微博基于Spark的機器學習應用分析
眾所周知,自2015年以來微博的業務發展迅猛。如果根據內容來劃分,微博的業務有主信息(Feed)流、熱門微博、微博推送(Push)、反垃圾、微博分發控制等。每個業務都有自己不同的用戶構成、業務關注點和數據特征。龐大的用戶基數下,由用戶相互關注衍生的用戶間關系,以及用戶千人千面的個性化需求,要求我們用更高、更大規模的維度去刻畫和描繪用戶。大體量的微博內容,也呈現出多樣化、多媒體化的發展趨勢。
一直以來,微博都嘗試通過機器學習來解決業務場景中遇到的各種挑戰。本文為新浪微博吳磊在CCTC 2017云計算大會Spark峰會所做分享《基于Spark的大規模機器學習在微博的應用》主題的一部分,介紹微博在面對大規模機器學習的挑戰時,采取的最佳實踐和解決方案。
Spark Mllib
針對微博近百億特征維度、近萬億樣本量的模型訓練需求,我們首先嘗試了Apache Spark原生實現的邏輯回歸算法。采用該方式的優點顯而易見,即開發周期短、試錯成本低。我們將不同來源的特征(用戶、微博內容、用戶間關系、使用環境等)根據業務需要進行數據清洗、提取、離散化,生成Libsvm格式的可訓練樣本集,再將樣本喂給LR算法進行訓練。在維度升高的過程中,我們遇到了不同方面的問題,并通過實踐提供了解決辦法。
Stack overflow
棧溢出的問題在函數嵌套調用中非常普遍,但在我們的實踐中發現,過多Spark RDD的union操作,同樣會導致棧溢出的問題。解決辦法自然是避免大量的RDD union,轉而采用其他的實現方式。
AUC=0.5
在進行模型訓練的過程中,曾出現測試集AUC一直停留在0.5的尷尬局面。通過仔細查看訓練參數,發現當LR的學習率設置較大時,梯度下降會在局部最優左右搖擺,造成訓練出來的模型成本偏高,擬合性差。通過適當調整學習率可以避免該問題的出現。
整型越界
整型越界通常是指給定的數據值過大,超出了整形(32bit Int)的上限。但在我們的場景中,導致整型越界的并不是某個具體數據值的大小,而是因為訓練樣本數據量過大、HDFS的分片過大,導致Spark RDD的單個分片內的數據記錄條數超出了整型上限,進而導致越界。Spark RDD中的迭代器以整數(Int)來記錄Iterator的位置,當記錄數超過32位整型所包含的范圍(2147483647),就會報出該錯誤。
解決辦法是在Spark加載HDFS中的HadoopRDD時,設置分區數,將分區數設置足夠大,從而保證每個分片的數據量足夠小,以避免該問題。可以通過公式(總記錄數/單個分片記錄數)來計算合理的分區數。
Shuffle fetch failed
在分布式計算中,Shuffle階段不可避免,在Shuffle的Map階段,Spark會將Map輸出緩存到本機的本地文件系統。當Map輸出的數據較大,且本地文件系統存儲空間不足時,會導致Shuffle中間文件的丟失,這是Shuffle fetch failed錯誤的常見原因。但在我們的場景中,我們手工設置了spark.local.dir配置項,將其指向存儲空間足夠、I/O效率較高的文件系統中,但還是碰到了該問題。
通過仔細查對日志和Spark UI的記錄,發現有個別Executor因任務過重、GC時間過長,丟失了與Driver的心跳。Driver感知不到這些Executor的心跳,便主動要求Yarn的Application master將包含這些Executor的Container殺掉。
皮之不存、毛之焉附,Executor被殺掉了,存儲在其中的Map輸出信息自然也就丟了,造成在Reduce階段,Reducer無法獲得屬于自己的那份Map輸出。解決辦法是合理地設置JVM的GC設置,或者通過將spark.network.timeout的時間(默認60s)設置為120s,該時間為Driver與Executor心跳通信的超時時間,給Executor足夠的響應時間,讓其不必因處理任務過重而無暇與Driver端通信。
通過各種優化,我們將模型的維度提升至千萬維。當模型維度沖擊到億維時,因Spark Mllib LR的實現為非模型并行,過高的模型維度會導致海森矩陣呈指數級上漲,導致內存和網絡I/O的極大開銷。因此我們不得不嘗試其他的解決方案。
基于Spark的參數服務器
在經過大量調研和初步的嘗試,我們最終選擇參數服務器方案來解決模型并行問題。參數服務器通過將參數分片以分布式形式存儲和訪問,將高維模型平均分配到參數服務器集群中的每一臺機器,將CPU計算、內存消耗、存儲、磁盤I/O、網絡I/O等負載和開銷均攤。典型的參數服務器采用主從架構,Master負責記錄和維護每個參數服務器的心跳和狀態;參數服務器則負責參數分片的存儲、梯度計算、梯度更新、副本存儲等具體工作。圖1是我們采用的參數服務器方案。
