如何使用Apache Spark中的DataSource API以實現數據源混合計算的實踐
本文主要介紹如何使用Apache Spark中的DataSource API以實現多個數據源混合計算的實踐,那么這么做的意義何在,其主要歸結于3個方面:
首先,我們身邊存在大量的數據,結構化、非結構化,各種各樣的數據結構、格局格式,這種數據的多樣性本身即是大數據的特性之一,從而也決定了一種存儲方式不可能通吃所有。因此,數據本身決定了多種數據源存在的必然性。 其次:從業務需求來看,因為每天會開發各種各樣的應用系統,應用系統中所遇到的業務場景是互不相同的,各種各樣的需求決定了目前市面上不可能有一種軟件架構同時能夠解決這么多種業務場景,所以在數據存儲包括數據查詢、計算這一塊也不可能只有一種技術就能解決所有問題。最后,從軟件的發展來看,現在市面上出現了越來越多面對某一個細分領域的軟件技術,比如像數據存儲、查詢搜索引擎,MPP數據庫,以及各種各樣的查詢引擎。這么多不同的軟件中,每一個軟件都相對擅長處理某一個領域的業務場景,只是涉及的領域大小不相同。因此,越來越多軟件的產生也決定了我們所接受的數據會存儲到越來越多不同的數據源。
Apache Spark的多數據源方案
傳統方案中,實現多數據源通常有兩種方案:冗余存儲,一份業務數據有多個存儲,或者內部互相引用;集中的計算,不同的數據使用不同存儲,但是會在統一的地方集中計算,算的時候把這些數據從不同位置讀取出來。下面一起討論這兩種解決方案中存在的問題:
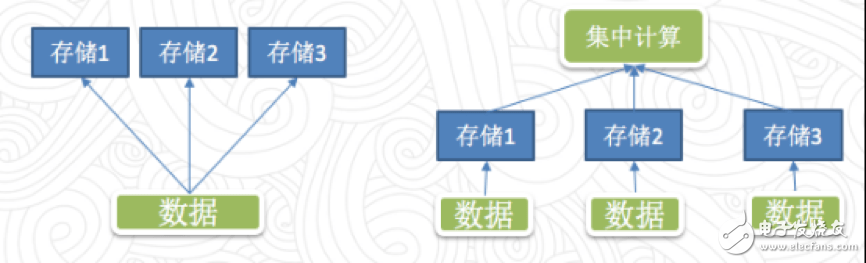
圖1 多數據源方案
第一種方案中存在的一個問題是數據一致性,一樣的數據放在不同的存儲里面或多或少會有格式上的不兼容,或者查詢的差異,從而導致從不同位置查詢的數據可能出現不一致。比如有兩個報表相同的指標,但是因為是放在不同存儲里查出來的結果對不上,這點非常致命。第二個問題是存儲的成本,隨著存儲成本越來越低,這點倒是容易解決。
第二種方案也存在兩個問題,其一是不同存儲出來的數據類型不同,從而在計算時需求相互轉換,因此如何轉換至關重要。第二個問題是讀取效率,需要高性能的數據抽取機制,盡量避免從遠端讀取不必要的數據,并且需要保證一定的并發性。
Spark在1.2.0版本首次發布了一個新的DataSourceAPI,這個API提供了非常靈活的方案,讓Spark可以通過一個標準的接口訪問各種外部數據源,目標是讓Spark各個組件以非常方便的通過SparkSQL訪問外部數據源。很顯然,Spark的DataSourceAPI其采用的是方案二,那么它是如何解決其中那個的問題的呢?
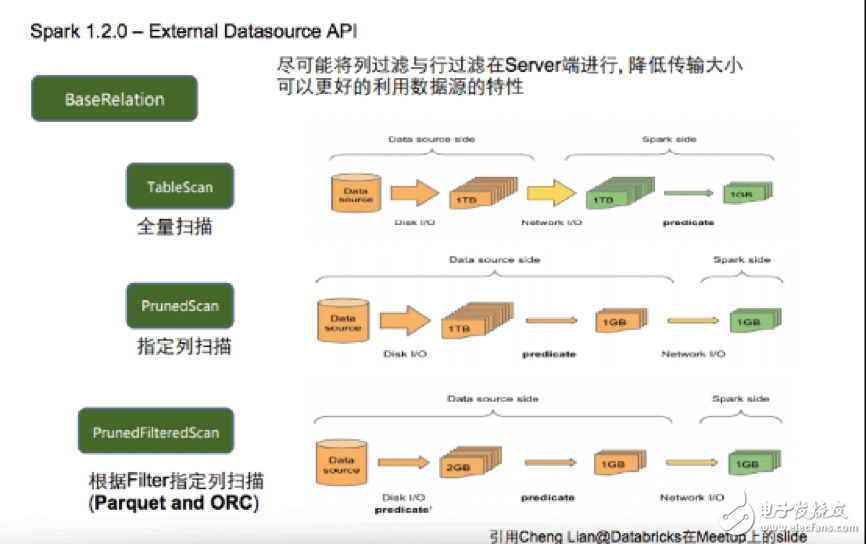
圖2 External Datasource API
首先,數據類型轉換,Spark中定義了一個統一的數據類型標準,不同的數據源自己定義數據類型的轉換方法,這樣解決數據源之間相互類型轉換的問題;
關于數據處理效率的問題,Spark定義了一個比較簡單的API的接口,主要有3個方式:
1./* 全量數據抽取 */
3.def buildScan(): RDD[Row]
4.}
5.
6./* 列剪枝數據抽取 */
7.trait PrunedScan {
8.def buildScan(requiredColumns: Array[String]): RDD[Row]
9.}
10.
