墨跡使用ODPS的流程及日志分析
大小:0.11 MB 人氣: 2017-10-13 需要積分:1
標簽:odps(2519)
發帖量。墨跡天氣已經集成了多語言版本,可根據手機系統語言自動適配,用戶覆蓋包括中國大陸、港澳臺,日韓及東南亞、歐美等全球各地用戶。運營團隊每天最關心的是這些用戶正在如何使用墨跡,在他們操作中透露了哪些個性化需求。這些數據全部存儲在墨跡的API 日志中,對這些數據分析,就變成了運營團隊每天的最重要的工作。墨跡天氣的API每天產生的日志量大約在400GB左右,分析工具采用了阿里云的大數據計算服務ODPS。
使用ODPS的邏輯流程如下:
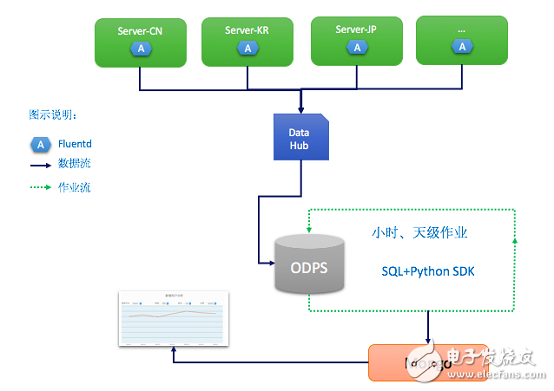
圖2 墨跡日志分析流程
流程介紹:
1.在每個日志服務器上都安裝了Fluentd及ODPS數據導入插件。日志數據通過流通道DataHub實時導入到ODPS;
2.數據分析作業分小時級和天級任務。數據開發工程師通過ODPS Python SDK向ODPS提交SQL 分析腳本,將統計后的數據導入Mongo DB。報表系統直接對接Mongo DB;
3.運營人員通過報表系統來查看用戶統計結果;
整個數據分析過程也做了很多優化。以下是幾點說明:
1.導入工具Fluentd。Fluentd是一款優秀的日志導入軟件。代碼開源,支持Apache License 2.0。Fluentd支持300多個插件,基本上今天的大數據處理系統,Fluentd都能支持。Fluentd還支持自定義插件,允許通過代碼編寫其它數據源和目標。使用配置簡單、靈活,底層引擎關鍵部分通過使用C語言類庫編寫,所以性能比較好。墨跡選擇了使用Fluentd向ODPS導入數據。
2.時區數據的統一。 墨跡的服務器部署在不同時區,日志數據按天和小時兩級分區流入到ODPS表中,但統計作業是發生在北京時間。例如,對于2015年12月1日的數據統計是在12月2日凌晨來做的。由于時區不同,統計作業運行完畢后,仍有部分時區在12月1日的數據會持續流入1日的分區表中,這就會導致這部分數據在統計時落掉。
解決這個問題,在實施時將所有的日志數據中的local時間按北京時間做了轉換,截止到北京時間12月1日結束時,所有數據流入1日的分區中。其它時區是1日的數據會流入2日的分區,數據會在第二天完成統計。Fluentd中Filter 插件可以完成這個轉換操作,配置非常簡單,如下面部分代碼:
type record_transformer enable_ruby Bjdatetime ${(Time.strptime(LocalDatetime,‘%m/%d-%H:%M:%S,%L’).gmtime+8*3600).strftime(‘%Y-%m-%d %H:%M:%S’)}
3. 任務的調度。墨跡分析的作業每天和每小時都會執行。分析后的數據導入本地Mongo DB,報表系統接入Mongo DB來做展現。墨跡分析工程師在本地使用定時調度Python腳本完成這些流程。SQL 分析腳本可以通過ODPS Python SDK直接提交到ODPS上執行完,完成后將統計結果放到List 對象。通過Python Mongo Client 將List寫入Mongo DB。
墨跡天氣的這一流程之前是在國外某云計算平臺上完成的,需要分別使用云存儲、大數據分析等服務,數據分析完成后再同步到本地Mongo DB中與報表系統對接。在遷移到ODPS后,流程上做了優化,EMR的工作省掉了,日志數據導入到ODPS表后,通過SQL進行分析,完成后直接將結果寫入本地Mongo DB。
在存儲方面,ODPS中的表按列壓縮存儲,更節省存儲空間,整體上存儲和計算的費用比之前省了70%,性能和穩定性也提高了很多。同時墨跡可以借助ODPS上的機器學習算法,對數據進行深度挖掘,為用戶提供個性化的天氣服務。
?
非常好我支持^.^
(0) 0%
不好我反對
(0) 0%