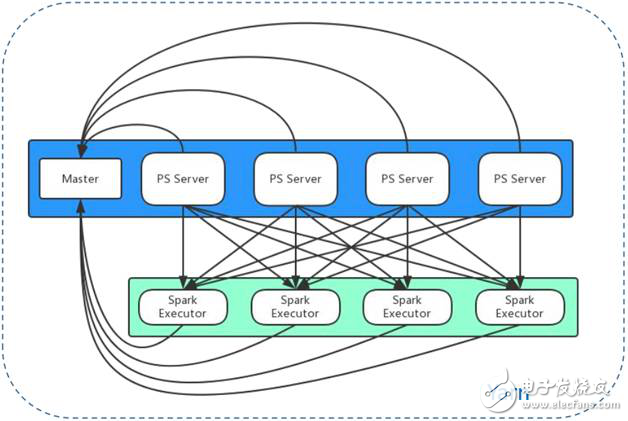
圖1 微博參數服務器架構圖
藍色文本框架即是采用主從架構的參數服務器集群,以Yarn應用的方式部署在Yarn集群中,為所有應用提供服務。在參數服務器的客戶端,也是通過Yarn應用的方式,啟動Spark任務執行LR分布式算法。在圖中綠色文本框中,Spark模型訓練以獨立的應用存在于Yarn集群中。在模型訓練過程中,每個Spark Executor以數據分片為單位,進行參數的拉取、計算、更新和推送。
在參數服務器實現方面,業界至少有兩種實現方式,即全同步與全異步。全同步的方式能夠在理論層面保證模型收斂,但在分布式環境中,鑒于各計算節點的執行性能各異,加上迭代中需要彼此間相互同步,容易導致過早執行完任務的節點等待計算任務繁重的節點,引入通信邊界,從而造成計算資料的浪費和開銷。全異步方式能夠很好地避免這些問題,因節點間無需等待和同步,可以充分利用各個節點的計算資源。雖然從理論上無法驗證模型一定收斂,但是通過實踐發現,模型每次的迭代速度會更快,AUC的加速度會更高,實際訓練出的模型效果可以滿足業務和線上的要求。
在通過參數服務器進行LR模型訓練時,我們總結了影響執行性能的關鍵因素,羅列如下:
Batch size
即Spark數據分片大小。前文提到,每個Spark Executor以數據分片為單位,進行參數的拉取和推送。分片的大小直接決定本次迭代需要拉取和通信的參數數量,而參數數量直接決定了本地迭代的計算量、通信量。因此分片大小是影響模型訓練執行性能的首要因素。過大的數據分片會造成單次迭代任務過重,Executor不堪重負;過小的分片雖然能夠充分利用網絡吞吐,但是會造成很多額外的開銷。因此,選擇合理的Batch size,將會令執行性能的提升事半功倍。下文將以Batch size為例,對比不同設置下模型訓練執行性能的差異。
PS server數量
參數服務器的數量,決定了模型參數的存儲容量。通過擴展參數服務器集群,理論上可以無限擴展存儲容量。但是當集群大小達到瓶頸值時,過多的參數服務器帶來的網絡開銷反而會令整體執行性能趨于平緩甚至下降。
特征稀疏度
根據需要可以將原始業務特征(用戶、微博內容、用戶間關系、使用環境等)通過映射函數映射到高維模型,以這種方式提煉出區分度更佳的特征。特征稀疏度結合每次迭代數據分片的數據分布,決定了該分片本次迭代需要拉取和推送的參數數量,進而決定了本次迭代所需的計算資源和網絡開銷。
PS分區策略
分區策略決定了模型參數在參數服務器的分布,好的分區策略能夠使模型參數的分布更均勻,從而均攤每個節點的計算和通信負載。
Spark內存規劃
在PS的客戶端,Spark Executor需要保證有足夠的內存容納本次迭代分片所需的參數向量,才能完成后續的參數計算、更新任務。
下表為不同的Batch size下,各執行性能指標對比。Parameter(MB)表示一次迭代所需參數個數;Tx(MB)表示一次迭代的網絡吞吐;Pull(ms)和Push(ms)分別表示一次迭代的拉取和推送時間消耗;Time(s)為一次迭代的整體執行時間。從表1中可見,參數個數與分片大小成正比、網絡吞吐與分片大小成反比。分片越小,需要通信、處理的參數越少,但PS客戶端與PS服務器通信更加頻繁,因而網絡吞吐更高。但是當分片過小時,會產生額外的開銷,造成參數拉取、推送的平均耗時和任務的整體耗時上升。
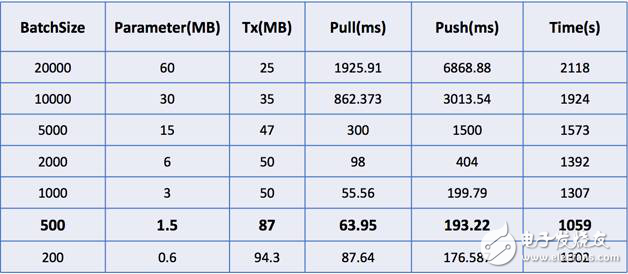
表1 模型訓練執行性能指標在不同Batch size下的對比
通過參數服務器的解決方案,我們解決了微博機器學習平臺化進程中的大規模模型訓練問題。眾所周知,在機器學習流中,模型訓練只是其中耗時最短的一環。如果把機器學習流比作烹飪,那么模型訓練就是最后翻炒的過程,烹飪的大部分時間實際上都花在了食材、佐料的挑選,洗菜、擇菜,食材再加工(切丁、切塊、過油、預熱)等步驟。
在微博的機器學習流中,原始樣本生成、數據處理、特征工程、訓練樣本生成、模型后期的測試、評估等步驟所需要投入的時間和精力,占據了整個流程的80%之多。如何能夠高效地端到端進行機器學習流的開發,如何能夠根據線上的反饋及時地選取高區分度特征,對模型進行優化,驗證模型的有效性,加速模型迭代效率,滿足線上的要求,都是我們需要解決的問題。在新一期《程序員》“weiflow——微博機器學習流統一計算框架”一文中,我們將為你一一解答。
非常好我支持^.^
(0) 0%
不好我反對
(0) 0%