 電子發(fā)燒友App
電子發(fā)燒友App


前言
新型非易失存儲(chǔ)器正在逐漸成熟,有望在未來成為工作存儲(chǔ)器。然而,在工業(yè)實(shí)踐中,我們發(fā)現(xiàn)一些非易失存儲(chǔ)器,包含阻變隨機(jī)存儲(chǔ)器(RRAM)、相變隨機(jī)存儲(chǔ)器(PCM)和閃存(Flash)等在使用時(shí)會(huì)面臨使用耐久性有限的問題,即對(duì)于一個(gè)地址的寫入次數(shù)是有限的,而實(shí)際對(duì)存儲(chǔ)器進(jìn)行寫操作時(shí),往往會(huì)很頻繁的訪問部分地址,一旦存儲(chǔ)器任何部分的寫入次數(shù)超過了耐久極限,整個(gè)器件就會(huì)被認(rèn)為無法工作。因此,需要設(shè)計(jì)一些算法使得能對(duì)整個(gè)存儲(chǔ)器做均衡的訪問,而不是僅僅去對(duì)幾個(gè)特定的區(qū)域持續(xù)寫入,將對(duì)某些塊的操作分布到整片存儲(chǔ)器上,實(shí)現(xiàn)各塊寫入的平衡,這類算法就稱為損耗均衡(wear leveling)算法。
硬件損耗均衡算法簡介
硬件損耗均衡算法大致可以分為靜態(tài)和動(dòng)態(tài)損耗均衡。
動(dòng)態(tài)損耗均衡:這些算法通過重復(fù)使用擦除次數(shù)較少的塊來實(shí)現(xiàn)損耗平衡[1]。即當(dāng)下寫入地址的被寫入量超過規(guī)定的閾值時(shí)就讓其與一個(gè)認(rèn)為的寫入次數(shù)不大的地址做交換。然而對(duì)于原本就存在于那些被寫入次數(shù)不多的地址里面的數(shù)據(jù),不做移動(dòng)。
靜態(tài)損耗均衡:與動(dòng)態(tài)相反,靜態(tài)損耗均衡算法試圖通過整個(gè)物理地址的移動(dòng),從而促進(jìn)損耗的更均勻分布。
與動(dòng)態(tài)方法相比靜態(tài)方法優(yōu)勢(shì)在于空間開銷小,不需要考慮具體程序的動(dòng)態(tài)運(yùn)行也能達(dá)到延長存儲(chǔ)器壽命的目的,但正因?yàn)橛诖遂o態(tài)的方法不能充分的挖掘存儲(chǔ)器的生命潛力。而動(dòng)態(tài)方法借助記錄每個(gè)地址被寫入的次數(shù)、建立地址映射表、定期清理垃圾數(shù)據(jù)等方式,雖然存儲(chǔ)開銷相比靜態(tài)方法增加了但可以獲得更好地延長存儲(chǔ)器壽命的結(jié)果。當(dāng)然最好的均衡損耗算法一定是根據(jù)具體的應(yīng)用場(chǎng)景去相應(yīng)調(diào)整的,沒有最好的算法只有最適合的算法。
下面將先介紹一些靜態(tài)損耗均衡算法:
1.?基于 PCM 存儲(chǔ)器的 Start-Gap 算法[2]
借助兩個(gè)寄存器 Start、Gap 以及一個(gè)緩存區(qū),周期性將每一行(包括很多個(gè)地址,具體怎么劃分依照設(shè)計(jì)者的需求決定)移動(dòng)到其相鄰的位置來實(shí)現(xiàn)損耗均衡。實(shí)質(zhì)上就是建立了一個(gè)代數(shù)關(guān)系,完成邏輯地址到物理地址的映射。
