

作者:Preetum Nakkiran,Gal Kaplun,Yamini Bansal,Tristan Yang,Boaz Barak,Ilya Sutskever
編譯:ronghuaiyang
導讀
深度學習中的雙下降現象,可能大家也遇到過,但是沒有深究,OpenAI這里給出了他們的解答。
我們展示了 CNN,ResNet 以及 transformers 中的雙下降現象,隨著模型的尺寸,數據集的大小以及訓練時間的增加,performance 先提升,然后變差,然后再次提升。這種效果通常可以通過仔細的正則化來避免。雖然這種行為似乎是相當普遍的,但我們還沒有完全理解它為什么會發生,并把對這種現象的進一步研究作為一個重要的研究方向。
論文:https://arxiv.org/abs/1912.02292
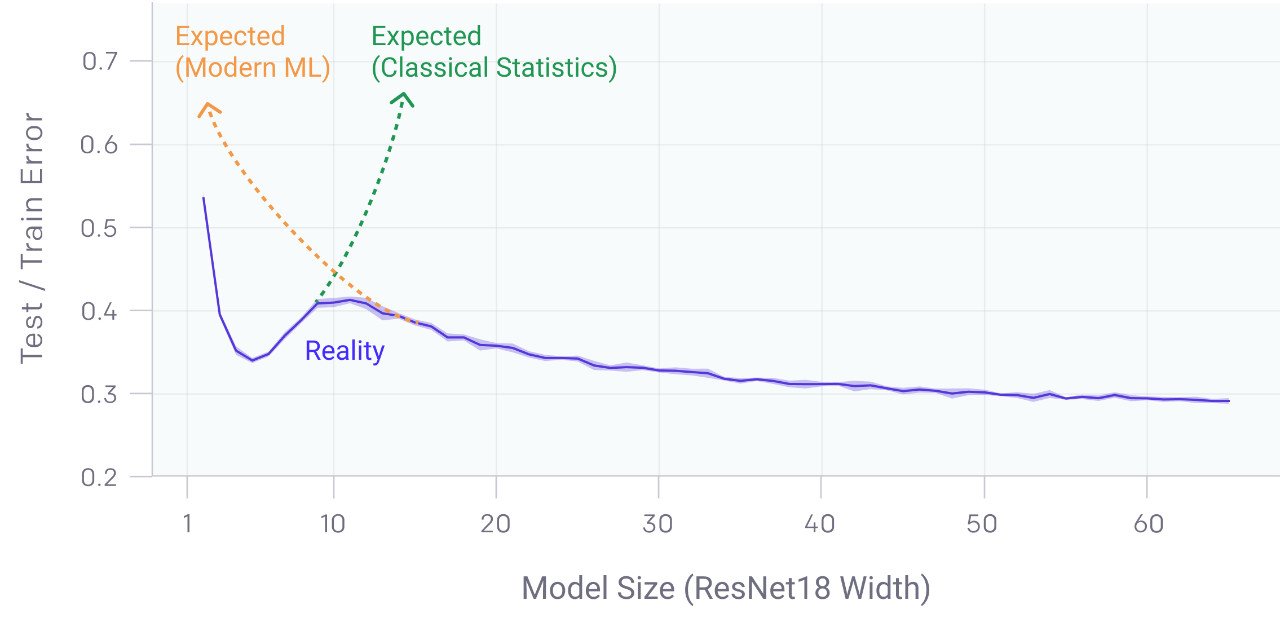
包括 CNNs、ResNets、transformer 在內的許多現代深度學習模型,在不使用 early stopping 或正則化時,都表現出之前觀察到的雙下降現象。峰值發生在一個可以預見的“特殊的時刻”,此時模型剛好可以去擬合訓練集。當我們增加神經網絡參數的數量,剛開始的時候,測試誤差減少,然后會增加,而且,模型開始能夠擬合訓練集,進行了第二次下降。
傳統統計學家認為“模型越大越糟”的傳統觀點,以及“模型越大越好”的現代機器學習范式,都沒有得到支持。我們發現雙下降也發生在訓練過程中。令人驚訝的是,我們發現這些現象會導致數據越多效果越差,此時在更大的訓練集上訓練一個深層網絡的效果實際上更差。
模型的雙下降
1. 在一段時間內,模型越大效果越差。
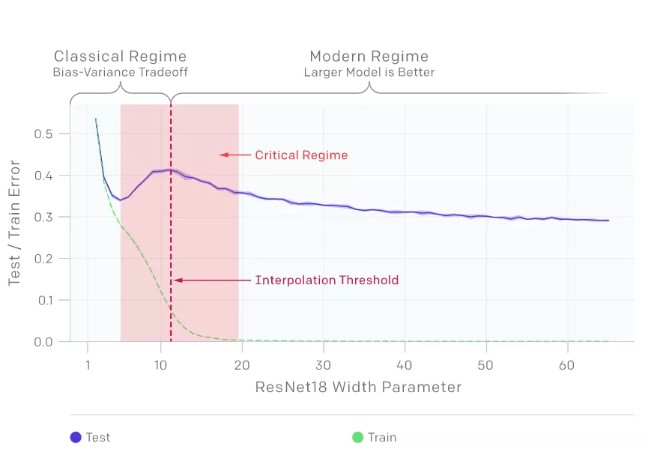
模型的雙下降現象會導致對更多數據的訓練效果越差。在上面的圖中,測試誤差的峰值出現在插值閾值附近,此時模型剛好足夠大到能擬合訓練集。
在我們觀察到的所有情況下,影響插值閾值的變化(如改變優化算法、訓練樣本數量或標簽噪聲量)也會相應地影響測試誤差峰值的位置。在添加標簽噪聲的情況下,雙下降現象最為突出,如果沒有它,峰值會更小,很容易被忽略。添加標簽噪聲會放大這種普遍的行為,讓我們可以很容易地進行研究。
樣本的非單調性
2. 在一段時間內,樣本越多效果越差。
