 電子發(fā)燒友App
電子發(fā)燒友App


隨著多年微服務(wù)的發(fā)展,分布式追蹤系統(tǒng)已經(jīng)成為云原生技術(shù)棧中非常引人注目的一個領(lǐng)域。隨著該技術(shù)的出現(xiàn),你可以非常容易的去定位分布式系統(tǒng)中潛在的一些問題。在這篇文章之中,我會詳細為大家介紹什么是分布式追蹤系統(tǒng),以及如何存儲分布式追蹤系統(tǒng)產(chǎn)生的數(shù)據(jù)。
我首先會沿著歷史的脈絡(luò),介紹經(jīng)典的大數(shù)據(jù)方案來解決分布式追蹤系統(tǒng)的數(shù)據(jù)存儲與分析的問題,而后會繼續(xù)分析目前業(yè)界常用的混合方案來解決相關(guān)問題。最后面向未來,我將提出一種混合的一體化方案來解決此類問題。
什么是分布式追蹤系統(tǒng)
在我們正式介紹分布式追蹤系統(tǒng)之前,我們需要探究一下分布式對于整個業(yè)界到底意味著什么。我們可以下這樣一個矛盾的結(jié)論:分布式把事情變得非常的簡單,同時也把它變得很復(fù)雜。我們聽過越來越多的案例,在使用分布式系統(tǒng)之后,雖然整個系統(tǒng)看起來結(jié)構(gòu)清晰,路徑明確,并帶來了一定效率的提升。但越來越復(fù)雜的分布式結(jié)構(gòu)增加了系統(tǒng)的復(fù)雜程度,同時給運維、管理、架構(gòu)等等幾乎所有方面帶來了非常大的挑戰(zhàn)。
我們傾向于將越來越多的組件引入到已經(jīng)很復(fù)雜的分布式系統(tǒng)之中來解決以上這些問題。這些組件和管理它們的組件一起組成了更加復(fù)雜的分布式系統(tǒng)。這些系統(tǒng)最終會反噬我們,并給我們帶來意想不到的問題。甚至于是非常重大的一些災(zāi)難。
?
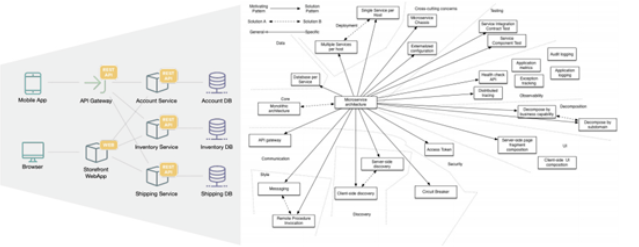
如圖是一個典型的電商類的系統(tǒng)。從這個結(jié)構(gòu)圖上看,這個系統(tǒng)東西向和南北向都是非常的復(fù)雜的。它由一個前端的系統(tǒng)來承接用戶的訪問,其中包含了移動端和瀏覽器過來的流量。這些流量通過API的網(wǎng)關(guān)到達了賬戶系統(tǒng)、庫存系統(tǒng)和快遞系統(tǒng)。前端系統(tǒng)同時與后端系統(tǒng)進行相連,后端系統(tǒng)由各個子域所組成,它們共同構(gòu)成了一個非常復(fù)雜的網(wǎng)絡(luò)拓撲結(jié)構(gòu)。
在如此復(fù)雜的網(wǎng)絡(luò)拓撲結(jié)構(gòu),我們不能單單以傳統(tǒng)的運維方案去做監(jiān)控,管理和觀測。而是需要引入一定的現(xiàn)代技術(shù),特別是跟蹤技術(shù),來將一條完整的調(diào)用鏈呈現(xiàn)到管理者和運維者面前。
通過跟蹤技術(shù),我們可以觀測到系統(tǒng)的兩個重要的指標(biāo),一個是請求失敗,我們可以發(fā)現(xiàn)系統(tǒng)在哪個部分存在比較致命的問題,鏈路從何處斷開的。另一個就是延遲。它是無處不在的,即使你花費巨大的代價,也不可以避免延遲。
現(xiàn)在,讓我們深入到追蹤系統(tǒng)的內(nèi)部,觀察追蹤數(shù)據(jù)的數(shù)據(jù)結(jié)構(gòu)。如圖所示追蹤系統(tǒng)所產(chǎn)生的是一些點,這些點可以代表一個時間片段,它的英文是Span。Span描述的就是一次調(diào)用所跨越的一個時間范圍。
?
