基于聚類和Spark框架的加權Slope One算法
大小:0.91 MB 人氣: 2017-12-03 需要積分:1
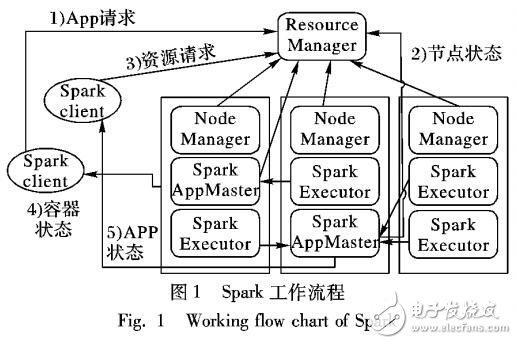
針對傳統Slope One算法在相似性計算時未考慮項目屬性信息和時間因素對項目相似性計算的影響,以及推薦在當前大數據背景下面臨的計算復雜度高、處理速度慢的問題,提出了一種基于聚類和Spark框架的加權Slope One算法。首先,將時間權重加入到傳統的項目評分相似性計算中,并引入項目屬性相似性生成項目綜合相似度;然后,結合Canopy-K-means聚類算法生成最近鄰居集;最后,利用Spark計算框架對數據進行分區迭代計算,實現該算法的并行化。實驗結果表明,基于Spark框架的改進算法與傳統Slope One算法、基于用戶相似性的加權Slope One算法相比,評分預測準確性更高,較Hadoop平臺下的運行效率平均可提高3.5 -5倍,更適合應用于大規模數據集的推薦。
非常好我支持^.^
(0) 0%
不好我反對
(0) 0%
下載地址
基于聚類和Spark框架的加權Slope One算法下載
相關電子資料下載
- 天數智芯主導的DeepSpark開源社區發布百大應用開放平臺24.06版本 436
- spark運行的基本流程 91
- Spark基于DPU的Native引擎算子卸載方案 180
- 百度前高管景鯤與朱凱華創立AI搜索公司,Genspark產品驚艷上線 458
- 關于Spark的從0實現30s內實時監控指標計算 111
- “Spark+Hive”在DPU環境下的性能測評 | OLAP數據庫引擎選型白皮書(24版)DPU部分 212
- 芯科科技和Arduino合作創建SparkFun Thing Plus Matter板 234
- Sparkle撼與科技發布TBX-750FA-V2顯卡塢,支持3.5槽厚顯 243
- 如何注冊星閃Sparklink設備媒體接入層標識、地址碼? 246
- 如何利用DPU加速Spark大數據處理? | 總結篇 661