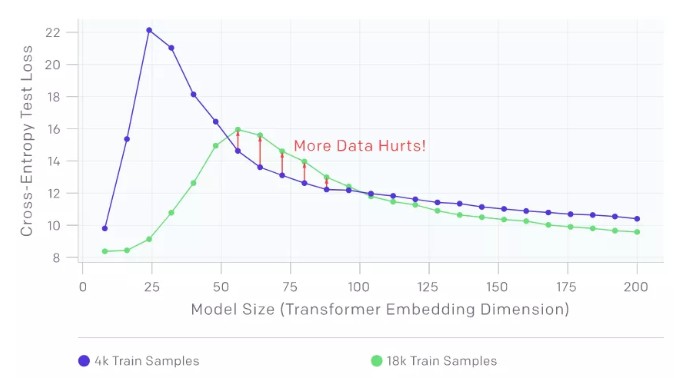
上面的圖顯示了在沒有添加標簽噪聲的情況下,在語言翻譯任務訓練的 transformers。正如預期的那樣,增加樣本數量會使曲線向下移動,從而降低測試誤差。然而,由于更多的樣本需要更大的模型來擬合,增加樣本的數量也會使插值閾值(以及測試誤差的峰值)向右移動。對于中等大小的模型(紅色箭頭),這兩個效果結合在一起,我們可以看到在 4.5 倍的樣本上進行訓練實際上會影響測試性能。
訓練 epoch 的雙下降
3. 在一段時間內,訓練時間越長,過擬合情況就越嚴重。
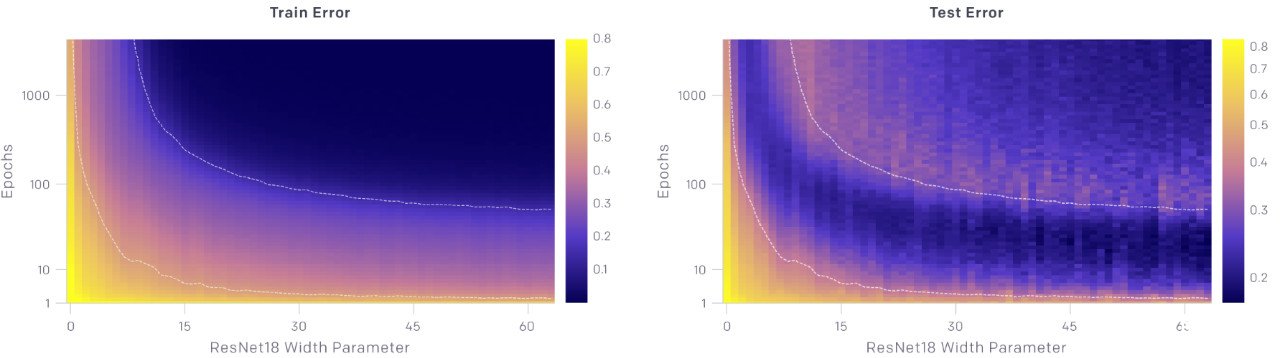
上面的圖顯示了測試和訓練誤差與模型大小和優化步驟數量的關系。對于給定數量的優化步驟(固定 y 坐標),測試和訓練誤差表現為隨著模型的大小出現了雙下降。對于給定的模型尺寸(固定的 x 坐標),隨著訓練的進行,測試和訓練誤差不斷地減小、增大、再減小,我們把這種現象稱為 epoch-wise 的雙下降。
一般情況下,當模型剛好能夠擬合訓練集時,會出現測試誤差的峰值
我們的直覺是,對于插值閾值處的模型,實際上只有一個模型正好擬合了數據集,而強迫它擬合即使是稍微有一點噪聲或錯誤的標簽也會破壞它的全局結構。也就是說,沒有既能在插值閾值處擬合訓練集又能在測試集上表現良好的“好模型”。然而,在參數化的情況下,有許多模型可以擬合訓練集,并且存在這樣的好模型。此外,隨機梯度下降法(SGD)的隱式偏差導致了這樣好模型出現,其原因我們還不清楚。
我們把對深層神經網絡的雙下降機制仍的充分認識作為一個重要的開放性問題。
-
深度學習
+關注
關注
73文章
5546瀏覽量
122280 -
cnn
+關注
關注
3文章
354瀏覽量
22563
發布評論請先 登錄
相關推薦
Nanopi深度學習之路(1)深度學習框架分析
什么是深度學習?使用FPGA進行深度學習的好處?
如何估算深度神經網絡的最優學習率(附代碼教程)
深度學習領域Facebook等巨頭在2017都做了什么
深度學習和機器學習深度的不同之處 淺談深度學習的訓練和調參
深度學習是什么?了解深度學習難嗎?讓你快速了解深度學習的視頻講解
深度強化學習已經達到了盡頭?
讀懂深度學習,走進“深度學習+”階段






 工商網監
工商網監

評論