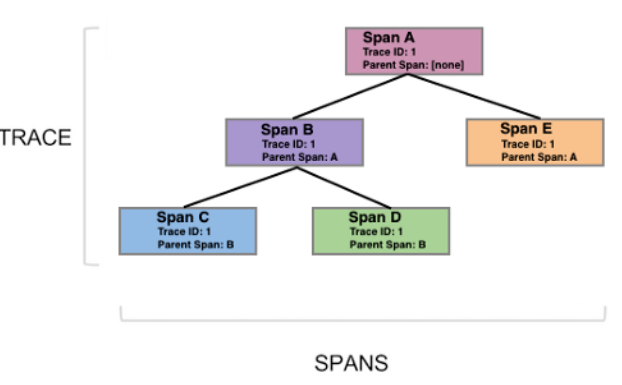
那么Span與Span之間是組成一個這樣的樹形的結(jié)構(gòu),這棵樹反映的是服務(wù)之間的一個調(diào)用過程。而另一張圖我們習(xí)慣于成為瀑布圖,它更加能夠反映Span之間的一個對應(yīng)關(guān)系。
?
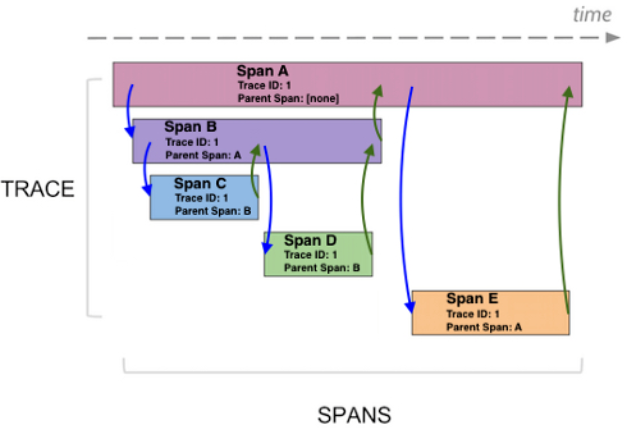
它與樹型圖最顯著的區(qū)別是,瀑布圖可以體現(xiàn)Span之間的隸屬關(guān)系。我們看到其中 SpanA是一個父節(jié)點,其包含其他三個Span。而其他Span之間有一定的并行關(guān)系。我們從中可以看到SpanB與SpanC之間是并行的,與SpanD也是并行的。而SpanE與其他Span之間是個串行關(guān)系。這張圖不僅可以告訴我們Span之間的對應(yīng)關(guān)系,而且可以顯示這次調(diào)用它到底是一種并行調(diào)用還是串行調(diào)用。
既然Span是跟蹤系統(tǒng)的核心數(shù)據(jù),同時這篇文章主要的目的是要探究如何去存儲跟蹤數(shù)據(jù),那么探究如何去存儲Span就是我們需要研究的必要課題。
讓我們看看Span的一些具體結(jié)構(gòu),經(jīng)典的Dapper論文所描述Span結(jié)構(gòu)包括SpanId,父SpanId,還有它的Trace Id。而后是一組labels,這是一些key-value結(jié)構(gòu),類似于我們傳統(tǒng)的數(shù)據(jù)表的一行數(shù)據(jù),它與傳統(tǒng)數(shù)據(jù)表不同點是:傳統(tǒng)數(shù)據(jù)表的列是預(yù)定義的,而這種key-value結(jié)構(gòu)是根據(jù)數(shù)據(jù)動態(tài)定義的,所以它的整個長度是任意的,這一點對存儲來說是比較大的挑戰(zhàn)。
?