Gap 記錄緩存區(qū)的物理地址,Start 記錄的是所有塊均移動(dòng)一次的次數(shù)。每當(dāng)寫入次數(shù)達(dá)到設(shè)定的閾值時(shí),通過 Gap 存儲(chǔ)的地址指引,將緩存區(qū)(圖中紅色塊)不斷向前移動(dòng),當(dāng)緩存區(qū)到達(dá)第一塊時(shí),下一次就移動(dòng)到最后一塊,如此循環(huán)。具體每一次移動(dòng)操作為(如圖1):
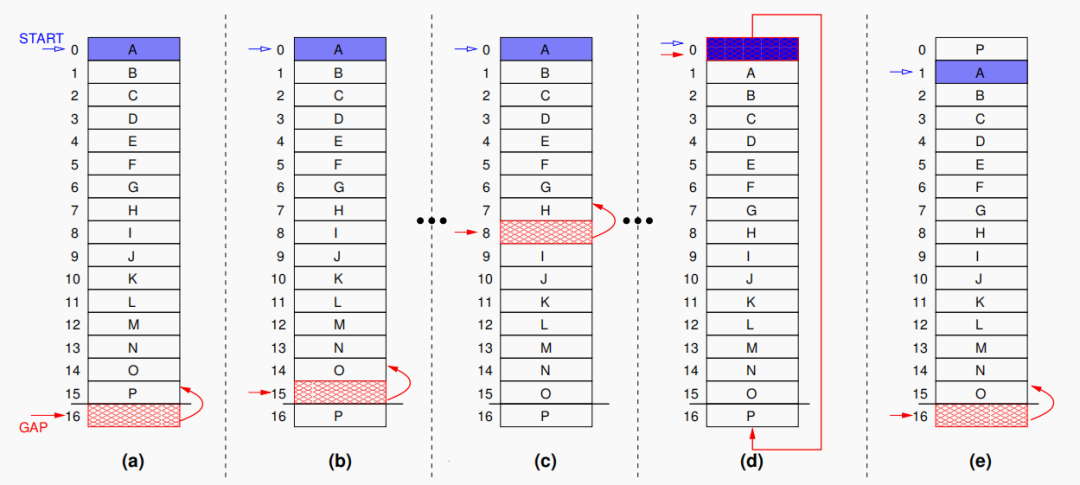
圖1:在一個(gè)包含16行的存儲(chǔ)器上進(jìn)行Start-Gap算法
邏輯地址(LA——logical address)與物理地址(PA——physical address)間的代數(shù)關(guān)系為:(N等于內(nèi)存中不包含緩沖區(qū)的行數(shù))
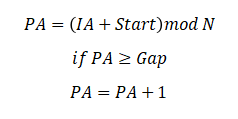
由于 CPU 在訪問寄存器時(shí),無論是存取數(shù)據(jù)還是存取指令,都趨于聚集在一片區(qū)域——局部性原理,可以看出僅依靠這樣相鄰位的移動(dòng),會(huì)將一個(gè)大量寫入的行移動(dòng)到另一個(gè)大量寫入的行,這可能導(dǎo)致早期的磨損。于是引入靜態(tài)地址隨機(jī)化,將原本連續(xù)的地址重映射為彼此間隔很大的新地址。
實(shí)現(xiàn)靜態(tài)隨機(jī)化處理可以借助隨機(jī)可逆的二進(jìn)制矩陣(Random Invertible Binary Matrix),如圖2,RIB 內(nèi)部的元素由0,1隨機(jī)序列,當(dāng)邏輯地址與該矩陣相乘后,可以使得原本連續(xù)的 LA 值分散開。
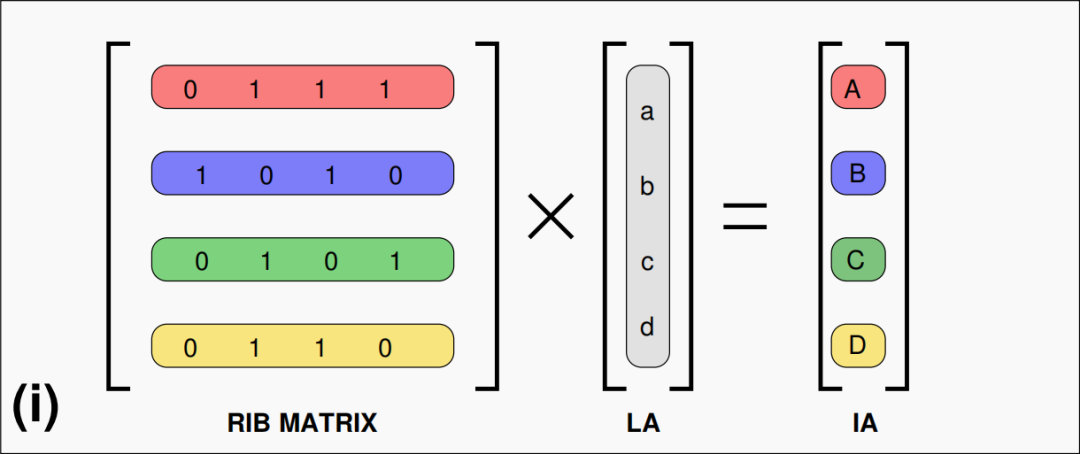
圖2:4位地址隨機(jī)化
綜上所述,完整的 Start-Gap 算法框架如圖3:
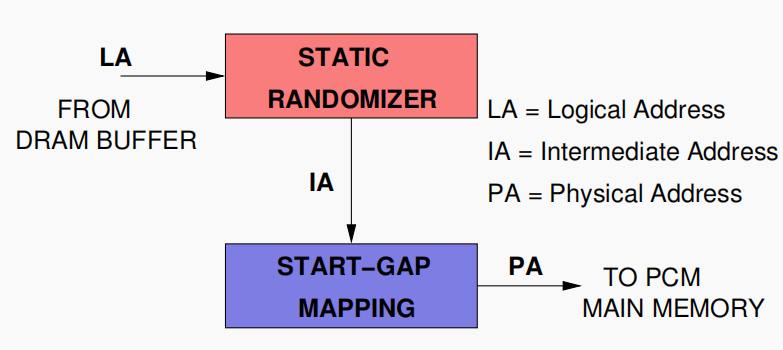
圖3:Start-Gap架構(gòu)
2.基于 RRAM 為主存儲(chǔ)器的細(xì)顆粒度均衡[3]
與上面介紹的 Start-Gap 算法思路比較相似,Start-Gap 算法是每到一個(gè)寫入閾值執(zhí)行一個(gè)行的數(shù)據(jù)遷移,而細(xì)顆粒度則是以時(shí)間為周期,每一周期將所有的地址均遷移一次,移動(dòng)間隔為一個(gè)隨機(jī)數(shù),每一周期生成一個(gè)新的隨機(jī)數(shù)。所謂細(xì)顆粒,意思就是均衡的對(duì)象是具體到每一個(gè)地址而不是將一些地址集合在一起視為一個(gè)整體來做處理。
3.?基于 Flash 的 SW Leveler 算法[4]
考慮 Flash 在更新數(shù)據(jù)時(shí)需要寫入另一個(gè)地址,將原地址標(biāo)記為無效(垃圾),需要擦除后才能繼續(xù)寫入。算法設(shè)計(jì)的目的就是讓存儲(chǔ)器的各個(gè)地址擦除次數(shù)分布均勻。
具體為:觸發(fā)清潔器對(duì)選定的區(qū)塊進(jìn)行垃圾收集,讓 SW 均衡器與塊擦除表(BET,建立的目的是記住哪個(gè)塊在預(yù)定的時(shí)間范圍內(nèi)被擦除,以便找到冷數(shù)據(jù)的地址。)相關(guān)聯(lián),以記住在選定的時(shí)間段內(nèi)哪個(gè)塊被擦除了。當(dāng) SW 均衡器運(yùn)行時(shí),它要么重置 BET,要么撿起一個(gè)至今未被擦除的塊(基于BET信息),并觸發(fā)清潔器對(duì)該塊進(jìn)行垃圾收集。區(qū)塊的選擇過程必須在有限的時(shí)間內(nèi)以有效的方式完成。每當(dāng)一個(gè)區(qū)塊被擦除時(shí),BET 同步更新。
