,通過遞歸神經網絡模型,計算輸出序列的概率,生成自然語言答案。
該專利提供的用于人機對話的方法通過將自然語言問題和知識庫向量化,通過向量計算得到基于知識庫的,表示自然語言問題和知識庫答案相似度的中間結果向量,再根據問題向量和中間結果向量計算得到基于事實的正確的自然語言答案。該方法固然滿足不了用戶100%的滿意度,但他提高了人機對話中自然語言答案的準確性。
-
華為
+關注
關注
216文章
34477瀏覽量
252137 -
人機對話
+關注
關注
0文章
10瀏覽量
9597
發布評論請先 登錄
相關推薦
如何提高工程預算的準確性
怎么提高頻率測量的準確性
合同智能審核軟件-提高審查效率和準確性
如何提高投標報價編制的準確性
AI可提高天氣預報的準確性和準確性,助力農民和可再生能源行業
華為公開 “人機對話”相關專利:可根據對話內容生成準確回復
如何提高電流探頭的準確性與靈敏度
電流探頭測試小技巧:提高準確性和安全性






 工商網監
工商網監
評論