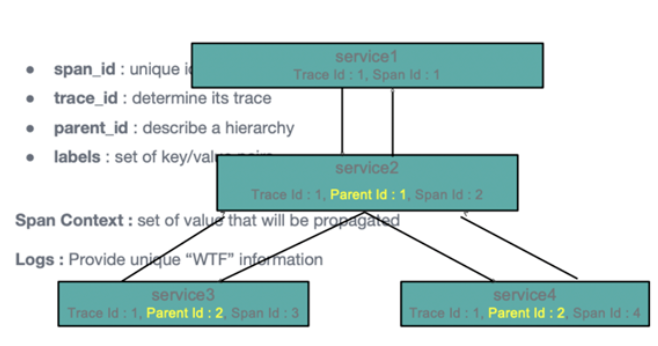
另外Span中還要存儲一些非結(jié)構(gòu)化數(shù)據(jù),所以它又帶有NoSQL數(shù)據(jù)的特點。同時它又具有典型的時間維度的特征,而這又是典型的時間序列數(shù)據(jù)的特點。這就是跟蹤數(shù)據(jù)的特點:一種混合的多模式結(jié)構(gòu)。
經(jīng)典的大數(shù)據(jù)存儲方案
經(jīng)典的跟蹤系統(tǒng)存儲其實就來自經(jīng)典的跟蹤系統(tǒng)論文:Dapper。這篇論文中還詳細描述了Google所采用的一種跟蹤系統(tǒng)的實現(xiàn)方案。這篇經(jīng)典論文不僅描述了經(jīng)典的以annotation為基礎(chǔ)的數(shù)據(jù)結(jié)構(gòu),而且它同時還提出了使用BigTable來作為整個跟蹤系統(tǒng)的存儲底層。
既然提到了BigTable,那就讓我們一起去探究目前BigTable的一些特性,看看為什么早期的跟蹤系統(tǒng)采用這種存儲結(jié)構(gòu)。目前該產(chǎn)品已經(jīng)云化了,我們可以很容易的去購買這個服務(wù),去體驗它的功能特性。
BigTable有三種比較主要的特性:
l 第一個它是NoSQL數(shù)據(jù)庫。在上一節(jié)中我們提到,由于跟蹤系統(tǒng)內(nèi)部存在著大量的非結(jié)構(gòu)數(shù)據(jù),而這些數(shù)據(jù)來源于用戶自定義。這里的用戶其實包括兩類,第一類就是跟蹤系統(tǒng)的設(shè)計者,它會增加多種字段來構(gòu)成數(shù)據(jù)的底層。再此之上就是跟蹤系統(tǒng)的使用者,他們會根據(jù)自己的業(yè)務(wù)場景再添加另外一些動態(tài)的字段進來。故一個天然的NoSQL的非結(jié)構(gòu)化數(shù)據(jù)庫是對這種任意字段類型的數(shù)據(jù)結(jié)構(gòu)是有益的。
l 第二個特性就是存儲要支持高吞吐。在一個微服務(wù)場景之中,每一個子Span的粒度是代表一個服務(wù)內(nèi)部的一個調(diào)用。但是這個調(diào)用可大可小,可以是對這個服務(wù)進程的調(diào)用,也可以是進程內(nèi)部一個函數(shù)的調(diào)用。可以說,一次外部的業(yè)務(wù)調(diào)用可以產(chǎn)生海量的跟蹤數(shù)據(jù)。這就是跟蹤系統(tǒng)面臨的典型挑戰(zhàn)—數(shù)據(jù)放大。跟蹤系統(tǒng)需要極大的帶寬,同時對延遲也有非常敏感。綜上,一個可以支持大數(shù)據(jù)的數(shù)據(jù)庫對跟蹤系統(tǒng)是非常有利的。
l 第三個特性性能線性增長。由于業(yè)務(wù)系統(tǒng)是逐步接入到跟蹤系統(tǒng)之中的,就需要存儲方案支持系統(tǒng)平滑的提高吞吐量和存儲空間。不能因為新數(shù)據(jù)的接入,造成現(xiàn)有數(shù)據(jù)的寫入和查詢出現(xiàn)性能的劇烈下降。
以上就是BigTable作為第一代非常經(jīng)典的分布式跟蹤存儲解決方案所提供的主要特性。
?
