") 為何++i比i++執(zhí)行效率高一些呢?
為何++i比i++執(zhí)行效率高一些呢?
背景
相信很多人遇到過這樣的問題:printf("%d,%d",i++,++i);
也糾結(jié)過這個問題,到底答案是什么。確沒有一個參考的資料。唯一知道的是,幾乎所有C語言教材都這么講:i++就是先使用i的值再使i自身加一,而++i則是先使i自身加一,然后在使用i的值。出于對真理的追求。今天我們徹底弄明白此問題。 譬如這樣的話:
int a,b;int i=10,j=10;a=i++;b=++j; 我們可以很清楚的知道a和b的值分別將是10和11。這點毫無疑問,因為無論在任何平臺任何編譯器上運行都是這個結(jié)果!
然而對于這樣的程序:
int a,b;int i=10,j=10;a=(i++)+(i++)+(i++);b=(++j)+(++j)+(++j); 各位試想答案將是多少?
我們可以放到編譯器上運行看一下結(jié)果如下:
先看看windows下常用的VC6結(jié)果:

恩看到了,是30和37!嗯,但..這個結(jié)果好像有點怪。
那再看看Linux下gcc的結(jié)果:

哦,竟然也是30 37 。
那我們再看看古老一點的TurboC的結(jié)果:
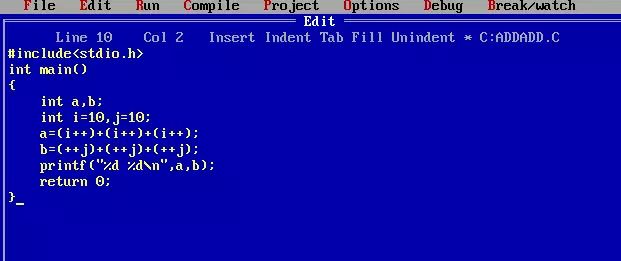