4.?基于 Flash 的 Rejuvenator 算法[1]
Rejuvenator 的基本原則為防止區(qū)塊更快地達(dá)到其使用壽命,并使它們保持年輕,即保持區(qū)塊寫入次數(shù)不會(huì)很多。只有在 Flash 寫入次數(shù)達(dá)到設(shè)定閾值時(shí)才會(huì)積極地平衡,以此來最大限度地減少搬移冷數(shù)據(jù)(不經(jīng)常被訪問但是需要長期保存的數(shù)據(jù))的開銷,可用于大容量?Flash?的擴(kuò)展。
根據(jù)區(qū)塊當(dāng)前的擦除次數(shù)將其分為不同的組。
Rejuvenator 維護(hù)一個(gè)列表,將熱數(shù)據(jù)(經(jīng)常別訪問的數(shù)據(jù))放在編號(hào)較低的區(qū)塊中,將冷數(shù)據(jù)放在編號(hào)較高的區(qū)塊中。集群的范圍被限制在一個(gè)閾值內(nèi)。這個(gè)閾值是根據(jù)區(qū)塊的擦除次數(shù)來調(diào)整的。
每個(gè)區(qū)塊可以有三種類型的頁面:有效頁面、無效頁面和清潔頁面。有效頁包含有效的或活的數(shù)據(jù)。無效頁包含不再有效的數(shù)據(jù)。清潔頁不包含任何數(shù)據(jù)。
當(dāng)一個(gè)寫入操作到來時(shí),如果該邏輯地址有一個(gè)現(xiàn)有的映射(映射的物理塊中的相應(yīng)頁面將是空閑或無效的)。數(shù)據(jù)將被寫入映射的物理塊中的相應(yīng)頁面。如果沒有與 LBA 相關(guān)的塊映射,它將被寫到屬于較高編號(hào)列表的一個(gè)干凈的塊中。
此外還有一些已被提出來并且獲得了不錯(cuò)效果的動(dòng)態(tài)損耗均衡算法:
1.?基于硬件損耗均衡的 Flash 控制器[5]
將 Flash 中的塊分為三類,空閑塊,有效塊和垃圾塊。空閑塊指的是尚未被使用,可以直接寫入新數(shù)據(jù)的塊。有效塊指的是該塊中存放著有效數(shù)據(jù),該塊的地址已存在與地址映射表(記錄物理地址和邏輯地址映射關(guān)系的表格)中,存放的數(shù)據(jù)為最新寫入的正確的數(shù)據(jù)。垃圾塊指該塊中存放的數(shù)據(jù)已經(jīng)無效,之前對(duì)應(yīng)該塊的地址已經(jīng)被映射到新的物理地址。
動(dòng)態(tài)損耗均衡主要關(guān)注的是保證每次寫操作都會(huì)寫入到Flash中擦除(每次對(duì)一個(gè)塊寫入時(shí)需要先將原有的數(shù)據(jù)擦除掉才能寫入)次數(shù)最小的空閑塊中,從而避免某些塊被擦寫過多。
具體過程為:寫操作到來時(shí),在空閑塊中找出擦除次數(shù)最小的塊,將其物理地址與收到的邏輯地址相對(duì)應(yīng),并存放在地址映射表中,同時(shí)將該邏輯地址原來對(duì)應(yīng)的物理地址塊標(biāo)記為垃圾塊,最后就將需要寫入的數(shù)據(jù)寫入到新的物理地址塊中。
2.基于PCM的雙重布隆濾波器(DLBF)算法[6]
上面介紹的基于?Flash?算法中提及了空閑塊、有效塊和垃圾塊的概念,與之相近的有冷地址和熱地址的概念,顧名思義,熱是指該地址被頻繁訪問,冷地址定義與之相反。
