 電子發燒友App
電子發燒友App


3月29日,ABT Network(ABT 鏈網)正式發布。ABT Network以完全去中心化方式連接編織多條區塊鏈形成的網絡,以云節點和織鏈為網的方式重新定義了新一代區塊鏈基礎架構。本文談談 ABT Network 誕生前發生的有趣經歷。
為方便閱讀,先簡單介紹一下本文談到的一些概念:
· ABT Network:多條使用 ArcBlock 技術打造的區塊鏈形成的網路。
· ABT Chain Node:ArcBlock 使用 Forge Framework 打造的區塊鏈節點軟件。
· Forge Framework:ArcBlock 為區塊鏈開發打造的框架,可以看做區塊鏈世界里的 Ruby on Rails。
打造人人都可部署的節點
在開發 Forge Framework 和 ABT Chain Node 時,我們有一個深深的信念:運行在 Forge 之上的區塊鏈項目可以是陽春白雪,也可以是下里巴人;可以是每日千百萬級 transaction 的大型應用,也可以是獨立開發者及其小圈子的自娛自樂。因而,一個節點只要有過得去的算力,就可以運行 Forge,這樣,只要愿意,人人都可以部署自己可負擔的節點。
那什么算是「過得去的算力」呢?考慮到 App 開發者的開發期的經濟能力,我們將其定位在單節點月支出在 $15 以內,在 Digital Ocean 上,這對應:

也就是 1GB / 1CPU / 25GB disk 一路到 2GB / 2CPU / 60GB disk 的乞丐版云主機。
在今年一二月份的大部分開發時間里,我們都在使用 $5 的至尊乞丐版主機 —— 而且,我們一口氣在美西 (SF),美東 (NY),西歐 (London) 和東南亞 (Singapore) 部署了四個節點,組成一個 P2P 網絡,來開發 Forge。我們相信,極端惡劣的環境,能打造盡可能健壯的軟件,讓各種問題都提前暴露出來。
有了環境,我們需要有足夠模擬真實應用場景的流量。為此我們開發了一個 simulator(模擬器),并且做了一個簡單的描述語言來描述我們如何開啟 simulation(節選):
pools:
create_asset: 5
declare: 5
exchange: 5
transfer: 10
update_asset: 5
consume_asset: 5
poke: 5
meta:
tick: 500
simulations:
- name: exchange token and assets
interval: 2
num: 2
type: exchange
settings:
value: “1000..20000”
- name: transfer token and assets
interval: 5
num: 2
type: transfer
settings:
value: “1000..5000”
