基于Spark框架與聚類優(yōu)化的高效KNN分類算法
大小:0.91 MB 人氣: 2017-12-08 需要積分:1
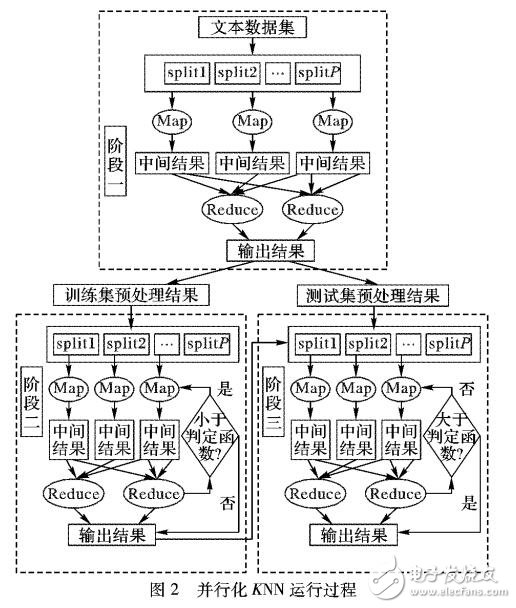
針對K-最近鄰(KNN)分類算法時間復雜度與訓練樣本數(shù)量成正比而導致的計算量大的問題以及當前大數(shù)據(jù)背景下面臨的傳統(tǒng)架構處理速度慢的問題,提出了一種基于Spark框架與聚類優(yōu)化的高效KNN分類算法。該算法首先利用引入收縮因子的優(yōu)化K-medoids聚類算法對訓練集進行兩次裁剪;然后在分類過程中迭代K值獲得分類結果,并在計算過程中結合Spark計算框架對數(shù)據(jù)進行分區(qū)迭代實現(xiàn)并行化。實驗結果表明,在不同數(shù)據(jù)集中傳統(tǒng)K最近鄰算法、基于K-medoids的K-最近鄰算法所耗費時間是所提Spark框架下的K-最近鄰算法的3.92 - 31. 90倍,所提算法具有較高的計算效率,相較于Hadoop平臺有較好的加速比,可有效地對大數(shù)據(jù)進行分類處理。
非常好我支持^.^
(0) 0%
不好我反對
(0) 0%
下載地址
基于Spark框架與聚類優(yōu)化的高效KNN分類算法下載
相關電子資料下載
- 天數(shù)智芯主導的DeepSpark開源社區(qū)發(fā)布百大應用開放平臺24.06版本 436
- spark運行的基本流程 91
- Spark基于DPU的Native引擎算子卸載方案 180
- 百度前高管景鯤與朱凱華創(chuàng)立AI搜索公司,Genspark產(chǎn)品驚艷上線 458
- 關于Spark的從0實現(xiàn)30s內(nèi)實時監(jiān)控指標計算 111
- “Spark+Hive”在DPU環(huán)境下的性能測評 | OLAP數(shù)據(jù)庫引擎選型白皮書(24版)DPU部分 212
- 芯科科技和Arduino合作創(chuàng)建SparkFun Thing Plus Matter板 234
- 應用于MEMS執(zhí)行器的8英寸硅晶圓上的KNN無鉛技術介紹 345
- Sparkle撼與科技發(fā)布TBX-750FA-V2顯卡塢,支持3.5槽厚顯 243
- 如何注冊星閃Sparklink設備媒體接入層標識、地址碼? 246