DLBF 算法借用 Bloom Filter(一種空間效率很高的隨機(jī)數(shù)據(jù)結(jié)構(gòu),它利用位數(shù)組很簡潔地表示一個(gè)集合,并能判斷一個(gè)元素是否屬于這個(gè)集合。)來識(shí)別讀、寫熱頁。
將布隆濾波器映射得到的布隆表的每一位擴(kuò)展為一個(gè)計(jì)數(shù)器就能記錄每個(gè)地址被寫入的次數(shù)從而能根據(jù)閾值(閾值是會(huì)隨著時(shí)間改變的以此來提高識(shí)別的正確率)與計(jì)數(shù)器記錄的數(shù)據(jù)大小來判斷該地址是否為熱地址。以此來建立一個(gè)候選表(記錄現(xiàn)有的冷頁),每次寫操作到來時(shí),先判斷這個(gè)地址是否已經(jīng)存在于地址映射表中,如果不在則先更新布隆表,然后判斷該地址是否為需要做交換的熱地址,如果是則將它與候選表中的冷地址做交換并更新地址映射表,如果不是熱地址則執(zhí)行正常的寫操作即可。
3.基于年齡的PCM損耗均衡算法[7]
算法的核心思想也是令熱地址與冷地址交換。但不需要維護(hù)一個(gè)候選表而是通過一個(gè)指針始終指向沒有被檢測(cè)到的所有頁面中最前的那個(gè)。總的來說就是利用指針的均勻移動(dòng)使得所有地址都可以被均勻地使用,指針就像一個(gè)領(lǐng)隊(duì)員帶領(lǐng)著每一個(gè)寫入請(qǐng)求命令去到合適的地方。
4.基于PCM的動(dòng)態(tài)損耗均衡算法[8]
同樣借助于布隆濾波器,根據(jù) EV(電子伏特)和寫入數(shù)量來選擇要交換的數(shù)據(jù)。動(dòng)態(tài)管理布隆濾波器來提高所使用的濾波器的有效性(即通過動(dòng)態(tài)更新寫數(shù)來避免計(jì)數(shù)器溢出),判斷地址是否為熱的閾值yes1動(dòng)態(tài)變化的。
采用一種動(dòng)態(tài)的冷熱列表(HCL)管理方法,試圖在 HCL 中保留盡可能長的熱邏輯地址(因此,減少交換開銷),同時(shí)從列表中刪除冷地址。
除此之外相關(guān)研究人員還從其他方向提出了實(shí)現(xiàn)損耗均衡的方法,例如:用新的緩存替換策略使回寫最小化以及避免不必要的寫,只寫實(shí)際改變的位單元[9]。通過在選擇替換頁時(shí),優(yōu)先選擇一個(gè)未被修改過的頁面進(jìn)行替換。盡可能讓頻繁修改的頁面長期保持在緩存中。方案中避免非必要的寫操作策略通過分頁技術(shù)和“讀—寫—讀”存儲(chǔ)頁差異識(shí)別方法實(shí)現(xiàn)。
對(duì)于上面動(dòng)態(tài)損耗均衡算法中提及的垃圾數(shù)據(jù)處理,也有人提出了以最小化清理成本的損耗算法——CAT(cost?age?times)算法[10],將 memory 細(xì)分為固定大小的塊。每一段有一個(gè) segment header 來描述塊信息,該信息被用來加快清潔器加快選擇段進(jìn)行清潔,當(dāng)所有空閑段的數(shù)量低于一定閾值時(shí),清潔器開始工作,在清理時(shí),被清理段中的有效冷數(shù)據(jù)被遷移至專門存放冷數(shù)據(jù)的段中。同理有效熱數(shù)據(jù)被遷移至專門存放熱數(shù)據(jù)的段。這樣分別聚集,清理這些熱數(shù)據(jù)可以將遷移成本降到最低,因?yàn)楸粡?fù)制的有效數(shù)據(jù)量最少,而回收的垃圾量最大。CAT 算法的基本思想是最小化清理成本,給剛清理過的段更多時(shí)間來積累垃圾,以避免無用的遷移。