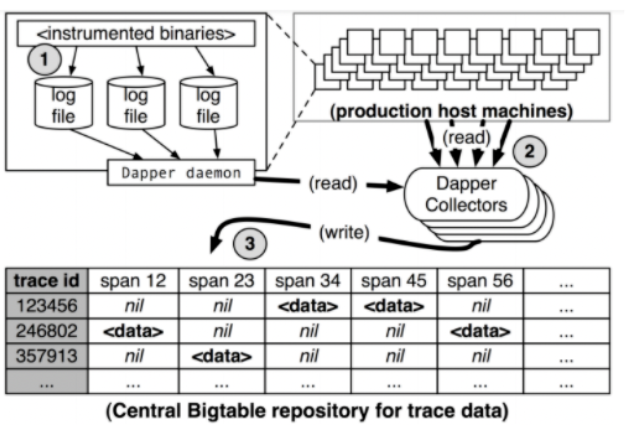
如圖所示一個跟蹤結(jié)構(gòu)是如何進入到BigTable之中。第一個過程,跟蹤系統(tǒng)會生成一個本地的日志文件,日志文件包括了所有的Span,而后由一個搜集器將這些數(shù)據(jù)拉取到一個與之最近的BigTable節(jié)點之中。而后由Dapper的寫入器,將數(shù)據(jù)寫入到 Big Table的每個Cell中。其中,每行代表一個Trace ,也就是一次調(diào)用產(chǎn)生的全部Span可以一次性提取出來。
我們都知道BigTable是個商用的云數(shù)據(jù)庫。如果想自己去打造一個面向跟蹤場景的經(jīng)典存儲方案,開源界也提供了有很多的選擇,比如說Cassandra,HBase等。
但是經(jīng)典的分布式跟蹤系統(tǒng)非常大的問題就是投入產(chǎn)出比較低。因為我們知道跟蹤系統(tǒng)屬于二線系統(tǒng),也是監(jiān)控系統(tǒng)的一個延伸。雖然隨著微服務(wù)的產(chǎn)生,此類系統(tǒng)的地位有了比較顯著的提高,但其重要性依然低于一線生產(chǎn)系統(tǒng)。
那么采用這種經(jīng)典的大數(shù)據(jù)方案的性價比是非常低的。你會投入很多的資源在跟蹤系統(tǒng)中,但是產(chǎn)生的效果并不能夠與你投入的資源相對稱。甚至是說你投入的非常多,產(chǎn)生效果是非常差的。這個時候你會對它的可用性和實際作用產(chǎn)生深深的懷疑。
現(xiàn)代的混合方案
這部分讓我們了解現(xiàn)代混合存儲方案。相比于傳統(tǒng)的大數(shù)據(jù)結(jié)構(gòu),現(xiàn)代混合存儲結(jié)構(gòu)更強調(diào)于性價比和易用性。目前主流的有兩種典型的存儲方案:
第一種就是關(guān)系型數(shù)據(jù)庫,以MySQL為代表。
那么,首先讓我們了解一下MySQL。當(dāng)然這其中包括其他的一些關(guān)系型數(shù)據(jù)庫。傳統(tǒng)的關(guān)系型數(shù)據(jù)庫是面向于查詢優(yōu)化的,所以它的寫入性能相較于查詢性能是較低的。故傳統(tǒng)上它并不適合于做跟蹤類的存儲方案。
但是我們可以把關(guān)系數(shù)據(jù)庫進行一些改造。這里有兩個改造方面,第一點是使用一些Sharding中間件來增強MySQL吞吐量。如Apache ShardingSphere。
這樣就滿足了上文所提到的兩個關(guān)鍵點:高的吞吐和性能線性。
高吞吐很容易理解,這是sharding的主要策略。那么性能線性如何理解呢?
一個Trace 內(nèi)部的Span是有一定的關(guān)聯(lián)關(guān)系的,但是Trace 和Trace 之間是相對于獨立的。那么通過sharding策略,整體的數(shù)據(jù)會較為離散的。這就可以滿足對性能線性增長的需求。因為我們知道影響sharding效果的一個最重要的原因就是關(guān)系的耦合。如果數(shù)據(jù)之間關(guān)系特別的緊密,那么你很難做到數(shù)據(jù)寫入性能的線性增長。
最后,對于數(shù)據(jù)的任寫入,我們可以通過預(yù)設(shè)冗余字段的方式來解決。當(dāng)然任意數(shù)據(jù)并不能像大數(shù)據(jù)的存儲方案一樣可以無限寫入任意數(shù)據(jù)。但這種預(yù)設(shè)方案在性能上反而有更大的優(yōu)勢。
剛才提到了兩種增強關(guān)系數(shù)據(jù)結(jié)構(gòu)的方案,那么我們?yōu)槭裁匆欢ㄒx擇這種關(guān)系數(shù)據(jù)庫作為跟蹤數(shù)據(jù)的存儲方案呢?