11./* 列剪枝+行過濾數據抽取 */
12.trait PrunedFilteredScan {
13.def buildScan(requiredColumns: Array[String], filters: Array[Filter]): RDD[Row]
14.}
TableScan。這種方式需要將1TB的數據從數據抽取,再把這些數據傳到Spark中。在把這1TB的數據穿過網絡IO傳給Spark端之后,Spark還要逐行的進行過濾,從而消耗大量的計算資源,這是目前最低效的方式。
PrunedScan。這個方式有一個好處是數據源只需要從磁盤讀取1TB的數據,并只返回一些列的數據,Spark不需要計算就可以使用1GB的數據,這個過程中節省了大量的網絡IO。
PrunedFilteredScan。它需要數據源既支持列過濾也支持行過濾,其好處是在磁盤IO這一層進行數據過濾,因此如果需要1GB數據,可能只抽出2GB大小,經過列過濾的規則再抽出1GB的數據,隨后傳給Spark,因此這種數據源接口最高效,這也是目前市面上實現的最高效的數據接口。
可直接使用的DataSource實現
目前市面上可以找到的Spark DataSource實現代碼有三大類:Spark自帶;Spark Packages(http://Spark-packages.org/)網站中存放的第三方軟件包;跟隨其他項目一同發布的內置的Spark的實現。這里介紹其中幾個:
1.JDBCRelation
1.private[sql] case class JDBCRelation(
2.url: String,
3.table: String,
4.parts: Array[Partition],
5.properties: Properties = new Properties())(@transient val sqlContext: SQLContext)
6.extends BaseRelation
7.with PrunedFilteredScan
8.with InsertableRelation {
9…。
10.}
以JDBC方式連接外部數據源在國內十分流行,Spark也內置了最高效的PrunedFilteredScan接口,同時還實現了數據插入的接口,使用起來非常方便,可以方便地把數據庫中的表用到Spark。以Postgres為例:
1.sqlContext.read.jdbc(
2.“jdbc:postgresql://testhost:7531/testdb”,
3.“testTable”,
4.“idField”, ——-索引列
5.10000, ——-起始index
6.1000000, ——-結束index
7.10, ——-partition數量
8.new Properties
9.).registerTempTable(“testTable”)
實現機制:默認使用單個Task從遠端數據庫讀取數據,如果設定了partitionColumn、lowerBound、upperBound、numPartitions這4個參數,那么還可以控制Spark把針對這個數據源的訪問任務進行拆分,得到numPartitions個任務,每個Executor收到任務之后會并發的去連接數據庫的Server讀取數據。
具體類型:PostgreSQL, MySQL。
問題:在實際使用中需要注意一個問題,所有的Spark都會并發連接一個Server,并發過高時可能會對數據庫造成較大的沖擊(對于MPP等新型的關系型數據庫還好)。
建議:個人感覺,JDBC的數據源適合從MPP等分布式數據庫中讀取數據,對于傳統意義上單機的數據庫建議只處理一些相對較小的數據。
2.HadoopFsRelation
第二個在Spark內置的數據源實現,HadoopFs,也是實現中最高效的PrunedFilteredScan接口,使用起來相對來說比JDBC更方便。
1.sqlContext
2..read
3..parquet(“hdfs://testFS/testPath”)
4..registerTempTable(“test”)
實現機制:執行的時候Spark在Driver端會直接獲取列表,根據文件的格式類型和壓縮方式生成多個TASK,再把這些TASK分配下去。Executor端會根據文件列表訪問,這種方式訪問HDFS不會出現IO集中的地方,所以具備很好的擴展性,可以處理相當大規模的數據。
具體類型:ORC,Parquet,JSon。
問題:在實時場景下如果使用HDFS作為數據輸出的數據源,在寫數據就會產生非常大量零散的數據,在HDFS上積累大量的零碎文件,就會帶來很大的壓力,后續處理這些小文件的時候也非常頭疼。
建議:這種方式適合離線數據處理程序輸入和輸出數據,還有一些數據處理Pipeline中的臨時數據,數據量比較大,可以臨時放在HDFS。實時場景下不推薦使用HDFS作為數據輸出。
3.ElasticSearch
越來越多的互聯網公司開始使用ELK(ElasticSearch+LogStash+Kibana)作為基礎數據分析查詢的工具,但是有多少人知道其實ElasticSearch也支持在Spark中掛載為一個DataSource進行查詢呢?
1.EsSparkSQL
2..esDF(hc,indexName,esQuery)
3..registerTempTable(”testTable”)
實現機制:ES DataSource的實現機制是通過對esQuery進行解析,將實際要發往多個ES Nodes的請求分為多個Task,在每個Executor上并行執行。
非常好我支持^.^
(0) 0%
不好我反對
(0) 0%
下載地址
如何使用Apache Spark中的DataSource API以實現數據源混合計算的實踐下載
相關電子資料下載
- DeepSpark 開源社區百大應用開放平臺23.09版本正式發布 51
- RT-Thread SPARK CAN的通信內核詳解 334
- Spark Connected與英飛凌面向市場推出Yeti 的500 W無線充電解決方案 315
- NVIDIA 攜手騰訊開發和優化 Spark UCX 實現性能躍升 224
- 基于RT-SPARK 1的物聯網-溫濕度報警器設計方案 239
- 一種基于STM32F407-RT-SPARK開發板的智能花盆設計案例 1297
- ?DeepSpark 開源社區百大應用開放平臺23.06版本正式發布 212
- 傳音移動互聯DataSparkle為非洲數字經濟研究提供數據支撐 141
- 為Spark ML算法提供GPU加速度 337
- Spark 3.4用于分布式模型訓練和大規模模型推理 349