結(jié)果成了30 39 , 喔~還真有點怪。
當然,就C語言代碼來看,i++ 和 ++i 都只有一行,看起來似乎二者的執(zhí)行效率一樣了?其實不是的,在學(xué)習(xí)C語言時,教材和老師一般都會強調(diào) i++ 和 ++i 的區(qū)別,例如下面這段C語言代碼:
inti,j,k;i = 0;j = i++;i = 0;k = ++i;
這段C語言代碼執(zhí)行后,j 和 k 的值并不相等:j 等于 0,k 等于 1。既然執(zhí)行結(jié)果有差異,那么執(zhí)行效率很有可能也是有差異的,事實的確如此。查看上述C語言代碼對應(yīng)的匯編代碼,如下:
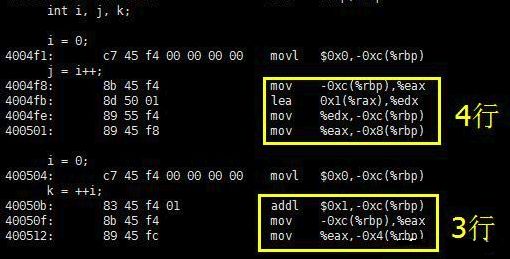
編譯器版本為gcc 4.8.4
可見,j=i++; 計算機需要 4 條指令來解釋,比執(zhí)行 k=++i; 多出了一條指令。多出的一條指令為:在對 i 執(zhí)行自加操作之前,先保存 i 的當前值留作稍后使用(賦值為j)。
這是怎么回事呢?不同的編譯器結(jié)果還不一樣呢?
而且這樣看來,似乎 ++i 的執(zhí)行效率比 i++ 高一些?
為何不同的編譯器結(jié)果不一樣
要說起這其中的原因,我們要先明白兩個知識點。即“副作用”與“順序點”。 這里我們引用《C Primer Plus》的說法:
“現(xiàn)在我們再討論一些C的術(shù)語。副作用(side effect)是對數(shù)據(jù)對象或文件的修改。
例如,語句:states = 50; 的副作用是將變量states的值設(shè)置為50。這是副作用?這看起來更像是主要目的!然而,從C的角度來看,主要目的是對表達式求值。給C一個表達式4+6,C將計算它的值為10。給C一個表達式states=50,C將計算它的值為50。計算這個表達式的副作用就是把變量states的值改變?yōu)?0。跟賦值運算符一樣,增量運算符和減量運算符也有副作用,它們主要由于副作用而被使用。
一個順序點(sequence point)是程序執(zhí)行中的一點;在該點處,所有的副作用都在進入下一步之前被計算。在C中,語句里的分號標志了一個順序點。它意味著在一個語句中賦值運算符、增量預(yù)算符及減量運算符所做的全部改變必須在程序進入下一個語句前發(fā)生。任何一個完整的表達式的結(jié)束也是一個順序點。
什么是完整的表達式呢?一個完整的表達式(full expression)是這樣一個表達式—-它不是一個更大的表達式的子表達式。完整的表達式的例子包括一個表達式語句里的表達式和在一個while循環(huán)里作為判斷條件的表達式。
順序點幫助闡明后綴增量動動作何時發(fā)生。例如,考慮下面的代碼:
while(guests++<10)printf(“%d ”,guests);? 有時C的初學(xué)者會設(shè)想在本程序中“先使用該值,然后增加它的值”的意思是在使用printf()語句后在增加guests的值。然而,因為guests++<10是while循環(huán)的判斷條件,所以它是一個完整的表達式,這個表達式的結(jié)束就是一個順序點。因此,C保證副作用(增加guests的值)在程序進入printf()前發(fā)生。同時使用后綴形式保證了guests在于10比較后才增加。
現(xiàn)在考慮這個語句:
Y=(4+ x++)+(6+ x++);
表達式4+x++不是一個完整的表達式,所以C不能保證在計算子表達式4+x++后立即增加x。這里,完整表達式是整個賦值語句,并且分號標記了順序點,所以C能保證的是在程序進入后續(xù)語句前x將增加兩次。C 沒有指明x是在每個子表達式被計算后增加還是在整個表達式被計算后增加,這就是我們要避免使用這類語句的原因。 這是《C Primer Plus》的說法,相信您應(yīng)該有一定答案了。
沒錯,那就是對于i=10;(++i)+(++i)+(++i);這樣的語句。C語言標準并沒有作規(guī)定。有的編譯器計算出來是39,因為會使i的值自增三次變?yōu)?3,然后使用增加三次之后也就是13的3個值相加為39。而有的編譯器計算結(jié)果則為37,如VisaulC++6.0則會先計算前兩個i的值為12,第三個i的值變成了加三次以后的值為13,因此結(jié)果是12+12+13=37。如果有心的話,您可以分別在VC6和TC上本別測試;(++i)+(++i)+(++i) +(++i)的值來洞悉不同編譯器的處理規(guī)則。
那么,回到最初的printf的問題,明白求值的順序之后,再來看printf的求值問題,printf的參數(shù)都是從左到右依次壓入棧內(nèi),所以計算起來求值運算的時候則是由右至左(棧的特點:即先進后出),那么至此,想必您已經(jīng)完全想明白了這類問題的全部了!
所以講到這里,想必大家就清楚緣由了,不同編譯器的處理過程是不同的。所以并沒有唯一的標準答案!現(xiàn)在大家明白了嗎?
為何++i比i++執(zhí)行效率高一些呢?
那為了寫出效率更高的C語言程序,以后是不是應(yīng)該盡量使用 ++i,而不是 i++ 了呢?例如下面這樣的C語言代碼:
for(i=0; i<10; i++);for(i=0; i<10; ++i);
是不是上面那行C語言代碼的執(zhí)行效率低于下面的呢?只能說理論如此,實際上,現(xiàn)代C語言編譯器已經(jīng)足夠聰明,它會根據(jù)上下文編譯C語言代碼。
應(yīng)該明白,i++ 和 ++i 的效率差異主要來自于處理 i++ 時,需要先保存 i 的當前值留作稍后使用。如果之后沒有人使用 i 的當前值,也就是說沒有C語言代碼讀取 i++ 的值,編譯器實在沒有必要保存 i 的當前值了,因此就會將這一步優(yōu)化掉。
為了便于分析,我們編寫下面這樣的C語言代碼:
int i = 0;i++;++i;
與上面的例子相比,區(qū)別在于在執(zhí)行 i++ 時,沒有人關(guān)心 i 的當前值了。查看這段C語言代碼對應(yīng)的匯編代碼:

顯然,i++ 和 ++i 對應(yīng)的指令是一模一樣的,不再有執(zhí)行效率上的差異。
C語言中的 i++ 和 ++i 是有區(qū)別的,這就有可能帶來效率上的差異。如果有代碼關(guān)心 i++ 執(zhí)行時的 i 當前值,程序在對 i 進行自加操作時,將不得不先保存 i 的當前值,而 ++i 就無需保存當前值,這就會帶來效率上的差異。如果沒人關(guān)心 i++ 的當前值,那么現(xiàn)代大多數(shù)C語言編譯器將會將這一差異優(yōu)化掉,此時 i++ 和 ++i 不再有效率上的差異。
-END-
-
Linux
+關(guān)注
關(guān)注
87文章
11322瀏覽量
209857 -
C語言
+關(guān)注
關(guān)注
180文章
7608瀏覽量
137135
原文標題:C語言靈魂拷問:++i為何比i++執(zhí)行效率高!有何區(qū)別?
文章出處:【微信號:gh_c472c2199c88,微信公眾號:嵌入式微處理器】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
天合光能重磅發(fā)布i-TOPCon Ultra技術(shù)
為什么下雨天手機信號比平時差一些
如何設(shè)計散熱效率高的集成BLDCM電機驅(qū)動PCB

物聯(lián)網(wǎng)中常見的I/O擴展電路設(shè)計方案_IIC I/O擴展芯片





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論