第一點就是像這種數(shù)據(jù)庫有大量的dba支持。所以我們很容易的將它的性能提到一個非常驚人的地步。甚至于有一些組織,比如說像TimeScale,就是利用關(guān)系數(shù)據(jù)庫來做時序數(shù)據(jù)庫的存儲跟蹤數(shù)據(jù)的。他們就是看中了這種關(guān)系數(shù)據(jù)庫優(yōu)秀的成熟度。
那么如果要用MySQL去存儲關(guān)系數(shù)據(jù),需要做額外哪些調(diào)整呢?
l 第一點,增強寫入性能。最簡單的方式是要增加buffer的大小。同時,對數(shù)據(jù)庫Engine做一相關(guān)的優(yōu)化。比如增加buffer pool的一個大小,然后我們需要對數(shù)據(jù)塊的刷入策略進行一些調(diào)節(jié)。
l 第二點,增加數(shù)據(jù)的生命周期管理功能。因為一些老數(shù)據(jù)會出現(xiàn)隨著時間的流逝而價值降低的現(xiàn)象。需要增加數(shù)據(jù)生命周期管理功能來釋放磁盤空間。
l 第三點,分離流量。因為我們寫入量是巨大的,但讀取是相對少的。這與經(jīng)典的關(guān)系數(shù)據(jù)庫場景是非常不同的,我們需要把寫入流量和讀取流量進行分離,以免讀取流量影響寫入流量。
第二個常用的存儲結(jié)構(gòu)也是搜索引擎。以Elasticsearch為代表的搜索引擎對于日志搜集有比較好的支持,所以有相當(dāng)一部分的跟蹤系統(tǒng)都會采用這種搜索引擎來存儲跟蹤數(shù)據(jù)。那么跟蹤數(shù)據(jù)本質(zhì)上與log是非常相似的。因為log具有體量巨大,字段任意等跟蹤數(shù)據(jù)的顯著特點。它唯一與跟蹤數(shù)據(jù)的區(qū)別是 log沒有很強的關(guān)聯(lián)性。故如Elasticsearch和Loki這類系統(tǒng)都可以滿足存儲跟蹤數(shù)據(jù)的要求。
此類數(shù)據(jù)庫具有兩個相對優(yōu)勢的特性:
l 第一,支持大量的非結(jié)構(gòu)數(shù)據(jù)存儲。因為這種系統(tǒng)天生就是一個分布式數(shù)據(jù)庫,它不像關(guān)系數(shù)據(jù)庫需要一些中間件的加持。這種數(shù)據(jù)庫天然可以存儲大量的數(shù)據(jù)。而且他們對寫入有特殊優(yōu)化,這樣就可以快速的存儲數(shù)據(jù)。
l 第二,高效的數(shù)據(jù)分析。數(shù)據(jù)之間的關(guān)系可以很容易的在此類系統(tǒng)中進行分析。因為它動態(tài)產(chǎn)生索引結(jié)構(gòu),非常適合于這種交互式的跟蹤數(shù)據(jù)分析場景。
如果你要使用Elasticsearch來存儲跟蹤數(shù)據(jù)。需要進行以下優(yōu)化:
l 第一,需要實時的監(jiān)控磁盤的使用情況。因為索引寫到一定程度,Elastcsearch就會將一些索引轉(zhuǎn)化為只讀索引,這樣的話會導(dǎo)致你的最新的高價值數(shù)據(jù)寫不進去。
l 第二,由于你的寫入量是非常大的,你要像關(guān)系數(shù)據(jù)庫一樣去增加它的Buffer,同時增加寫入的隊列的大小。
l 第三,Elasticsearch是分布式的數(shù)據(jù)庫,它自帶數(shù)據(jù)復(fù)制的功能。但是對于跟蹤數(shù)據(jù),數(shù)據(jù)復(fù)制往往是多余的。因為這是一個寫多讀少的一個場景,所以你不需要通過副本來提高讀取性能。同時,跟蹤數(shù)據(jù)本身的價值也而且隨著時間流失而降低。故你也不需要對數(shù)據(jù)做高可用處理。綜合以上原因,經(jīng)典的優(yōu)化方案都會關(guān)閉它的復(fù)制功能。