after:
- interval: 1
action: consume_asset
通過改變 pool size,我們可以調節并發程度,通過控制 tick,我們控制 traffic 的速率;通過添加更多的 simulation,我們改變 traffic 的多樣性。
在 simulator 的作用下,很長一段時間里,我們的開發網絡三天兩頭 crash(崩潰) —— 一會 out of memory,一會 too many open files,一會 gen_server tiemout,一會 tcp send/receive buffer full。這些問題,如果換上個 4G memory / 4 CPU / 100G disk 的主機,只有很小的概率才暴露出來,而我們主動讓其發生在開發環境中,使得大部分問題得到了妥善處理。比如說,我們發現我們使用的 consensus engine(共識引擎) 不穩定,時不時 crash,crash 之后很容易把 state db(狀態數據庫) 寫壞,使得節點徹底崩潰,無法恢復。對此,我們的做法是,一旦 consensus engine crash,我們讓 Forge 自動 crash(可惜了 erlang VM 強大的 crash recover 機制),然后由我們開發的 forge starter 將 forge 重啟。重啟后,我們回溯到上一個區塊的數據,重新 apply,如果 consensus engine 可以恢復,那么舊繼續往后走;否則便繼續 crash 和繼續回溯。
在這樣嚴苛的環境下 Forge 逐漸成長,至尊乞丐節點組成的網絡,不斷死亡,不斷重生,就像「明日邊緣」里的湯姆克魯斯,從小白一路成長為小強,迎來了第一百萬個 transaction。
好景不長,在大約 1.5M txs 時,網絡再次 crash:
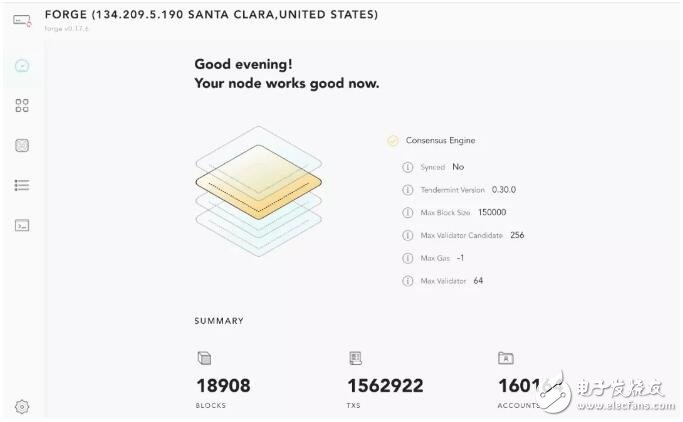
這次 crash 的一干二凈,所有節點全軍覆沒,連 ssh 都上不去。Digital Ocean 的監控顯示 CPU 基本為 0,正琢磨著是不是 disk 寫滿了,一臺機器回光返照,給我登上去 du 的機會。果然,25G 的 disk 被吃得一干二凈。take snapshot,換大硬盤,搞定。
三月上旬我們終于拋棄了 $5 的機器,換裝 $15 的「大」節點。在 Digital Ocean 的云上,我們同時跑了好幾個網絡,做 rolling upgrade。之前我們一周一個 milestone,出一個大版本,若干小版本,三月第二周起,我們每天出一個版本,因而,版本太多而網絡不夠用了。。。
很快,1 million txs 的里程碑被 5 million 取代:
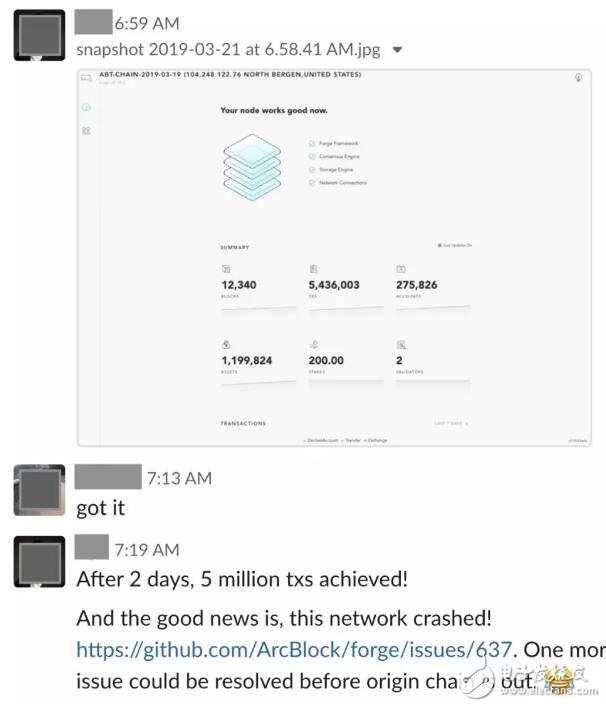
繼而被 6M,7M,… 取代。后來我們 breaking change 太多,也就沒有繼續累積這個數字。