包括廣泛使用的布隆濾波器,關(guān)于它也有很多衍生的算法,例如在管理計(jì)數(shù)器時(shí),因?yàn)椴煌刂窌?huì)公用一個(gè)計(jì)數(shù)器,那么如果每次都將一個(gè)地址對(duì)應(yīng)的所有計(jì)數(shù)器值都加一,這樣會(huì)增加將冷地址誤判為熱地址的概率。為了解決這個(gè)問題,除了動(dòng)態(tài)調(diào)整判斷閾值,還可以令每次只有值最小的計(jì)數(shù)器加一。
識(shí)別冷熱地址的方式其實(shí)很簡單,就把地址被訪問的次數(shù)記錄下來即可,問題就在于我們無法事先得知誰會(huì)是熱地址,所以在給每個(gè)地址分配計(jì)數(shù)器時(shí)預(yù)留的空間都必須按照熱地址的寫入次數(shù)賦予,但實(shí)際上熱地址所占整個(gè)地址的比例不會(huì)很大,這樣就會(huì)造成很大的空間資源浪費(fèi),而往往我們需要集成密度大的電路這樣的存儲(chǔ)開銷是有些不合理的,所以才產(chǎn)生了各種各樣以減少存儲(chǔ)開銷的算法。
總結(jié)
總的來說,損耗均衡算法都是通過各種方式在寫入操作會(huì)集中在一些地址的情況下通過監(jiān)督地址的寫入情況或者直接在物理地址層面進(jìn)行額外的數(shù)據(jù)遷移的方式來使得經(jīng)常被訪問的地址塊的損耗分擔(dān)到那些不怎么經(jīng)常被訪問的塊。
均衡損耗算法雖然不能提升存儲(chǔ)器實(shí)際的壽命,但可以提高存儲(chǔ)器實(shí)際使用壽命,對(duì)于存儲(chǔ)器的應(yīng)用具有很大的意義。
需要提醒的是本文著重于介紹各個(gè)算法的設(shè)計(jì)思路,沒有具體提及、分析其功耗,時(shí)間、空間復(fù)雜度,實(shí)際電路所占面積等,而這些在實(shí)際的整體系統(tǒng)設(shè)計(jì)中同樣是重要的。誠然我們要實(shí)現(xiàn)一些功能總是會(huì)以其他功能受到影響為代價(jià),比如加入了均衡損耗模塊會(huì)使得寫操作的延時(shí)增加,降低了 CPU 訪問存儲(chǔ)器的速度但是延長了存儲(chǔ)器的壽命,所以還是回到介紹各個(gè)算法前說的,最好的算法一定是根據(jù)具體應(yīng)用場(chǎng)景去設(shè)計(jì)、調(diào)整的。??
//?參考文獻(xiàn)?//
[1] Murugan M, Du D H C. Rejuvenator: A static wear leveling algorithm for NAND flash memory with minimized overhead[C]//2011 IEEE 27th Symposium on Mass Storage Systems and Technologies (MSST). IEEE, 2011: 1-12.
[2] Qureshi M K, Karidis J, Franceschini M, et al. Enhancing lifetime and security of PCM-based main memory with start-gap wear leveling[C]//2009 42nd Annual IEEE/ACM international symposium on microarchitecture (MICRO). IEEE, 2009: 14-23.