以上就是兩種現(xiàn)代混合方案。之所以稱為混合,就是當(dāng)代的跟蹤系統(tǒng),如Apache SkyWalking,Zipkin等等都支持多種存儲方案。用戶必須根據(jù)自己的情況進行選擇,且每個方案都各有利弊,而并沒有一個一勞永逸的一體化解決方案。
面向未來的一體化方案
至此我們探究了什么是分布式跟蹤系統(tǒng),經(jīng)典的跟蹤系統(tǒng)數(shù)據(jù)存儲的方案,以及現(xiàn)代這種混合的跟蹤系統(tǒng)存儲方案。我們會發(fā)現(xiàn)目前并沒有一個非常完美的最佳實踐來解決跟蹤系統(tǒng)的存儲問題。其主要原因就是并沒有一個專用的跟蹤系統(tǒng)存儲的引擎,來幫助我們?nèi)ネ瑫r解決那三個問題。
本文介紹的每種方案實際上只僅僅解決了部分的問題。傳統(tǒng)的經(jīng)典結(jié)構(gòu),貌似解決了所有的問題,但是其代價是非常高的。所以我們需要的一個最佳跟蹤系統(tǒng)存儲方案,除了典型的三個特點之外,還需要加上性價比這個非技術(shù)特性。只有高性價比的跟蹤系統(tǒng)方案才能在生產(chǎn)實踐中得到廣泛的使用。
除了性價比之外,另一個附加特性也就是自我運維。跟蹤系統(tǒng)本質(zhì)是一個運維工具,它的存儲系統(tǒng)如果需要運維人員花費更多的時間和精力來去管理和調(diào)優(yōu),那么必然會降低系統(tǒng)的使用率。因為專業(yè)的運維人員不希望特別關(guān)心工具自身的運維問題。但跟蹤系統(tǒng)本身會產(chǎn)生大量的數(shù)據(jù),造成它的維護難度并不亞于高流量的業(yè)務(wù)系統(tǒng)。所以一個典型的或完美的跟蹤系統(tǒng)存儲方案,要能夠去自動識別和處理常見的運維問題,其最低限度是,保證系統(tǒng)能以一定的健康度來運行,而不至于完全的掛掉。
所以我們寄望存在一個從底層開始設(shè)計的面相跟蹤場景的數(shù)據(jù)庫。它應(yīng)該從數(shù)據(jù)結(jié)構(gòu)層到模型層完全按照跟蹤系統(tǒng)的特點進行構(gòu)建的,并符合我們本文描述的此類數(shù)據(jù)庫的所有特點。很慶幸的是在我們這個時代有越來越多的獨立的底層引擎所涌現(xiàn)出來,我們可以利用它們?nèi)?gòu)建這么一個數(shù)據(jù)庫,而不需要完全從0開始。
同時由于RUM假說的出現(xiàn),我們可以采用不同的數(shù)據(jù)庫訪問策略來實現(xiàn)跟蹤這個特定領(lǐng)域的數(shù)據(jù)庫。而這樣一款兼?zhèn)涓鞣N跟蹤數(shù)據(jù)存儲所需要特點的數(shù)據(jù)庫其實也正在路上。
作者:
高洪濤——美國servicemesh服務(wù)商tetrate創(chuàng)始工程師。原華為軟件開發(fā)云技術(shù)專家,對云原生產(chǎn)品有豐富的設(shè)計,研發(fā)與實施經(jīng)驗。對分布式數(shù)據(jù)庫,容器調(diào)度,微服務(wù),ServicMesh等技術(shù)有深入的了解。前當(dāng)當(dāng)網(wǎng)系統(tǒng)架構(gòu)師,開源達人,曾參與Elastic-Job等知名開源項目。目前為Apache ShardingSphere和Apache SkyWalking核心貢獻者,參與該開源項目在軟件開發(fā)云的商業(yè)化進程。
























 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論