可以讓區塊鏈節點穩定地在 $15 的機器上部署是我們 ArcBlock 的一個創舉。我們做過別的公鏈的節點 —— 對方給出的推薦配置,一個節點一個月要一千多美金。如果一個應用開發者開發者,想部署一個自己的鏈,初期通過自己的節點來服務其用戶,假設節點部署在全球四個區域:每個區域兩個節點,那單單是這樣一筆開銷,就超過上萬美金每月 —— 沒有充沛現金的小玩家,是燒不起這個錢的。所以我們希望這個數字能夠低至幾百。
然而 Digital Ocean 畢竟是服務于小客戶的,一個嚴肅的 dApp,在開發階段使用 DO 無可厚非,在生產環境 —— 當鏈上線之后,更具實力的云服務是更好的選擇,比如我們自己的 ABT network 就部署在 aws。
簡約而不簡單的生產環境
由于 ABT network 強調織鏈為網,我們首發三條以化學元素「氬(Argon)」「溴(Bromine)」「鈦(Titanium)」命名的元素鏈(其中 Bromine 是一條專門運行最新 nightly build 版本的測試鏈)。因而我們需要為這三條鏈準備安全可信的生產環境。
我們是這樣考慮線上的生產環境的:
1. 每條鏈都部署到亞太歐美四個區域;
2. Argon 和 Titanium 各十六個節點;Bromine 四個節點
3. 所有節點都只對外暴露 p2p 端口;
4. 節點的 GraphQL RPC 和自帶的區塊瀏覽器通過 ELB 允許外部訪問,而 gRPC 只允許本地訪問;
5. 每個 region,每條鏈的 ELB 的域名,由 route 53 按照 latency 來 load balancing。
最重要的,要自動化,要足夠省錢。
自動化,這個不消說,我們已經有深厚的 ansible / terraform 經驗。
省錢是個學問。
按照上面的配置,哪怕只用物美價廉的 c4.large / c5.large,每個節點配 110G EBS,每條鏈每個區域都配一個 ELB,一個月下來光固定成本就要 $3721。
計算公式: 0.11 (c4.large 價格) x 36 x 24 x 31 + 36 x 110 x 0.12 (EBS 價格) + 25 (ELB 價格) x 12
這其中,EC2 占了大頭,接近 $3000。
我們的目標,是盡可能降低這個成本。
于是我們的目光投向了 spot instance。下圖是 spot instance 在 us-east-2 和 ap-southeast-1 的價格走勢:
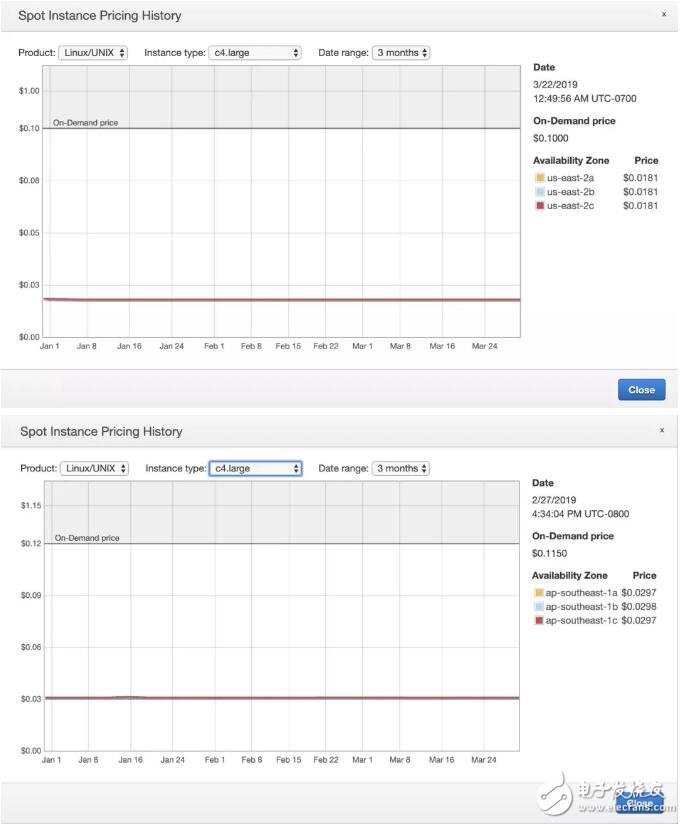
價格基本穩定在 on-demand instance 的 2 折,也就意味著 EC2 這塊,我們可以把成本降到 $600,總價只需 $1300 每月。
然而用 spot instance,繞不過去的坎就是萬一 instance 被殺掉,如何盡快恢復服務?尤其是驗證人節點?