[3] Grossi A, Vianello E, Sabry M M, et al. Resistive RAM endurance: Array-level characterization and correction techniques targeting deep learning applications[J]. IEEE Transactions on Electron Devices, 2019, 66(3): 1281-1288.
[4] Chang Y H, Hsieh J W, Kuo T W. Endurance enhancement of flash-memory storage systems: An efficient static wear leveling design[C]//Proceedings of the 44th annual Design Automation Conference. 2007: 212-217.
[5] 徐書韜.基于硬件損耗均衡算法的片上Nor Flash控制器設(shè)計(jì)[D].杭州:浙江大學(xué),2017.
[6] Niu N, Fu F, Yang B, et al. DLBF: A low overhead wear leveling algorithm for embedded systems with hybrid memory[J].Microelectronics Reliability, 2021, 123: 114154.
[7] Chen C H, Hsiu P C, Kuo T W, et al. Age-based PCM wear leveling with nearly zero search cost[C]//Proceedings of the 49th Annual Design Automation Conference. 2012: 453-458.
[8] Yun J, Lee S, Yoo S. Dynamic wear leveling for phase-change memories with endurance variations[J]. IEEE Transactions on Very Large Scale Integration (VLSI) Systems, 2014, 23(9): 1604-1615.
[9] Ferreira A P, Zhou M, Bock S, et al. Increasing PCM main memory lifetime[C]//2010 Design, Automation & Test in Europe Conference & Exhibition (DATE 2010). IEEE, 2010: 914-919.
[10] Chiang M L, Chang R C. Cleaning policies in mobile computers using flash memory[J]. Journal of Systems and Software, 1999, 48(3): 213-231.
編輯:黃飛
?









 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論