基于知識圖譜的QA系統研究
大小:0.6 MB 人氣: 2017-10-10 需要積分:1
QA系統依據其回答語料可以分為兩類,一類是常見的純文本形式,如網絡文檔、問答社區內容、搜索引擎結果、百科數據等。另一類則是知識圖譜,通常以RDF三元組的形式結構化表示。由于結構化的特點,QA系統相比純文本語料,往往可以提供更加精確和簡練的結果。另一方面,近些年涌現出了大批十億甚至更大規模的知識圖譜,包括WolframAlpha、Google Knowledge Graph、Freebase等。這些知識圖譜的出現保證基于其的問答系統的覆蓋率。所以,當前基于知識圖譜的開放領域QA系統是可行的。
系統架構
QA系統分為三層架構模型,分別為實體、語言和應用層,如下圖所示。
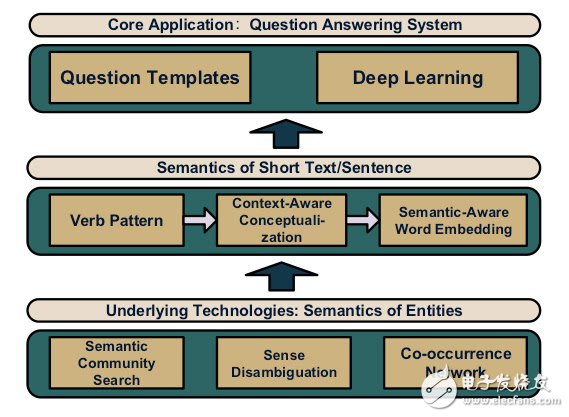
其中最下層為實體層,其為上層模型提供最基礎的計算單元,包括了語義社區搜索、語義消歧義和同現網絡模塊;中間層為語言層,作為連接實體層和應用層的橋梁,其包含了具有一定語義信息的短文本;最上層則為集成的QA系統,包括了問題模板和深度學習模塊。
實體層模型研究
語義社區搜索
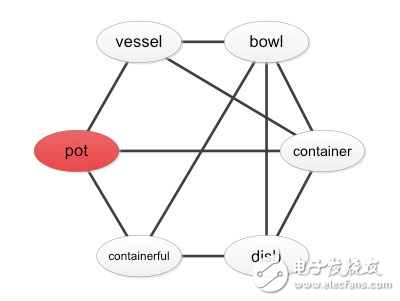
如上圖所示,節點即代表單詞在語義社區網絡中的語義,邊則為單詞與單詞之間的關系,以此模型即可找到一個單詞所在的社區,以及單詞之間的相似度,如下圖所示pot和bowl為同一語義社區,有很高的相似度;pot和plate為不同的語義社區,其中兩個有兩個單詞交集,為中等相似度;pot和tube為不同的語義社區,其中只有一個單詞交集,為低等相似度
非常好我支持^.^
(0) 0%
不好我反對
(0) 0%