我們采用的方式是 root disk 和 data disk 分離,Forge 存儲的所有數據放 data disk,而 Forge 的配置,節點私鑰,驗證人私鑰,放 root disk,然后在初始化之后備份到一個 AES 加密的,只允許單次寫的 S3 bucket 中。之后,在節點運行的時候,每條鏈每個區域定期備份某一個健康節點的 data disk。這樣,當驗證人節點被殺掉時,我們可以從最近的一個備份中恢復 data disk,然后從 S3 中找回該驗證人節點的私鑰和配置。
這個思路說起來挺簡單直觀,做起來可要頗費一番心思的。不過最終我們趟平了這條路,證明了它是可行的,對 dApp 開發者,甚至其他區塊鏈的同行,這種使用 spot instance 運行區塊鏈節點的方式都有借鑒意義。
最終我們的部署腳本 forge-deploy 分成四部分:
1. 只需要一次性運行的腳本:比如為每個區域每個 VPC 創建 security group
2. 制作 Forge AMI 的腳本:我們每 release 一個新的版本,都會創建一個新的 AMI。
3. 創建一條新鏈所需要的資源的腳本:比如創建 spot request,EBS,創建 ELB,target group,設置 listener (及 listener rules),創建域名及域名解析的 policy。
4. 管理一條已有鏈的腳本:比如初始化鏈,重啟節點,升級節點,修復損壞的節點,添加新的節點等
三月的最后兩周,forge-deploy 在原有零散腳本(部署 DO 機器的腳本)的基礎上邊開發邊測試 —— 我們的鏈建了拆,拆了建,兩周趟過了很多區塊鏈團隊可能一年都沒有趟過的路:最多的時候我們有 6 條鏈并行運行,算上那些朝生暮死的 abtchain,origin,bigbang,test,abc 等鏈,我們前前后后創建了和銷毀了三十多條鏈 —— 注意,這里說的是多區域多節點的鏈,單個節點的鏈并不包含在內。
由于之前累積了足夠的自信,在 ABT Network 上線的那一天,我們自負地把之前為發布已經創建好的三條鏈:Argon,Bromine 和 Titanium 在上線倒計時前不到半小時拆掉重新發布,讓整個團隊和社區關心我們的人可以看到區塊從零到一的躍遷。雖然中間有點波折 —— 部署腳本運行得比預想要慢一些 —— 因而在發布倒計時結束后我們還沒有部署完成,但最終,耽擱了大約二十分鐘,三條鏈還是如愿上線。每條鏈的部署只需要兩條命令:

其中,create_fleet 會在四個區域里都做這些事情:
1. 獲取當前區域的 default VPC id
2. 獲取 VPC 的 subnet id
3. 獲取預先創建好的幾個 security group 的 id
4. 用預設的配置為驗證人節點申請 spot fleet
5. 用預設的配置為哨兵節點申請 spot fleet
6. 等待所有申請好的 instance 可以正常工作
7. 創建 ELB
8. 創建 target group,并將所有 instance 加入 target group
9. 獲取預先上傳好的證書 id
10. 創建兩個 ELB listener,80 端口直接 301 到 443,而 443 端口把流量轉發到 target group
11. 創建 DNS 域名記錄,設置 latency based policy
當四個區域都完成之后,為這條鏈的所有 instance 創建 ansible inventory,以便后續處理。
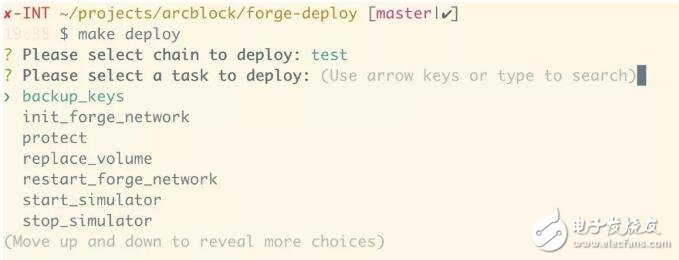
接下來,在 init_forge_network 里,會做這些事情:
1. 把 data disk mount 到對應的 instance 上,并格式化文件系統為 XFS
2. 使用臨時配置文件啟動 Forge,生成 node key 和 validator key
3. 把生成的 key 備份到 S3
4. 根據 inventory file,找出驗證人節點,將其 validator address 寫入 genesis 配置中
5. 啟動 forge
所有節點起來后,稍候片刻,一條鏈就完美誕生了!













 工商網監
工商網監
評論